 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Face Synthesis from Visual Attributes
Apr 09, 2021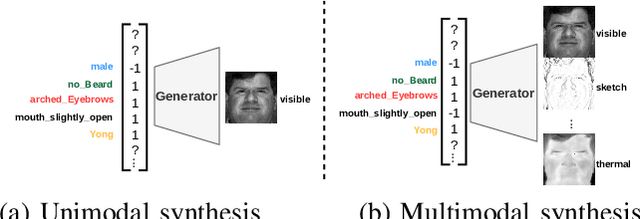



Synthesis of face images from visual attributes is an important problem in computer vision and biometrics due to its applications in law enforcement and entertainment. Recent advances in deep generative networks have made it possible to synthesize high-quality face images from visual attributes. However, existing methods are specifically designed for generating unimodal images (i.e visible faces) from attributes. In this paper, we propose a novel generative adversarial network that simultaneously synthesizes identity preserving multimodal face images (i.e. visible, sketch, thermal, etc.) from visual attributes without requiring paired data in different domains for training the network. We introduce a novel generator with multimodal stretch-out modules to simultaneously synthesize multimodal face images. Additionally, multimodal stretch-in modules are introduced in the discriminator which discriminates between real and fake images. Extensive experiments and comparisons with several state-of-the-art methods are performed to verify the effectiveness of the proposed attribute-based multimodal synthesis method.
A Large-Scale, Time-Synchronized Visible and Thermal Face Dataset
Jan 07, 2021
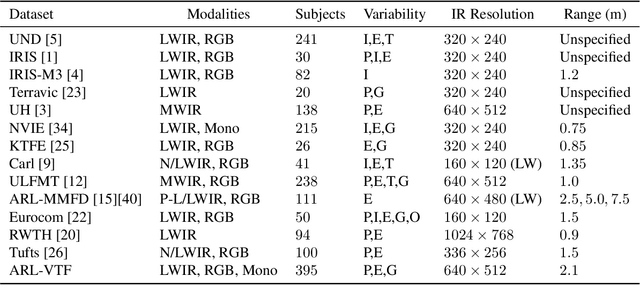


Thermal face imagery, which captures the naturally emitted heat from the face, is limited in availability compared to face imagery in the visible spectrum. To help address this scarcity of thermal face imagery for research and algorithm development, we present the DEVCOM Army Research Laboratory Visible-Thermal Face Dataset (ARL-VTF). With over 500,000 images from 395 subjects, the ARL-VTF dataset represents, to the best of our knowledge, the largest collection of paired visible and thermal face images to date. The data was captured using a modern long wave infrared (LWIR) camera mounted alongside a stereo setup of three visible spectrum cameras. Variability in expressions, pose, and eyewear has been systematically recorded. The dataset has been curated with extensive annotations, metadata, and standardized protocols for evaluation. Furthermore, this paper presents extensive benchmark results and analysis on thermal face landmark detection and thermal-to-visible face verification by evaluating state-of-the-art models on the ARL-VTF dataset.
Multi-Scale Thermal to Visible Face Verification via Attribute Guided Synthesis
Apr 20, 2020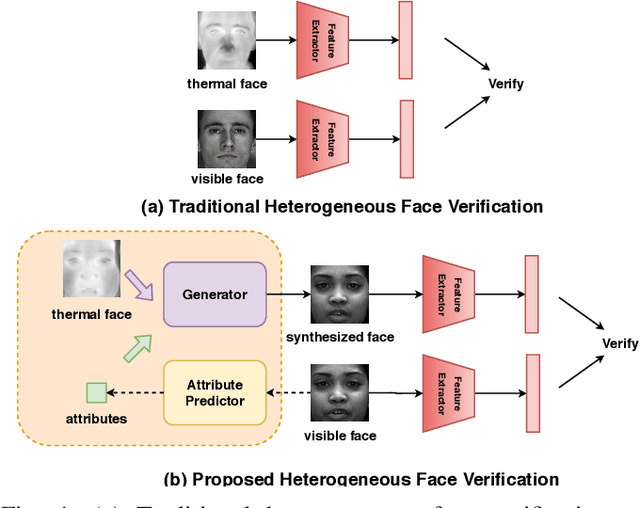



Thermal-to-visible face verification is a challenging problem due to the large domain discrepancy between the modalities. Existing approaches either attempt to synthesize visible faces from thermal faces or extract robust features from these modalities for cross-modal matching. In this paper, we use attributes extracted from visible images to synthesize the attributepreserved visible images from thermal imagery for cross-modal matching. A pre-trained VGG-Face network is used to extract the attributes from the visible image. Then, a novel multi-scale generator is proposed to synthesize the visible image from the thermal image guided by the extracted attributes. Finally, a pretrained VGG-Face network is leveraged to extract features from the synthesized image and the input visible image for verification. An extended dataset consisting of polarimetric thermal faces of 121 subjects is also introduced. Extensive experiments evaluated on various datasets and protocols demonstrate that the proposed method achieves state-of-the-art per-formance.
