 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Trait Subspace Steering to Reveal the Dark Side of Human-AI Interaction
Mar 18, 2026Recent incidents have highlighted alarming cases where human-AI interactions led to negative psychological outcomes, including mental health crises and even user harm. As LLMs serve as sources of guidance, emotional support, and even informal therapy, these risks are poised to escalate. However, studying the mechanisms underlying harmful human-AI interactions presents significant methodological challenges, where organic harmful interactions typically develop over sustained engagement, requiring extensive conversational context that are difficult to simulate in controlled settings. To address this gap, we developed a Multi-Trait Subspace Steering (MultiTraitsss) framework that leverages established crisis-associated traits and novel subspace steering framework to generate Dark models that exhibits cumulative harmful behavioral patterns. Single-turn and multi-turn evaluations show that our dark models consistently produce harmful interaction and outcomes. Using our Dark models, we propose protective measure to reduce harmful outcomes in Human-AI interactions.
Probing Latent Subspaces in LLM for AI Security: Identifying and Manipulating Adversarial States
Mar 12, 2025
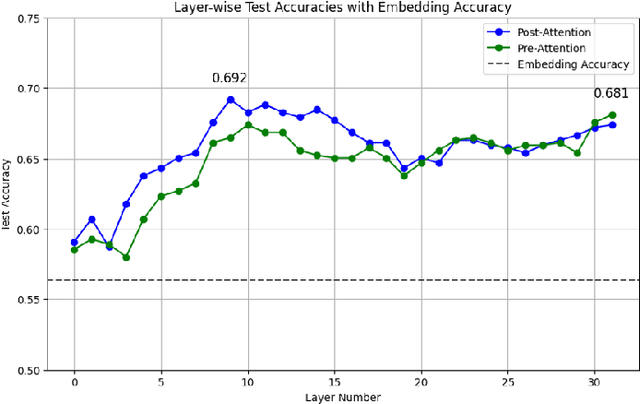


Large Language Models (LLMs) have demonstrated remarkable capabilities across various tasks, yet they remain vulnerable to adversarial manipulations such as jailbreaking via prompt injection attacks. These attacks bypass safety mechanisms to generate restricted or harmful content. In this study, we investigated the underlying latent subspaces of safe and jailbroken states by extracting hidden activations from a LLM. Inspired by attractor dynamics in neuroscience, we hypothesized that LLM activations settle into semi stable states that can be identified and perturbed to induce state transitions. Using dimensionality reduction techniques, we projected activations from safe and jailbroken responses to reveal latent subspaces in lower dimensional spaces. We then derived a perturbation vector that when applied to safe representations, shifted the model towards a jailbreak state. Our results demonstrate that this causal intervention results in statistically significant jailbreak responses in a subset of prompts. Next, we probed how these perturbations propagate through the model's layers, testing whether the induced state change remains localized or cascades throughout the network. Our findings indicate that targeted perturbations induced distinct shifts in activations and model responses. Our approach paves the way for potential proactive defenses, shifting from traditional guardrail based methods to preemptive, model agnostic techniques that neutralize adversarial states at the representation level.
Enhancing Reasoning Capacity of SLM using Cognitive Enhancement
Apr 01, 2024



Large Language Models (LLMs) have been applied to automate cyber security activities and processes including cyber investigation and digital forensics. However, the use of such models for cyber investigation and digital forensics should address accountability and security considerations. Accountability ensures models have the means to provide explainable reasonings and outcomes. This information can be extracted through explicit prompt requests. For security considerations, it is crucial to address privacy and confidentiality of the involved data during data processing as well. One approach to deal with this consideration is to have the data processed locally using a local instance of the model. Due to limitations of locally available resources, namely memory and GPU capacities, a Smaller Large Language Model (SLM) will typically be used. These SLMs have significantly fewer parameters compared to the LLMs. However, such size reductions have notable performance reduction, especially when tasked to provide reasoning explanations. In this paper, we aim to mitigate performance reduction through the integration of cognitive strategies that humans use for problem-solving. We term this as cognitive enhancement through prompts. Our experiments showed significant improvement gains of the SLMs' performances when such enhancements were applied. We believe that our exploration study paves the way for further investigation into the use of cognitive enhancement to optimize SLM for cyber security applications.