 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Speech Recognition with Corpus Relatedness Sampling
Aug 02, 2019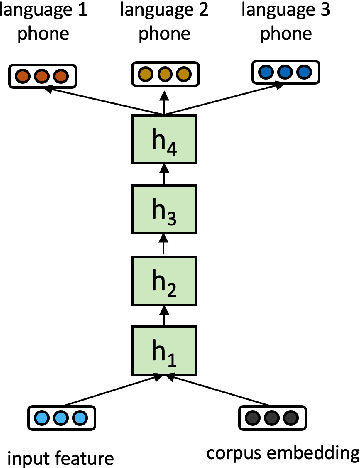
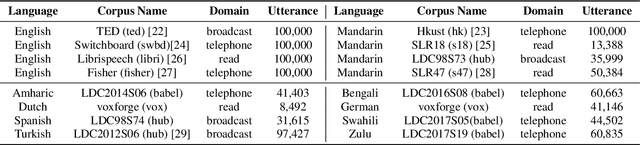
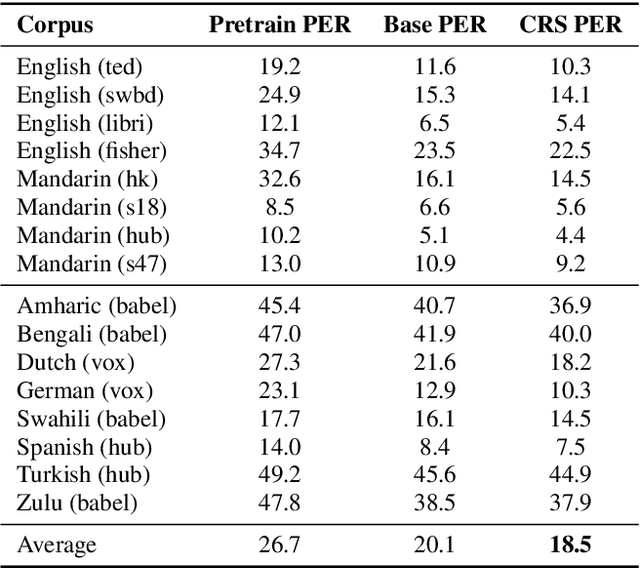
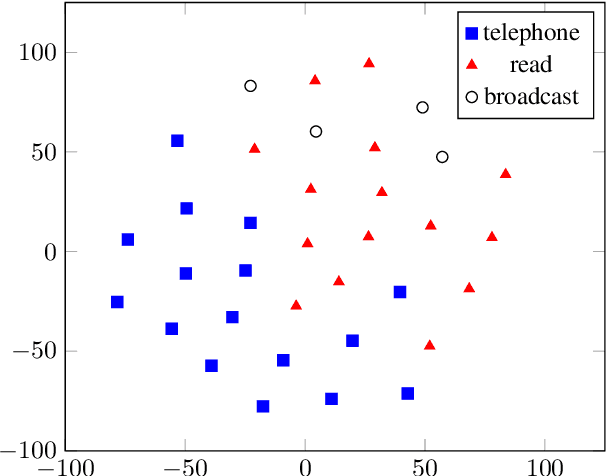
Multilingual acoustic models have been successfully applied to low-resource speech recognition. Most existing works have combined many small corpora together and pretrained a multilingual model by sampling from each corpus uniformly. The model is eventually fine-tuned on each target corpus. This approach, however, fails to exploit the relatedness and similarity among corpora in the training set. For example, the target corpus might benefit more from a corpus in the same domain or a corpus from a close language. In this work, we propose a simple but useful sampling strategy to take advantage of this relatedness. We first compute the corpus-level embeddings and estimate the similarity between each corpus. Next, we start training the multilingual model with uniform-sampling from each corpus at first, then we gradually increase the probability to sample from related corpora based on its similarity with the target corpus. Finally, the model would be fine-tuned automatically on the target corpus. Our sampling strategy outperforms the baseline multilingual model on 16 low-resource tasks. Additionally, we demonstrate that our corpus embeddings capture the language and domain information of each corpus.