Facial Synthesis from Visual Attributes via Sketch using Multi-Scale Generators
Dec 17, 2019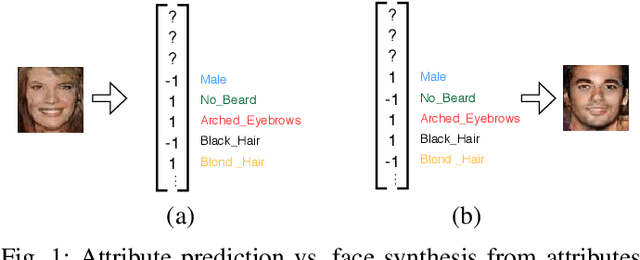
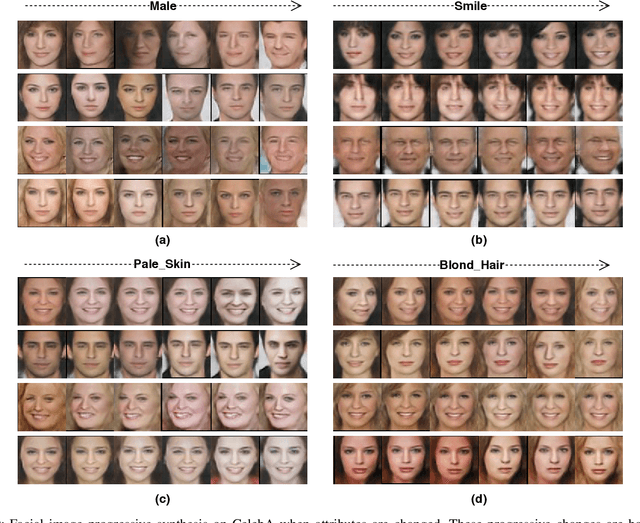

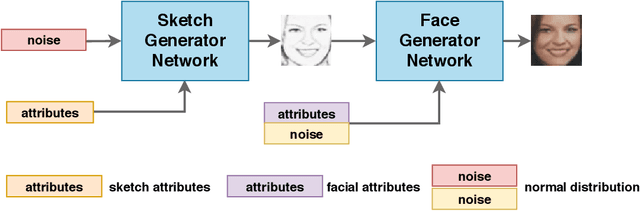
Automatic synthesis of faces from visual attributes is an important problem in computer vision and has wide applications in law enforcement and entertainment. With the advent of deep generative convolutional neural networks (CNNs), attempts have been made to synthesize face images from attributes and text descriptions. In this paper, we take a different approach, where we formulate the original problem as a stage-wise learning problem. We first synthesize the facial sketch corresponding to the visual attributes and then we generate the face image based on the synthesized sketch. The proposed framework, is based on a combination of two different Generative Adversarial Networks (GANs) - (1) a sketch generator network which synthesizes realistic sketch from the input attributes, and (2) a face generator network which synthesizes facial images from the synthesized sketch images with the help of facial attributes. Extensive experiments and comparison with recent methods are performed to verify the effectiveness of the proposed attribute-based two-stage face synthesis method.
