 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Space Object Detection with Multi-Satellite Viewpoints in LEO Constellations
Jun 01, 2026With the growing number of satellites in low Earth orbit (LEO) constellations, the near-Earth space environment has become increasingly congested, making space object detection (SOD) a pressing challenge for space safety and sustainability. To mitigate collision risks and ensure the continuity of space operations, SOD systems must deliver fast and accurate detection under stringent onboard constraints. In this paper, we investigate the potential of multi-viewpoint observation fusion within a deep learning (DL) framework to enhance SOD performance. We design a practical multi-view pipeline and several input representations for feeding multi-view data into YOLO-based detectors. Our experiments show that using multi-view inputs is feasible in most cases and typically produces better results for mAP50 and mAP50-95. For example, in model YOLOv9-m, single-view compared to a three-view fused RGB setting, mAP50 increases from 0.638 to 0.732, while mAP50-95 improves from 0.227 to 0.276. Compared with the single-view setting, the best three-view grayscale configuration improves mAP50 by 36.3% and mAP50-95 by 46.5%. These findings establish multi-view fusion as a viable and effective strategy for SOD, with broad implications for space situational awareness in LEO constellation deployments.
Can Muon Fine-tune Adam-Pretrained Models?
May 11, 2026Muon has emerged as an efficient alternative to Adam for pretraining, yet remains underused for fine-tuning. A key obstacle is that most open models are pretrained with Adam, and naively switching to Muon for fine-tuning leads to degraded performance due to an optimizer mismatch. We investigate this mismatch through controlled experiments and relate it to the distinct implicit biases of Adam and Muon. We provide evidence that the mismatch disrupts pretrained knowledge, and that this disruption scales with update strength. This leads us to hypothesize that constraining updates should mitigate the mismatch. We validate this with LoRA: across language and vision tasks, LoRA reduces the performance gap between Adam and Muon observed under full fine-tuning. Studies on LoRA rank, catastrophic forgetting, and LoRA variants further confirm that mismatch severity correlates with update strength. These results shed light on how optimizer mismatch affects fine-tuning and how it can be mitigated. Our code is available at https://github.com/XingyuQu/muon-finetune.
Rethink Model Re-Basin and the Linear Mode Connectivity
Feb 05, 2024Recent studies suggest that with sufficiently wide models, most SGD solutions can, up to permutation, converge into the same basin. This phenomenon, known as the model re-basin regime, has significant implications for model averaging. However, current re-basin strategies are limited in effectiveness due to a lack of comprehensive understanding of underlying mechanisms. Addressing this gap, our work revisits standard practices and uncovers the frequent inadequacies of existing matching algorithms, which we show can be mitigated through proper re-normalization. By introducing a more direct analytical approach, we expose the interaction between matching algorithms and re-normalization processes. This perspective not only clarifies and refines previous findings but also facilitates novel insights. For instance, it connects the linear mode connectivity to pruning, motivating a lightweight yet effective post-pruning plug-in that can be directly merged with any existing pruning techniques. Our implementation is available at https://github.com/XingyuQu/rethink-re-basin.
GAGA: Deciphering Age-path of Generalized Self-paced Regularizer
Sep 23, 2022
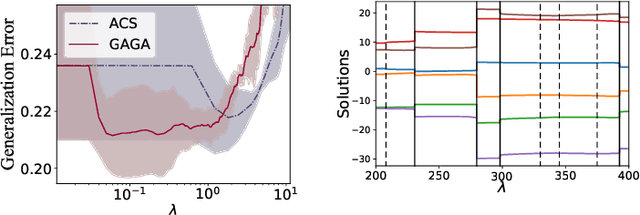
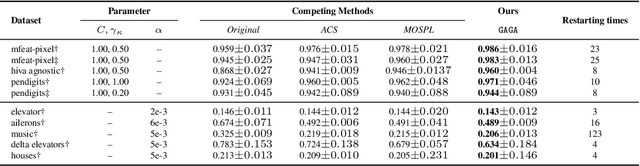
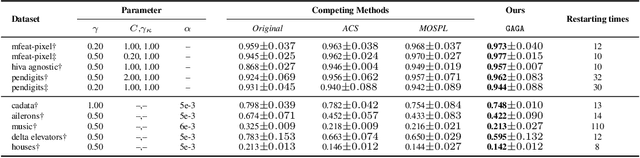
Nowadays self-paced learning (SPL) is an important machine learning paradigm that mimics the cognitive process of humans and animals. The SPL regime involves a self-paced regularizer and a gradually increasing age parameter, which plays a key role in SPL but where to optimally terminate this process is still non-trivial to determine. A natural idea is to compute the solution path w.r.t. age parameter (i.e., age-path). However, current age-path algorithms are either limited to the simplest regularizer, or lack solid theoretical understanding as well as computational efficiency. To address this challenge, we propose a novel \underline{G}eneralized \underline{Ag}e-path \underline{A}lgorithm (GAGA) for SPL with various self-paced regularizers based on ordinary differential equations (ODEs) and sets control, which can learn the entire solution spectrum w.r.t. a range of age parameters. To the best of our knowledge, GAGA is the first exact path-following algorithm tackling the age-path for general self-paced regularizer. Finally the algorithmic steps of classic SVM and Lasso are described in detail. We demonstrate the performance of GAGA on real-world datasets, and find considerable speedup between our algorithm and competing baselines.