 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSAIC-Net: A Multi-Scale Attention and Imbalance-Aware Contrastive Network for ECG-Based Myocardial Substrate Abnormality Detection
Jun 04, 2026Myocardial substrate abnormalities, such as myocardial scar and myocardial infarction (MI), are associated with adverse cardiovascular outcomes. Electrocardiography (ECG) provides a low-cost and widely available tool for detecting these abnormalities, but ECG-based detection remains challenging due to heterogeneous lead-dependent manifestations, high-dimensional multi-lead signals, class imbalance, and the limited interpretability of deep learning models. We propose a multi-scale attention-enhanced convolutional network (MSAIC-Net) for ECG-based myocardial substrate abnormality detection. MSAIC-Net employs parallel atrous convolutional branches to extract ECG features across multiple temporal receptive fields. %, enabling the model to capture both local and longer-range temporal patterns. Channel attention is then used to adaptively reweight informative lead-wise and feature-channel representations. To address class imbalance and improve feature separability, we introduce a novel imbalance-aware supervised contrastive learning strategy that encourages samples from the same class to form compact representations while increasing separation between abnormal and normal samples. Lead-wise permutation importance is further incorporated to quantify the contribution of each ECG lead and improve model interpretability. The proposed method was evaluated on two complementary datasets: a low-data institutional cohort from the University of Virginia (UVA) Health System for myocardial scar classification and the large-scale public PTB-XL dataset from PhysioNet for MI identification. Experimental results show that MSAIC-Net outperforms baseline models, with particularly pronounced improvements in the low-data UVA cohort. Overall, the proposed framework provides an effective and interpretable approach for ECG-based detection of myocardial substrate abnormalities.
The Cognitive Circuit Breaker: A Systems Engineering Framework for Intrinsic AI Reliability
Apr 15, 2026As Large Language Models (LLMs) are increasingly deployed in mission-critical software systems, detecting hallucinations and ``faked truthfulness'' has become a paramount engineering challenge. Current reliability architectures rely heavily on post-generation, black-box mechanisms, such as Retrieval-Augmented Generation (RAG) cross-checking or LLM-as-a-judge evaluators. These extrinsic methods introduce unacceptable latency, high computational overhead, and reliance on secondary external API calls, frequently violating standard software engineering Service Level Agreements (SLAs). In this paper, we propose the Cognitive Circuit Breaker, a novel systems engineering framework that provides intrinsic reliability monitoring with minimal latency overhead. By extracting hidden states during a model's forward pass, we calculate the ``Cognitive Dissonance Delta'' -- the mathematical gap between an LLM's outward semantic confidence (softmax probabilities) and its internal latent certainty (derived via linear probes). We demonstrate statistically significant detection of cognitive dissonance, highlight architecture-dependent Out-of-Distribution (OOD) generalization, and show that this framework adds negligible computational overhead to the active inference pipeline.
Curriculum-Guided Myocardial Scar Segmentation for Ischemic and Non-ischemic Cardiomyopathy
Mar 30, 2026Identification and quantification of myocardial scar is important for diagnosis and prognosis of cardiovascular diseases. However, reliable scar segmentation from Late Gadolinium Enhancement Cardiac Magnetic Resonance (LGE-CMR) images remains a challenge due to variations in contrast enhancement across patients, suboptimal imaging conditions such as post contrast washout, and inconsistencies in ground truth annotations on diffuse scars caused by inter observer variability. In this work, we propose a curriculum learning-based framework designed to improve segmentation performance under these challenging conditions. The method introduces a progressive training strategy that guides the model from high-confidence, clearly defined scar regions to low confidence or visually ambiguous samples with limited scar burden. By structuring the learning process in this manner, the network develops robustness to uncertain labels and subtle scar appearances that are often underrepresented in conventional training pipelines. Experimental results show that the proposed approach enhances segmentation accuracy and consistency, particularly for cases with minimal or diffuse scar, outperforming standard training baselines. This strategy provides a principled way to leverage imperfect data for improved myocardial scar quantification in clinical applications. Our code is publicly available on GitHub.