Polarimetric Thermal to Visible Face Verification via Self-Attention Guided Synthesis
Apr 15, 2019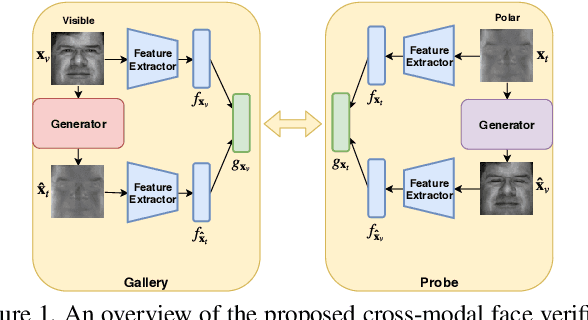
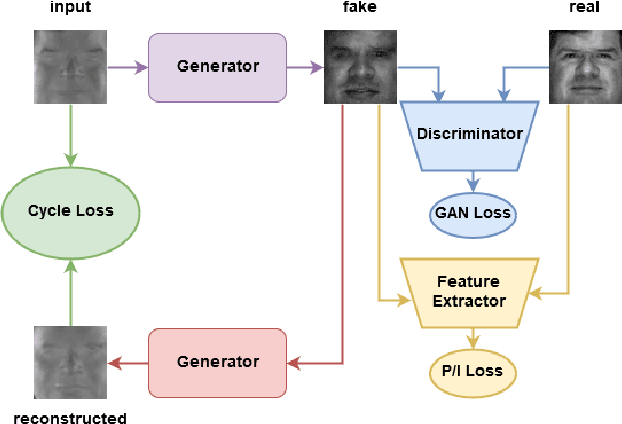
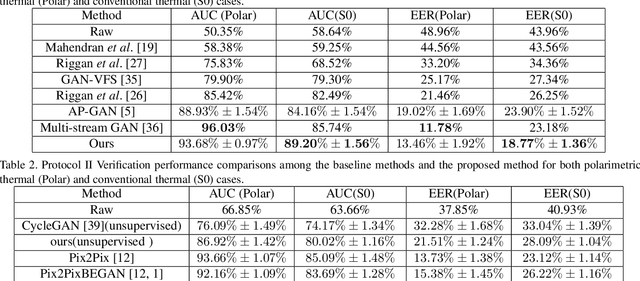
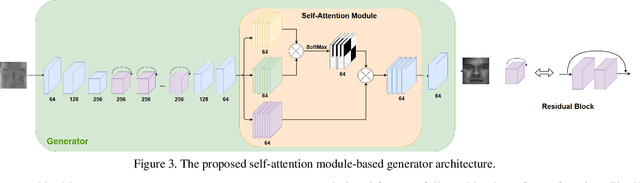
Polarimetric thermal to visible face verification entails matching two images that contain significant domain differences. Several recent approaches have attempted to synthesize visible faces from thermal images for cross-modal matching. In this paper, we take a different approach in which rather than focusing only on synthesizing visible faces from thermal faces, we also propose to synthesize thermal faces from visible faces. Our intuition is based on the fact that thermal images also contain some discriminative information about the person for verification. Deep features from a pre-trained Convolutional Neural Network (CNN) are extracted from the original as well as the synthesized images. These features are then fused to generate a template which is then used for verification. The proposed synthesis network is based on the self-attention generative adversarial network (SAGAN) which essentially allows efficient attention-guided image synthesis. Extensive experiments on the ARL polarimetric thermal face dataset demonstrate that the proposed method achieves state-of-the-art performance.
