 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Task-guided, Implicitly-searched and Meta-initialized Deep Model for Image Fusion
May 25, 2023Image fusion plays a key role in a variety of multi-sensor-based vision systems, especially for enhancing visual quality and/or extracting aggregated features for perception. However, most existing methods just consider image fusion as an individual task, thus ignoring its underlying relationship with these downstream vision problems. Furthermore, designing proper fusion architectures often requires huge engineering labor. It also lacks mechanisms to improve the flexibility and generalization ability of current fusion approaches. To mitigate these issues, we establish a Task-guided, Implicit-searched and Meta-initialized (TIM) deep model to address the image fusion problem in a challenging real-world scenario. Specifically, we first propose a constrained strategy to incorporate information from downstream tasks to guide the unsupervised learning process of image fusion. Within this framework, we then design an implicit search scheme to automatically discover compact architectures for our fusion model with high efficiency. In addition, a pretext meta initialization technique is introduced to leverage divergence fusion data to support fast adaptation for different kinds of image fusion tasks. Qualitative and quantitative experimental results on different categories of image fusion problems and related downstream tasks (e.g., visual enhancement and semantic understanding) substantiate the flexibility and effectiveness of our TIM. The source code will be available at https://github.com/LiuZhu-CV/TIMFusion.
MonoTDP: Twin Depth Perception for Monocular 3D Object Detection in Adverse Scenes
May 25, 2023



3D object detection plays a crucial role in numerous intelligent vision systems. Detection in the open world inevitably encounters various adverse scenes, such as dense fog, heavy rain, and low light conditions. Although existing efforts primarily focus on diversifying network architecture or training schemes, resulting in significant progress in 3D object detection, most of these learnable modules fail in adverse scenes, thereby hindering detection performance. To address this issue, this paper proposes a monocular 3D detection model designed to perceive twin depth in adverse scenes, termed MonoTDP, which effectively mitigates the degradation of detection performance in various harsh environments. Specifically, we first introduce an adaptive learning strategy to aid the model in handling uncontrollable weather conditions, significantly resisting degradation caused by various degrading factors. Then, to address the depth/content loss in adverse regions, we propose a novel twin depth perception module that simultaneously estimates scene and object depth, enabling the integration of scene-level features and object-level features. Additionally, we assemble a new adverse 3D object detection dataset encompassing a wide range of challenging scenes, including rainy, foggy, and low light weather conditions, with each type of scene containing 7,481 images. Experimental results demonstrate that our proposed method outperforms current state-of-the-art approaches by an average of 3.12% in terms of AP_R40 for car category across various adverse environments.
PEARL: Preprocessing Enhanced Adversarial Robust Learning of Image Deraining for Semantic Segmentation
May 25, 2023



In light of the significant progress made in the development and application of semantic segmentation tasks, there has been increasing attention towards improving the robustness of segmentation models against natural degradation factors (e.g., rain streaks) or artificially attack factors (e.g., adversarial attack). Whereas, most existing methods are designed to address a single degradation factor and are tailored to specific application scenarios. In this work, we present the first attempt to improve the robustness of semantic segmentation tasks by simultaneously handling different types of degradation factors. Specifically, we introduce the Preprocessing Enhanced Adversarial Robust Learning (PEARL) framework based on the analysis of our proposed Naive Adversarial Training (NAT) framework. Our approach effectively handles both rain streaks and adversarial perturbation by transferring the robustness of the segmentation model to the image derain model. Furthermore, as opposed to the commonly used Negative Adversarial Attack (NAA), we design the Auxiliary Mirror Attack (AMA) to introduce positive information prior to the training of the PEARL framework, which improves defense capability and segmentation performance. Our extensive experiments and ablation studies based on different derain methods and segmentation models have demonstrated the significant performance improvement of PEARL with AMA in defense against various adversarial attacks and rain streaks while maintaining high generalization performance across different datasets.
Embracing Compact and Robust Architectures for Multi-Exposure Image Fusion
May 20, 2023In recent years, deep learning-based methods have achieved remarkable progress in multi-exposure image fusion. However, existing methods rely on aligned image pairs, inevitably generating artifacts when faced with device shaking in real-world scenarios. Moreover, these learning-based methods are built on handcrafted architectures and operations by increasing network depth or width, neglecting different exposure characteristics. As a result, these direct cascaded architectures with redundant parameters fail to achieve highly effective inference time and lead to massive computation. To alleviate these issues, in this paper, we propose a search-based paradigm, involving self-alignment and detail repletion modules for robust multi-exposure image fusion. By utilizing scene relighting and deformable convolutions, the self-alignment module can accurately align images despite camera movement. Furthermore, by imposing a hardware-sensitive constraint, we introduce neural architecture search to discover compact and efficient networks, investigating effective feature representation for fusion. We realize the state-of-the-art performance in comparison to various competitive schemes, yielding a 4.02% and 29.34% improvement in PSNR for general and misaligned scenarios, respectively, while reducing inference time by 68.1%. The source code will be available at https://github.com/LiuZhu-CV/CRMEF.