Multi-Trait Subspace Steering to Reveal the Dark Side of Human-AI Interaction
Mar 18, 2026Recent incidents have highlighted alarming cases where human-AI interactions led to negative psychological outcomes, including mental health crises and even user harm. As LLMs serve as sources of guidance, emotional support, and even informal therapy, these risks are poised to escalate. However, studying the mechanisms underlying harmful human-AI interactions presents significant methodological challenges, where organic harmful interactions typically develop over sustained engagement, requiring extensive conversational context that are difficult to simulate in controlled settings. To address this gap, we developed a Multi-Trait Subspace Steering (MultiTraitsss) framework that leverages established crisis-associated traits and novel subspace steering framework to generate Dark models that exhibits cumulative harmful behavioral patterns. Single-turn and multi-turn evaluations show that our dark models consistently produce harmful interaction and outcomes. Using our Dark models, we propose protective measure to reduce harmful outcomes in Human-AI interactions.
The Quantum Sieve Tracer: A Hybrid Framework for Layer-Wise Activation Tracing in Large Language Models
Feb 06, 2026Mechanistic interpretability aims to reverse-engineer the internal computations of Large Language Models (LLMs), yet separating sparse semantic signals from high-dimensional polysemantic noise remains a significant challenge. This paper introduces the Quantum Sieve Tracer, a hybrid quantum-classical framework designed to characterize factual recall circuits. We implement a modular pipeline that first localizes critical layers using classical causal tracing, then maps specific attention head activations into an exponentially large quantum Hilbert space. Using open-weight models (Meta Llama-3.2-1B and Alibaba Qwen2.5-1.5B-Instruct), we perform a two-stage analysis that reveals a fundamental architectural divergence. While Qwen's layer 7 circuit functions as a classic Recall Hub, we discover that Llama's layer 9 acts as an Interference Suppression circuit, where ablating the identified heads paradoxically improves factual recall. Our results demonstrate that quantum kernels can distinguish between these constructive (recall) and reductive (suppression) mechanisms, offering a high-resolution tool for analyzing the fine-grained topology of attention.
Conversational Context Classification: A Representation Engineering Approach
Jan 18, 2026The increasing prevalence of Large Language Models (LLMs) demands effective safeguards for their operation, particularly concerning their tendency to generate out-of-context responses. A key challenge is accurately detecting when LLMs stray from expected conversational norms, manifesting as topic shifts, factual inaccuracies, or outright hallucinations. Traditional anomaly detection struggles to directly apply within contextual semantics. This paper outlines our experiment in exploring the use of Representation Engineering (RepE) and One-Class Support Vector Machine (OCSVM) to identify subspaces within the internal states of LLMs that represent a specific context. By training OCSVM on in-context examples, we establish a robust boundary within the LLM's hidden state latent space. We evaluate out study with two open source LLMs - Llama and Qwen models in specific contextual domain. Our approach entailed identifying the optimal layers within the LLM's internal state subspaces that strongly associates with the context of interest. Our evaluation results showed promising results in identifying the subspace for a specific context. Aside from being useful in detecting in or out of context conversation threads, this research work contributes to the study of better interpreting LLMs.
Automated Post-Incident Policy Gap Analysis via Threat-Informed Evidence Mapping using Large Language Models
Jan 04, 2026Cybersecurity post-incident reviews are essential for identifying control failures and improving organisational resilience, yet they remain labour-intensive, time-consuming, and heavily reliant on expert judgment. This paper investigates whether Large Language Models (LLMs) can augment post-incident review workflows by autonomously analysing system evidence and identifying security policy gaps. We present a threat-informed, agentic framework that ingests log data, maps observed behaviours to the MITRE ATT&CK framework, and evaluates organisational security policies for adequacy and compliance. Using a simulated brute-force attack scenario against a Windows OpenSSH service (MITRE ATT&CK T1110), the system leverages GPT-4o for reasoning, LangGraph for multi-agent workflow orchestration, and LlamaIndex for traceable policy retrieval. Experimental results indicate that the LLM-based pipeline can interpret log-derived evidence, identify insufficient or missing policy controls, and generate actionable remediation recommendations with explicit evidence-to-policy traceability. Unlike prior work that treats log analysis and policy validation as isolated tasks, this study integrates both into a unified end-to-end proof-of-concept post-incident review framework. The findings suggest that LLM-assisted analysis has the potential to improve the efficiency, consistency, and auditability of post-incident evaluations, while highlighting the continued need for human oversight in high-stakes cybersecurity decision-making.