Polarimetric Thermal to Visible Face Verification via Attribute Preserved Synthesis
Jan 03, 2019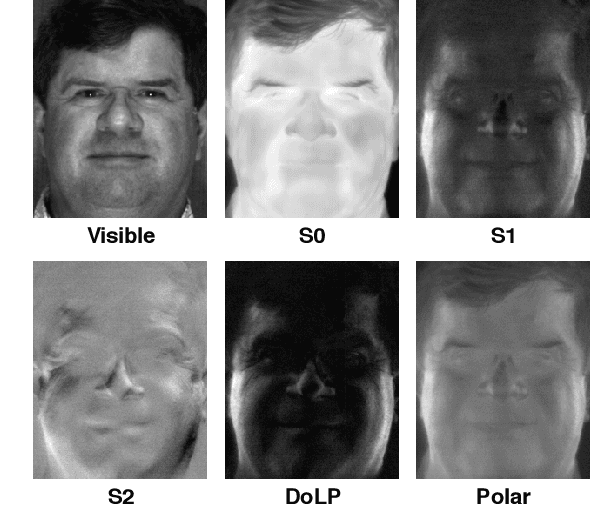

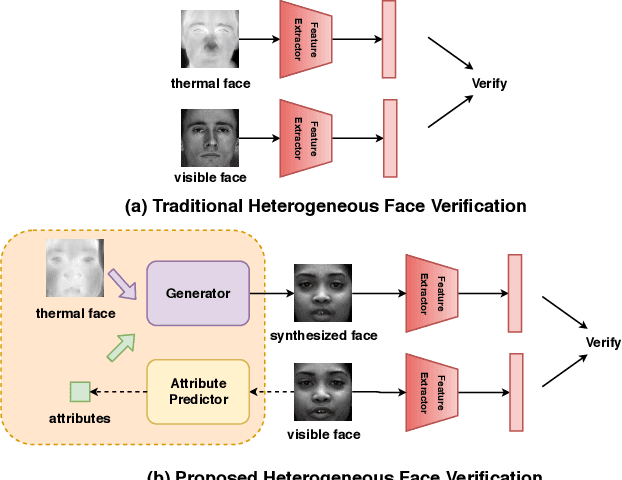
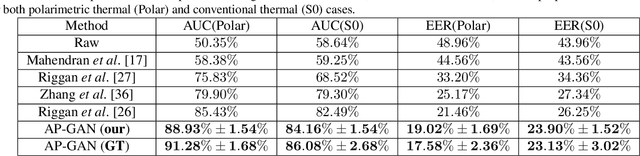
Thermal to visible face verification is a challenging problem due to the large domain discrepancy between the modalities. Existing approaches either attempt to synthesize visible faces from thermal faces or extract robust features from these modalities for cross-modal matching. In this paper, we take a different approach in which we make use of the attributes extracted from the visible image to synthesize the attribute-preserved visible image from the input thermal image for cross-modal matching. A pre-trained VGG-Face network is used to extract the attributes from the visible image. Then, a novel Attribute Preserved Generative Adversarial Network (AP-GAN) is proposed to synthesize the visible image from the thermal image guided by the extracted attributes. Finally, a deep network is used to extract features from the synthesized image and the input visible image for verification. Extensive experiments on the ARL Polarimetric face dataset show that the proposed method achieves significant improvements over the state-of-the-art methods.