The ARIEL-CMU Systems for LoReHLT18
Feb 24, 2019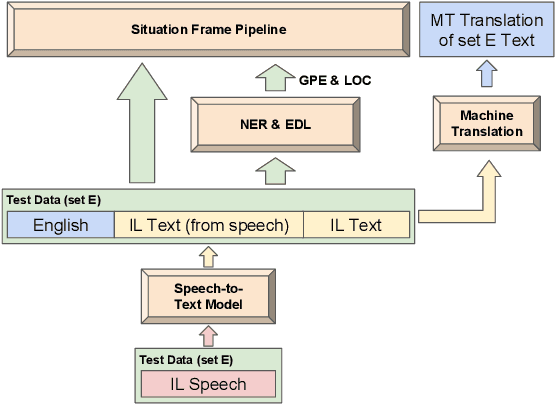
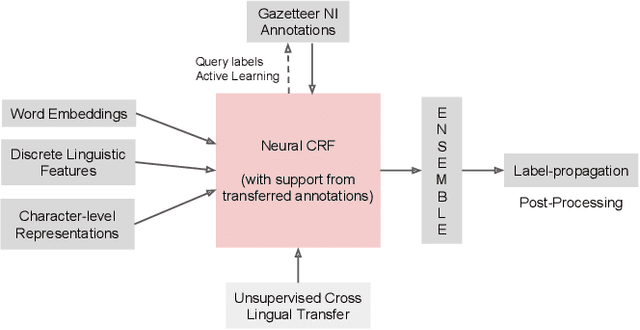
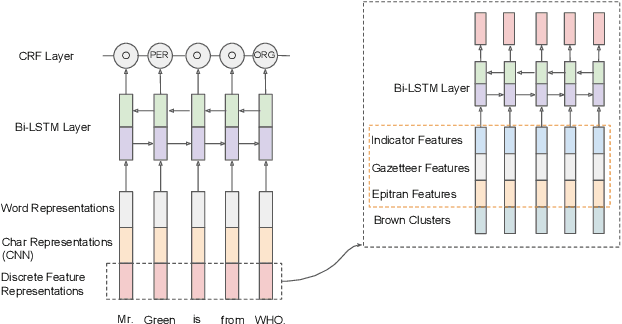
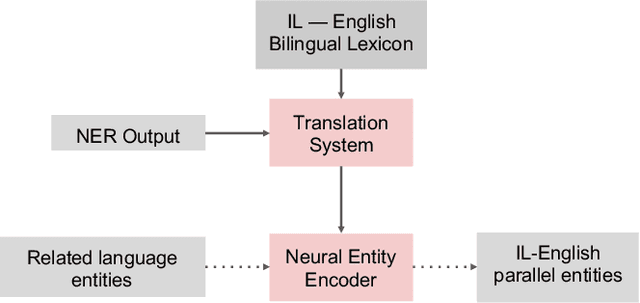
This paper describes the ARIEL-CMU submissions to the Low Resource Human Language Technologies (LoReHLT) 2018 evaluations for the tasks Machine Translation (MT), Entity Discovery and Linking (EDL), and detection of Situation Frames in Text and Speech (SF Text and Speech).
