 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedCollab: Causal-Driven Multi-Agent Collaboration for Full-Cycle Clinical Diagnosis via IBIS-Structured Argumentation
Mar 01, 2026Large language models (LLMs) have shown promise in healthcare applications, however, their use in clinical practice is still limited by diagnostic hallucinations and insufficiently interpretable reasoning. We present MedCollab, a novel multi-agent framework that emulates the hierarchical consultation workflow of modern hospitals to autonomously navigate the full-cycle diagnostic process. The framework incorporates a dynamic specialist recruitment mechanism that adaptively assembles clinical and examination agents according to patient-specific symptoms and examination results. To ensure the rigor of clinical work, we adopt a structured Issue-Based Information System (IBIS) argumentation protocol that requires agents to provide ``Positions'' backed by traceable evidence from medical knowledge and clinical data. Furthermore, the framework constructs a Hierarchical Disease Causal Chain that transforms flattened diagnostic predictions into a structured model of pathological progression through explicit logical operators. A multi-round Consensus Mechanism iteratively filters low-quality reasoning through logic auditing and weighted voting. Evaluated on real-world clinical datasets, MedCollab significantly outperforms pure LLMs and medical multi-agent systems in Accuracy and RaTEScore, demonstrating a marked reduction in medical hallucinations. These findings indicate that MedCollab provides an extensible, transparent, and clinically compliant approach to medical decision-making.
OrthoGeoLoRA: Geometric Parameter-Efficient Fine-Tuning for Structured Social Science Concept Retrieval on theWeb
Jan 14, 2026Large language models and text encoders increasingly power web-based information systems in the social sciences, including digital libraries, data catalogues, and search interfaces used by researchers, policymakers, and civil society. Full fine-tuning is often computationally and energy intensive, which can be prohibitive for smaller institutions and non-profit organizations in the Web4Good ecosystem. Parameter-Efficient Fine-Tuning (PEFT), especially Low-Rank Adaptation (LoRA), reduces this cost by updating only a small number of parameters. We show that the standard LoRA update $ΔW = BA^\top$ has geometric drawbacks: gauge freedom, scale ambiguity, and a tendency toward rank collapse. We introduce OrthoGeoLoRA, which enforces an SVD-like form $ΔW = BΣA^\top$ by constraining the low-rank factors to be orthogonal (Stiefel manifold). A geometric reparameterization implements this constraint while remaining compatible with standard optimizers such as Adam and existing fine-tuning pipelines. We also propose a benchmark for hierarchical concept retrieval over the European Language Social Science Thesaurus (ELSST), widely used to organize social science resources in digital repositories. Experiments with a multilingual sentence encoder show that OrthoGeoLoRA outperforms standard LoRA and several strong PEFT variants on ranking metrics under the same low-rank budget, offering a more compute- and parameter-efficient path to adapt foundation models in resource-constrained settings.
EasySize: Elastic Analog Circuit Sizing via LLM-Guided Heuristic Search
Aug 07, 2025Analog circuit design is a time-consuming, experience-driven task in chip development. Despite advances in AI, developing universal, fast, and stable gate sizing methods for analog circuits remains a significant challenge. Recent approaches combine Large Language Models (LLMs) with heuristic search techniques to enhance generalizability, but they often depend on large model sizes and lack portability across different technology nodes. To overcome these limitations, we propose EasySize, the first lightweight gate sizing framework based on a finetuned Qwen3-8B model, designed for universal applicability across process nodes, design specifications, and circuit topologies. EasySize exploits the varying Ease of Attainability (EOA) of performance metrics to dynamically construct task-specific loss functions, enabling efficient heuristic search through global Differential Evolution (DE) and local Particle Swarm Optimization (PSO) within a feedback-enhanced flow. Although finetuned solely on 350nm node data, EasySize achieves strong performance on 5 operational amplifier (Op-Amp) netlists across 180nm, 45nm, and 22nm technology nodes without additional targeted training, and outperforms AutoCkt, a widely-used Reinforcement Learning based sizing framework, on 86.67\% of tasks with more than 96.67\% of simulation resources reduction. We argue that EasySize can significantly reduce the reliance on human expertise and computational resources in gate sizing, thereby accelerating and simplifying the analog circuit design process. EasySize will be open-sourced at a later date.
