 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA-IC3: Learning-Guided Adaptive Inductive Generalization for Hardware Model Checking
Apr 23, 2026The IC3 algorithm represents the state-of-the-art (SOTA) hardware model checking technique, owing to its robust performance and scalability. A significant body of research has focused on enhancing the solving efficiency of the IC3 algorithm, with particular attention to the inductive generalization process: a critical phase wherein the algorithm seeks to generalize a counterexample to inductiveness (CTI), which typically is a state leading to a bad state, into a broader set of states. This inductive generalization is a primary source of clauses in IC3 and thus plays a pivotal role in determining the overall effectiveness of the algorithm. Despite its importance, existing approaches often rely on fixed inductive generalization strategies, overlooking the dynamic and context-sensitive nature of the verification environment in which spurious counterexamples arise. This rigidity can limit the quality of generated clauses and, consequently, the performance of IC3. To address this limitation, we propose a lightweight machine-learning-based framework that dynamically selects appropriate inductive generalization strategies in response to the evolving verification context. Specifically, we employ a multi-armed bandit (MAB) algorithm to adaptively choose inductive generalization strategies based on real-time feedback from the verification process. The agent is updated by evaluating the quality of generalization outcomes, thereby refining its strategy selection over time. Empirical evaluation on a benchmark suite comprising 914 instances, primarily drawn from the latest HWMCC collection, demonstrates the efficacy of our approach. When implemented on the state-of-the-art model checker rIC3, our method solves 26 to 50 more cases than the baselines and improves the PAR-2 score by 194.72 to 389.29.
EvolveGen: Algorithmic Level Hardware Model Checking Benchmark Generation through Reinforcement Learning
Feb 26, 2026Progress in hardware model checking depends critically on high-quality benchmarks. However, the community faces a significant benchmark gap: existing suites are limited in number, often distributed only in representations such as BTOR2 without access to the originating register-transfer-level (RTL) designs, and biased toward extreme difficulty where instances are either trivial or intractable. These limitations hinder rigorous evaluation of new verification techniques and encourage overfitting of solver heuristics to a narrow set of problems. To address this, we introduce EvolveGen, a framework for generating hardware model checking benchmarks by combining reinforcement learning (RL) with high-level synthesis (HLS). Our approach operates at an algorithmic level of abstraction in which an RL agent learns to construct computation graphs. By compiling these graphs under different synthesis directives, we produce pairs of functionally equivalent but structurally distinct hardware designs, inducing challenging model checking instances. Solver runtime is used as the reward signal, enabling the agent to autonomously discover and generate small-but-hard instances that expose solver-specific weaknesses. Experiments show that EvolveGen efficiently creates a diverse benchmark set in standard formats (e.g., AIGER and BTOR2) and effectively reveals performance bottlenecks in state-of-the-art model checkers.
Mining Rules Incrementally over Large Knowledge Bases
Apr 20, 2019
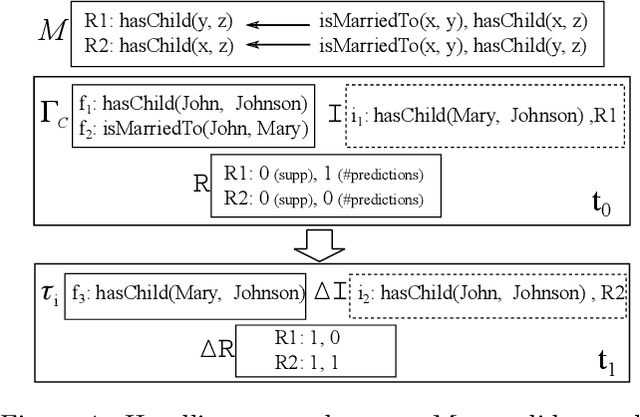
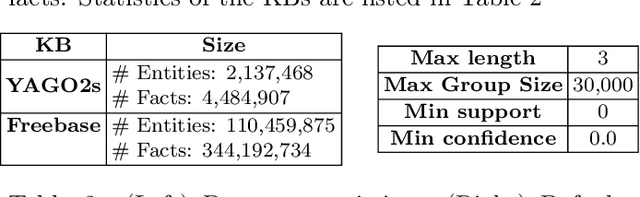
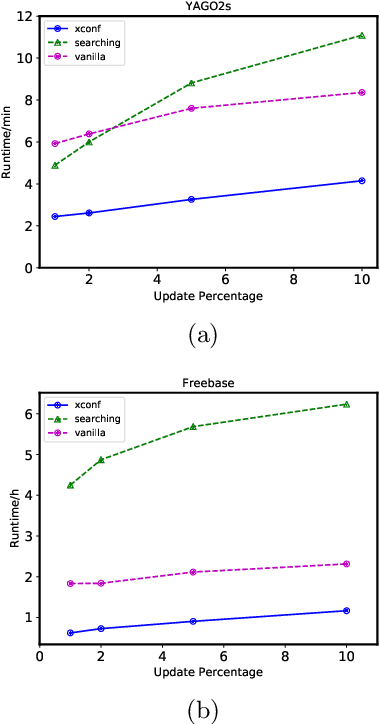
Multiple web-scale Knowledge Bases, e.g., Freebase, YAGO, NELL, have been constructed using semi-supervised or unsupervised information extraction techniques and many of them, despite their large sizes, are continuously growing. Much research effort has been put into mining inference rules from knowledge bases. To address the task of rule mining over evolving web-scale knowledge bases, we propose a parallel incremental rule mining framework. Our approach is able to efficiently mine rules based on the relational model and apply updates to large knowledge bases; we propose an alternative metric that reduces computation complexity without compromising quality; we apply multiple optimization techniques that reduce runtime by more than 2 orders of magnitude. Experiments show that our approach efficiently scales to web-scale knowledge bases and saves over 90% time compared to the state-of-the-art batch rule mining system. We also apply our optimization techniques to the batch rule mining algorithm, reducing runtime by more than half compared to the state-of-the-art. To the best of our knowledge, our incremental rule mining system is the first that handles updates to web-scale knowledge bases.