Phoneme Level Language Models for Sequence Based Low Resource ASR
Feb 20, 2019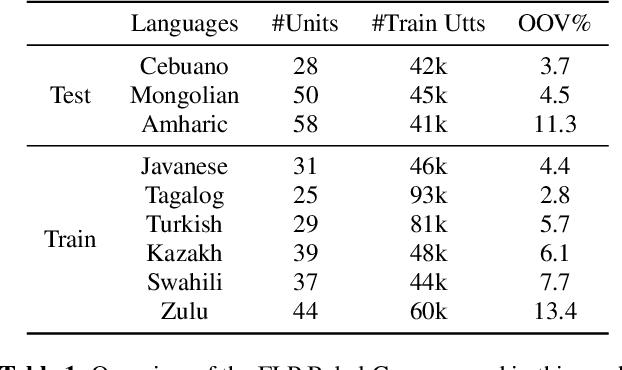
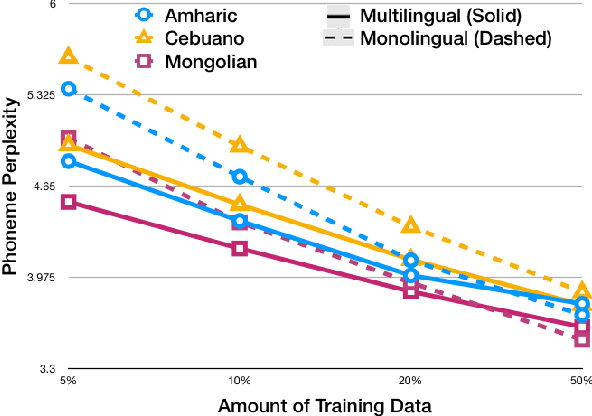
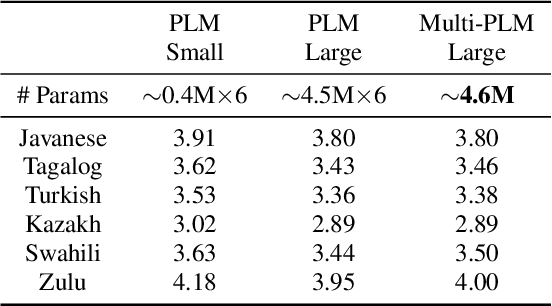
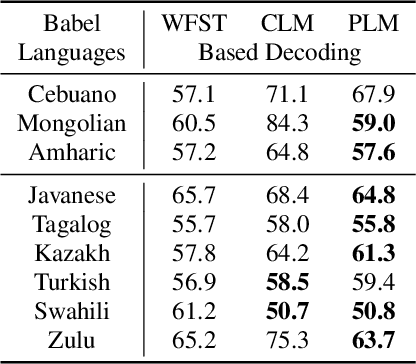
Building multilingual and crosslingual models help bring different languages together in a language universal space. It allows models to share parameters and transfer knowledge across languages, enabling faster and better adaptation to a new language. These approaches are particularly useful for low resource languages. In this paper, we propose a phoneme-level language model that can be used multilingually and for crosslingual adaptation to a target language. We show that our model performs almost as well as the monolingual models by using six times fewer parameters, and is capable of better adaptation to languages not seen during training in a low resource scenario. We show that these phoneme-level language models can be used to decode sequence based Connectionist Temporal Classification (CTC) acoustic model outputs to obtain comparable word error rates with Weighted Finite State Transducer (WFST) based decoding in Babel languages. We also show that these phoneme-level language models outperform WFST decoding in various low-resource conditions like adapting to a new language and domain mismatch between training and testing data.