EMRModel: A Large Language Model for Extracting Medical Consultation Dialogues into Structured Medical Records
Apr 23, 2025Medical consultation dialogues contain critical clinical information, yet their unstructured nature hinders effective utilization in diagnosis and treatment. Traditional methods, relying on rule-based or shallow machine learning techniques, struggle to capture deep and implicit semantics. Recently, large pre-trained language models and Low-Rank Adaptation (LoRA), a lightweight fine-tuning method, have shown promise for structured information extraction. We propose EMRModel, a novel approach that integrates LoRA-based fine-tuning with code-style prompt design, aiming to efficiently convert medical consultation dialogues into structured electronic medical records (EMRs). Additionally, we construct a high-quality, realistically grounded dataset of medical consultation dialogues with detailed annotations. Furthermore, we introduce a fine-grained evaluation benchmark for medical consultation information extraction and provide a systematic evaluation methodology, advancing the optimization of medical natural language processing (NLP) models. Experimental results show EMRModel achieves an F1 score of 88.1%, improving by49.5% over standard pre-trained models. Compared to traditional LoRA fine-tuning methods, our model shows superior performance, highlighting its effectiveness in structured medical record extraction tasks.
Collaborative Autoencoder for Recommender Systems
Jan 30, 2018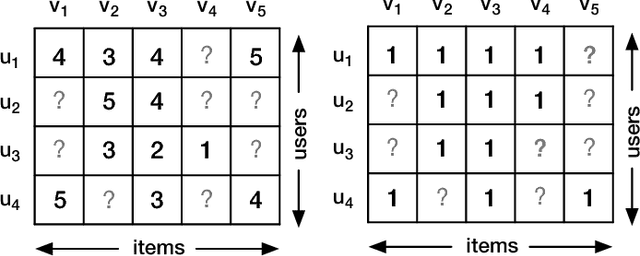
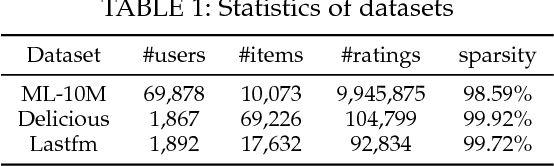
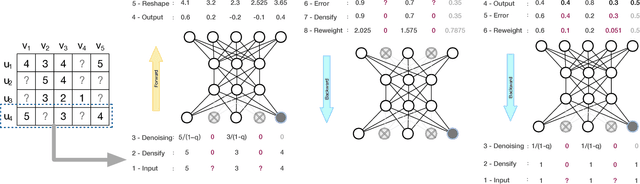
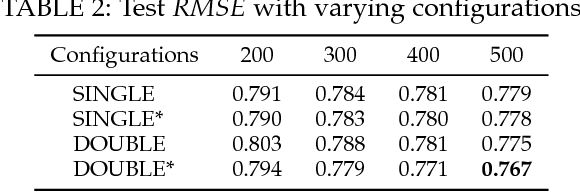
In recent years, deep neural networks have yielded state-of-the-art performance on several tasks. Although some recent works have focused on combining deep learning with recommendation, we highlight three issues of existing works. First, most works perform deep content feature learning and resort to matrix factorization, which cannot effectively model the highly complex user-item interaction function. Second, due to the difficulty on training deep neural networks, existing models utilize a shallow architecture, and thus limit the expressive potential of deep learning. Third, neural network models are easy to overfit on the implicit setting, because negative interactions are not taken into account. To tackle these issues, we present a generic recommender framework called Neural Collaborative Autoencoder (NCAE) to perform collaborative filtering, which works well for both explicit feedback and implicit feedback. NCAE can effectively capture the relationship between interactions via a non-linear matrix factorization process. To optimize the deep architecture of NCAE, we develop a three-stage pre-training mechanism that combines supervised and unsupervised feature learning. Moreover, to prevent overfitting on the implicit setting, we propose an error reweighting module and a sparsity-aware data-augmentation strategy. Extensive experiments on three real-world datasets demonstrate that NCAE can significantly advance the state-of-the-art.