GP-GAN: Gender Preserving GAN for Synthesizing Faces from Landmarks
Apr 25, 2018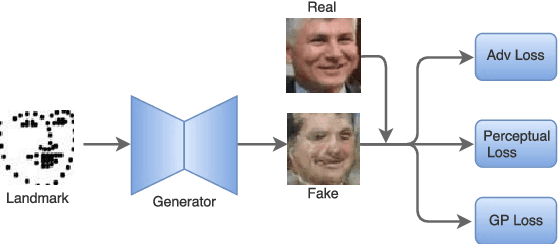
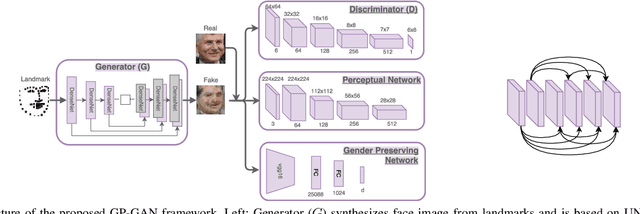
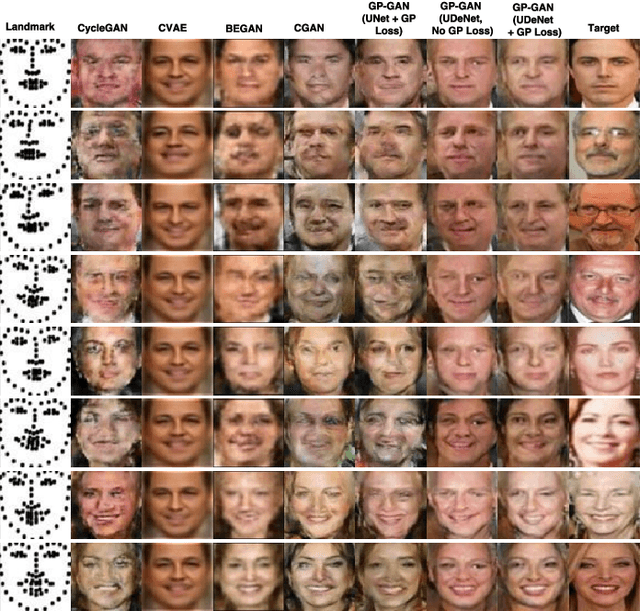

Facial landmarks constitute the most compressed representation of faces and are known to preserve information such as pose, gender and facial structure present in the faces. Several works exist that attempt to perform high-level face-related analysis tasks based on landmarks. In contrast, in this work, an attempt is made to tackle the inverse problem of synthesizing faces from their respective landmarks. The primary aim of this work is to demonstrate that information preserved by landmarks (gender in particular) can be further accentuated by leveraging generative models to synthesize corresponding faces. Though the problem is particularly challenging due to its ill-posed nature, we believe that successful synthesis will enable several applications such as boosting performance of high-level face related tasks using landmark points and performing dataset augmentation. To this end, a novel face-synthesis method known as Gender Preserving Generative Adversarial Network (GP-GAN) that is guided by adversarial loss, perceptual loss and a gender preserving loss is presented. Further, we propose a novel generator sub-network UDeNet for GP-GAN that leverages advantages of U-Net and DenseNet architectures. Extensive experiments and comparison with recent methods are performed to verify the effectiveness of the proposed method.
Face Synthesis from Visual Attributes via Sketch using Conditional VAEs and GANs
Dec 30, 2017

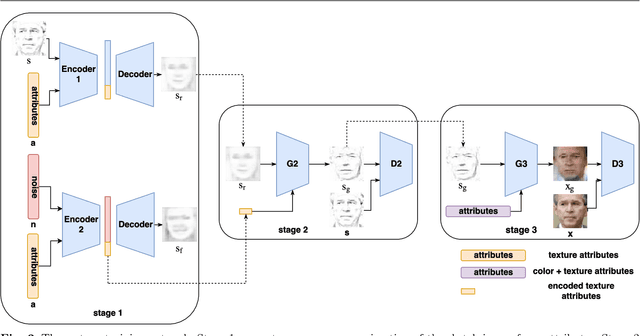

Automatic synthesis of faces from visual attributes is an important problem in computer vision and has wide applications in law enforcement and entertainment. With the advent of deep generative convolutional neural networks (CNNs), attempts have been made to synthesize face images from attributes and text descriptions. In this paper, we take a different approach, where we formulate the original problem as a stage-wise learning problem. We first synthesize the facial sketch corresponding to the visual attributes and then we reconstruct the face image based on the synthesized sketch. The proposed Attribute2Sketch2Face framework, which is based on a combination of deep Conditional Variational Autoencoder (CVAE) and Generative Adversarial Networks (GANs), consists of three stages: (1) Synthesis of facial sketch from attributes using a CVAE architecture, (2) Enhancement of coarse sketches to produce sharper sketches using a GAN-based framework, and (3) Synthesis of face from sketch using another GAN-based network. Extensive experiments and comparison with recent methods are performed to verify the effectiveness of the proposed attribute-based three stage face synthesis method.