An Interactively Reinforced Paradigm for Joint Infrared-Visible Image Fusion and Saliency Object Detection
May 17, 2023This research focuses on the discovery and localization of hidden objects in the wild and serves unmanned systems. Through empirical analysis, infrared and visible image fusion (IVIF) enables hard-to-find objects apparent, whereas multimodal salient object detection (SOD) accurately delineates the precise spatial location of objects within the picture. Their common characteristic of seeking complementary cues from different source images motivates us to explore the collaborative relationship between Fusion and Salient object detection tasks on infrared and visible images via an Interactively Reinforced multi-task paradigm for the first time, termed IRFS. To the seamless bridge of multimodal image fusion and SOD tasks, we specifically develop a Feature Screening-based Fusion subnetwork (FSFNet) to screen out interfering features from source images, thereby preserving saliency-related features. After generating the fused image through FSFNet, it is then fed into the subsequent Fusion-Guided Cross-Complementary SOD subnetwork (FC$^2$Net) as the third modality to drive the precise prediction of the saliency map by leveraging the complementary information derived from the fused image. In addition, we develop an interactive loop learning strategy to achieve the mutual reinforcement of IVIF and SOD tasks with a shorter training period and fewer network parameters. Comprehensive experiment results demonstrate that the seamless bridge of IVIF and SOD mutually enhances their performance, and highlights their superiority.
NFI$_2$: Learning Noise-Free Illuminance-Interpolator for Unsupervised Low-Light Image Enhancement
May 17, 2023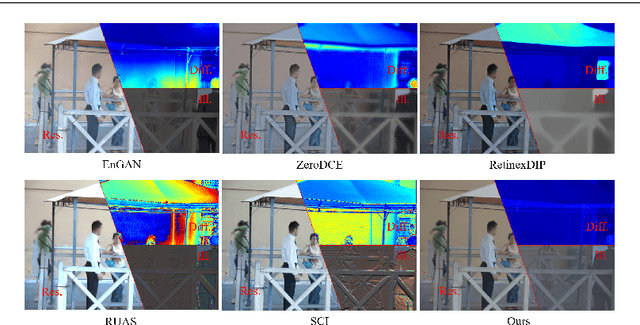
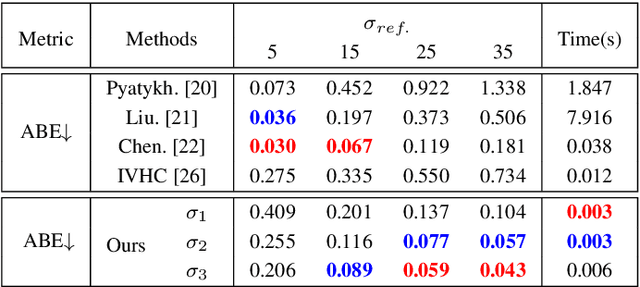
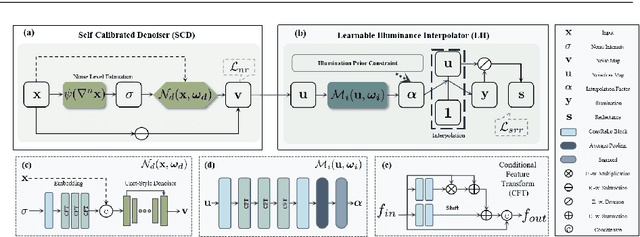
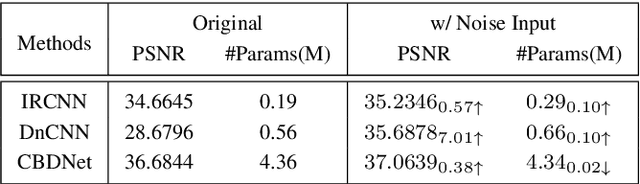
Low-light situations severely restrict the pursuit of aesthetic quality in consumer photography. Although many efforts are devoted to designing heuristics, it is generally mired in a shallow spiral of tedium, such as piling up complex network architectures and empirical strategies. How to delve into the essential physical principles of illumination compensation has been neglected. Following the way of simplifying the complexity, this paper innovatively proposes a simple and efficient Noise-Free Illumination Interpolator (NFI$_2$). According to the constraint principle of illuminance and reflectance within a limited dynamic range, as a prior knowledge in the recovery process, we construct a learnable illuminance interpolator and thereby compensating for non-uniform lighting. With the intention of adapting denoising without annotated data, we design a self-calibrated denoiser with the intrinsic image properties to acquire noise-free low-light images. Starting from the properties of natural image manifolds, a self-regularized recovery loss is introduced as a way to encourage more natural and realistic reflectance map. The model architecture and training losses, guided by prior knowledge, complement and benefit each other, forming a powerful unsupervised leaning framework. Comprehensive experiments demonstrate that the proposed algorithm produces competitive qualitative and quantitative results while maintaining favorable generalization capability in unknown real-world scenarios.
