 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMic-hackathon 2024: Hackathon on Machine Learning for Electron and Scanning Probe Microscopy
Jun 10, 2025

Microscopy is a primary source of information on materials structure and functionality at nanometer and atomic scales. The data generated is often well-structured, enriched with metadata and sample histories, though not always consistent in detail or format. The adoption of Data Management Plans (DMPs) by major funding agencies promotes preservation and access. However, deriving insights remains difficult due to the lack of standardized code ecosystems, benchmarks, and integration strategies. As a result, data usage is inefficient and analysis time is extensive. In addition to post-acquisition analysis, new APIs from major microscope manufacturers enable real-time, ML-based analytics for automated decision-making and ML-agent-controlled microscope operation. Yet, a gap remains between the ML and microscopy communities, limiting the impact of these methods on physics, materials discovery, and optimization. Hackathons help bridge this divide by fostering collaboration between ML researchers and microscopy experts. They encourage the development of novel solutions that apply ML to microscopy, while preparing a future workforce for instrumentation, materials science, and applied ML. This hackathon produced benchmark datasets and digital twins of microscopes to support community growth and standardized workflows. All related code is available at GitHub: https://github.com/KalininGroup/Mic-hackathon-2024-codes-publication/tree/1.0.0.1
FDDH: Fast Discriminative Discrete Hashing for Large-Scale Cross-Modal Retrieval
May 15, 2021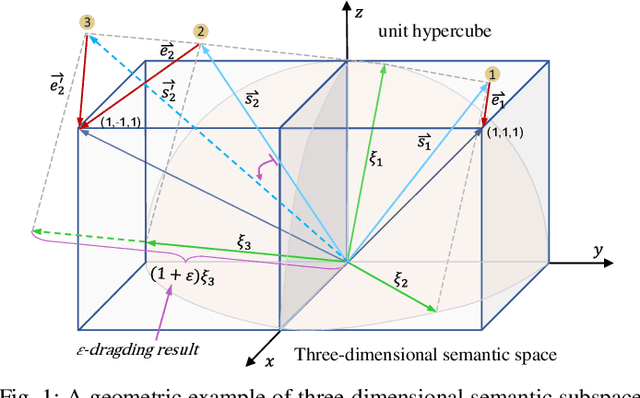
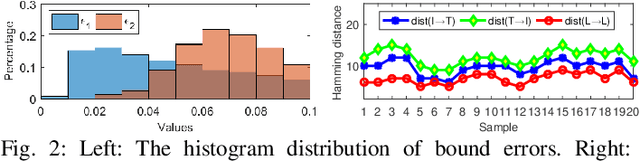
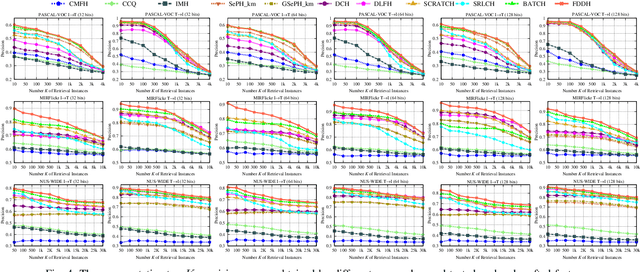
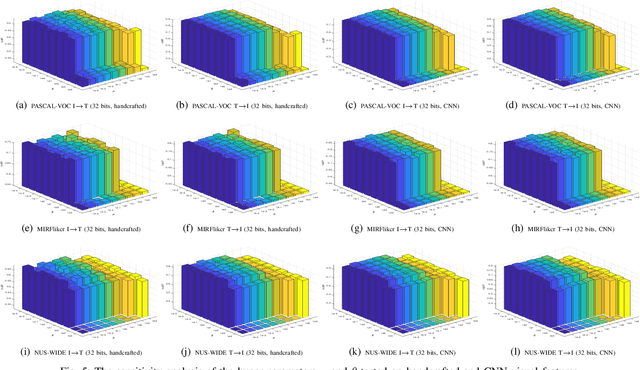
Cross-modal hashing, favored for its effectiveness and efficiency, has received wide attention to facilitating efficient retrieval across different modalities. Nevertheless, most existing methods do not sufficiently exploit the discriminative power of semantic information when learning the hash codes, while often involving time-consuming training procedure for handling the large-scale dataset. To tackle these issues, we formulate the learning of similarity-preserving hash codes in terms of orthogonally rotating the semantic data so as to minimize the quantization loss of mapping such data to hamming space, and propose an efficient Fast Discriminative Discrete Hashing (FDDH) approach for large-scale cross-modal retrieval. More specifically, FDDH introduces an orthogonal basis to regress the targeted hash codes of training examples to their corresponding semantic labels, and utilizes "-dragging technique to provide provable large semantic margins. Accordingly, the discriminative power of semantic information can be explicitly captured and maximized. Moreover, an orthogonal transformation scheme is further proposed to map the nonlinear embedding data into the semantic subspace, which can well guarantee the semantic consistency between the data feature and its semantic representation. Consequently, an efficient closed form solution is derived for discriminative hash code learning, which is very computationally efficient. In addition, an effective and stable online learning strategy is presented for optimizing modality-specific projection functions, featuring adaptivity to different training sizes and streaming data. The proposed FDDH approach theoretically approximates the bi-Lipschitz continuity, runs sufficiently fast, and also significantly improves the retrieval performance over the state-of-the-art methods. The source code is released at: https://github.com/starxliu/FDDH.
* 16 pages, 7 figures