Automating Security Audit Using Large Language Model based Agent: An Exploration Experiment
May 15, 2025
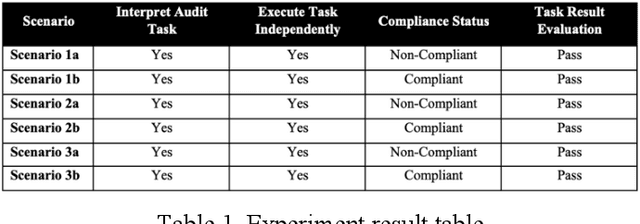
In the current rapidly changing digital environment, businesses are under constant stress to ensure that their systems are secured. Security audits help to maintain a strong security posture by ensuring that policies are in place, controls are implemented, gaps are identified for cybersecurity risks mitigation. However, audits are usually manual, requiring much time and costs. This paper looks at the possibility of developing a framework to leverage Large Language Models (LLMs) as an autonomous agent to execute part of the security audit, namely with the field audit. password policy compliance for Windows operating system. Through the conduct of an exploration experiment of using GPT-4 with Langchain, the agent executed the audit tasks by accurately flagging password policy violations and appeared to be more efficient than traditional manual audits. Despite its potential limitations in operational consistency in complex and dynamic environment, the framework suggests possibilities to extend further to real-time threat monitoring and compliance checks.
Probing Latent Subspaces in LLM for AI Security: Identifying and Manipulating Adversarial States
Mar 12, 2025
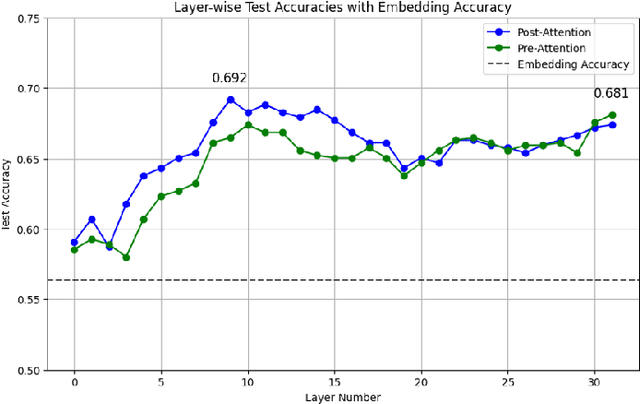


Large Language Models (LLMs) have demonstrated remarkable capabilities across various tasks, yet they remain vulnerable to adversarial manipulations such as jailbreaking via prompt injection attacks. These attacks bypass safety mechanisms to generate restricted or harmful content. In this study, we investigated the underlying latent subspaces of safe and jailbroken states by extracting hidden activations from a LLM. Inspired by attractor dynamics in neuroscience, we hypothesized that LLM activations settle into semi stable states that can be identified and perturbed to induce state transitions. Using dimensionality reduction techniques, we projected activations from safe and jailbroken responses to reveal latent subspaces in lower dimensional spaces. We then derived a perturbation vector that when applied to safe representations, shifted the model towards a jailbreak state. Our results demonstrate that this causal intervention results in statistically significant jailbreak responses in a subset of prompts. Next, we probed how these perturbations propagate through the model's layers, testing whether the induced state change remains localized or cascades throughout the network. Our findings indicate that targeted perturbations induced distinct shifts in activations and model responses. Our approach paves the way for potential proactive defenses, shifting from traditional guardrail based methods to preemptive, model agnostic techniques that neutralize adversarial states at the representation level.
Audio Simulation for Sound Source Localization in Virtual Evironment
Apr 02, 2024Non-line-of-sight localization in signal-deprived environments is a challenging yet pertinent problem. Acoustic methods in such predominantly indoor scenarios encounter difficulty due to the reverberant nature. In this study, we aim to locate sound sources to specific locations within a virtual environment by leveraging physically grounded sound propagation simulations and machine learning methods. This process attempts to overcome the issue of data insufficiency to localize sound sources to their location of occurrence especially in post-event localization. We achieve 0.786+/- 0.0136 F1-score using an audio transformer spectrogram approach.