Bi-level Dynamic Learning for Jointly Multi-modality Image Fusion and Beyond
May 11, 2023Recently, multi-modality scene perception tasks, e.g., image fusion and scene understanding, have attracted widespread attention for intelligent vision systems. However, early efforts always consider boosting a single task unilaterally and neglecting others, seldom investigating their underlying connections for joint promotion. To overcome these limitations, we establish the hierarchical dual tasks-driven deep model to bridge these tasks. Concretely, we firstly construct an image fusion module to fuse complementary characteristics and cascade dual task-related modules, including a discriminator for visual effects and a semantic network for feature measurement. We provide a bi-level perspective to formulate image fusion and follow-up downstream tasks. To incorporate distinct task-related responses for image fusion, we consider image fusion as a primary goal and dual modules as learnable constraints. Furthermore, we develop an efficient first-order approximation to compute corresponding gradients and present dynamic weighted aggregation to balance the gradients for fusion learning. Extensive experiments demonstrate the superiority of our method, which not only produces visually pleasant fused results but also realizes significant promotion for detection and segmentation than the state-of-the-art approaches.
Modality-Invariant Representation for Infrared and Visible Image Registration
Apr 12, 2023Since the differences in viewing range, resolution and relative position, the multi-modality sensing module composed of infrared and visible cameras needs to be registered so as to have more accurate scene perception. In practice, manual calibration-based registration is the most widely used process, and it is regularly calibrated to maintain accuracy, which is time-consuming and labor-intensive. To cope with these problems, we propose a scene-adaptive infrared and visible image registration. Specifically, in regard of the discrepancy between multi-modality images, an invertible translation process is developed to establish a modality-invariant domain, which comprehensively embraces the feature intensity and distribution of both infrared and visible modalities. We employ homography to simulate the deformation between different planes and develop a hierarchical framework to rectify the deformation inferred from the proposed latent representation in a coarse-to-fine manner. For that, the advanced perception ability coupled with the residual estimation conducive to the regression of sparse offsets, and the alternate correlation search facilitates a more accurate correspondence matching. Moreover, we propose the first ground truth available misaligned infrared and visible image dataset, involving three synthetic sets and one real-world set. Extensive experiments validate the effectiveness of the proposed method against the state-of-the-arts, advancing the subsequent applications.
Practical Exposure Correction: Great Truths Are Always Simple
Dec 29, 2022Improving the visual quality of the given degraded observation by correcting exposure level is a fundamental task in the computer vision community. Existing works commonly lack adaptability towards unknown scenes because of the data-driven patterns (deep networks) and limited regularization (traditional optimization), and they usually need time-consuming inference. These two points heavily limit their practicability. In this paper, we establish a Practical Exposure Corrector (PEC) that assembles the characteristics of efficiency and performance. To be concrete, we rethink the exposure correction to provide a linear solution with exposure-sensitive compensation. Around generating the compensation, we introduce an exposure adversarial function as the key engine to fully extract valuable information from the observation. By applying the defined function, we construct a segmented shrinkage iterative scheme to generate the desired compensation. Its shrinkage nature supplies powerful support for algorithmic stability and robustness. Extensive experimental evaluations fully reveal the superiority of our proposed PEC. The code is available at https://rsliu.tech/PEC.
Breaking Free from Fusion Rule: A Fully Semantic-driven Infrared and Visible Image Fusion
Nov 22, 2022Infrared and visible image fusion plays a vital role in the field of computer vision. Previous approaches make efforts to design various fusion rules in the loss functions. However, these experimental designed fusion rules make the methods more and more complex. Besides, most of them only focus on boosting the visual effects, thus showing unsatisfactory performance for the follow-up high-level vision tasks. To address these challenges, in this letter, we develop a semantic-level fusion network to sufficiently utilize the semantic guidance, emancipating the experimental designed fusion rules. In addition, to achieve a better semantic understanding of the feature fusion process, a fusion block based on the transformer is presented in a multi-scale manner. Moreover, we devise a regularization loss function, together with a training strategy, to fully use semantic guidance from the high-level vision tasks. Compared with state-of-the-art methods, our method does not depend on the hand-crafted fusion loss function. Still, it achieves superior performance on visual quality along with the follow-up high-level vision tasks.