Real-time Neural-based Input Method
Oct 19, 2018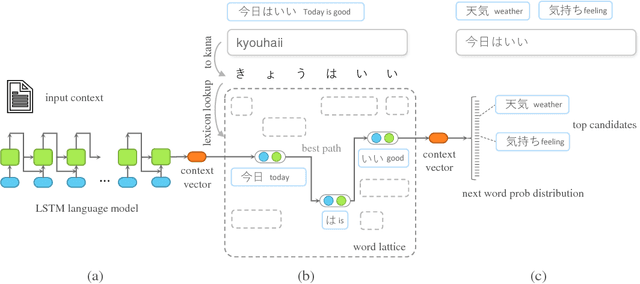
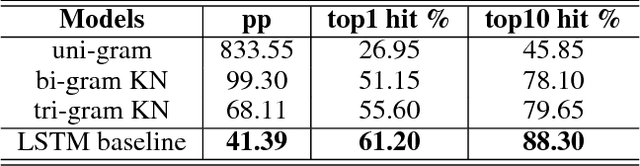
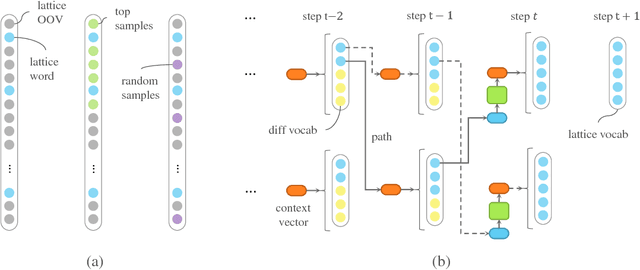
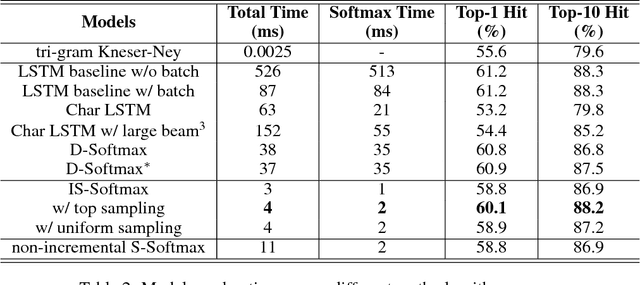
The input method is an essential service on every mobile and desktop devices that provides text suggestions. It converts sequential keyboard inputs to the characters in its target language, which is indispensable for Japanese and Chinese users. Due to critical resource constraints and limited network bandwidth of the target devices, applying neural models to input method is not well explored. In this work, we apply a LSTM-based language model to input method and evaluate its performance for both prediction and conversion tasks with Japanese BCCWJ corpus. We articulate the bottleneck to be the slow softmax computation during conversion. To solve the issue, we propose incremental softmax approximation approach, which computes softmax with a selected subset vocabulary and fix the stale probabilities when the vocabulary is updated in future steps. We refer to this method as incremental selective softmax. The results show a two order speedup for the softmax computation when converting Japanese input sequences with a large vocabulary, reaching real-time speed on commodity CPU. We also exploit the model compressing potential to achieve a 92% model size reduction without losing accuracy.
Domain Robust Feature Extraction for Rapid Low Resource ASR Development
Sep 30, 2018
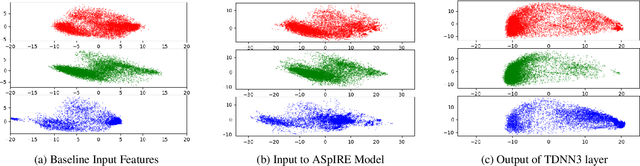

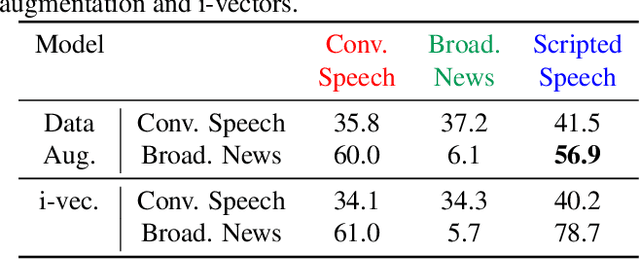
Developing a practical speech recognizer for a low resource language is challenging, not only because of the (potentially unknown) properties of the language, but also because test data may not be from the same domain as the available training data. In this paper, we focus on the latter challenge, i.e. domain mismatch, for systems trained using a sequence-based criterion. We demonstrate the effectiveness of using a pre-trained English recognizer, which is robust to such mismatched conditions, as a domain normalizing feature extractor on a low resource language. In our example, we use Turkish Conversational Speech and Broadcast News data. This enables rapid development of speech recognizers for new languages which can easily adapt to any domain. Testing in various cross-domain scenarios, we achieve relative improvements of around 25% in phoneme error rate, with improvements being around 50% for some domains.