 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dual-branch Network for Infrared and Visible Image Fusion
Jan 24, 2021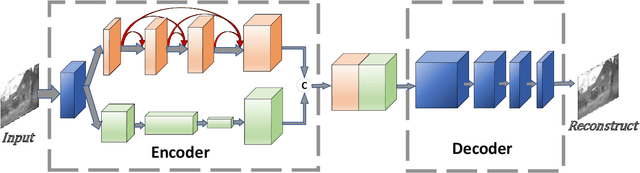
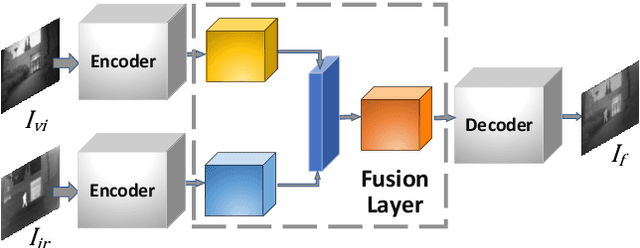
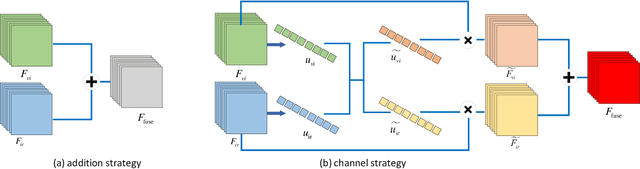

Deep learning is a rapidly developing approach in the field of infrared and visible image fusion. In this context, the use of dense blocks in deep networks significantly improves the utilization of shallow information, and the combination of the Generative Adversarial Network (GAN) also improves the fusion performance of two source images. We propose a new method based on dense blocks and GANs , and we directly insert the input image-visible light image in each layer of the entire network. We use SSIM and gradient loss functions that are more consistent with perception instead of mean square error loss. After the adversarial training between the generator and the discriminator, we show that a trained end-to-end fusion network -- the generator network -- is finally obtained. Our experiments show that the fused images obtained by our approach achieve good score based on multiple evaluation indicators. Further, our fused images have better visual effects in multiple sets of contrasts, which are more satisfying to human visual perception.
Self-grouping Convolutional Neural Networks
Sep 29, 2020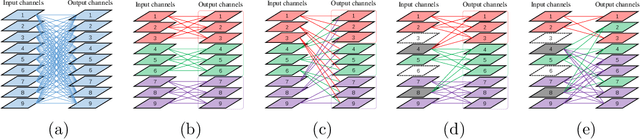
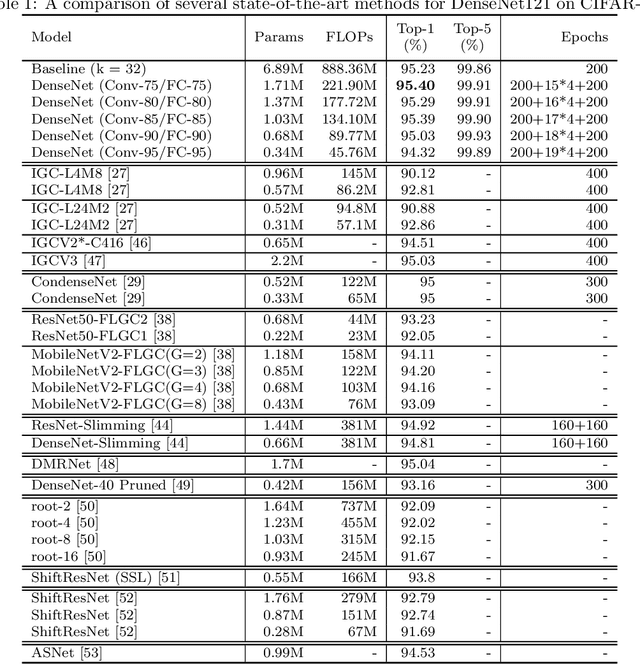
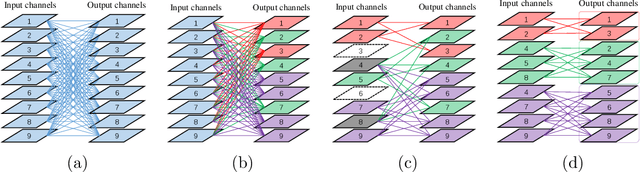
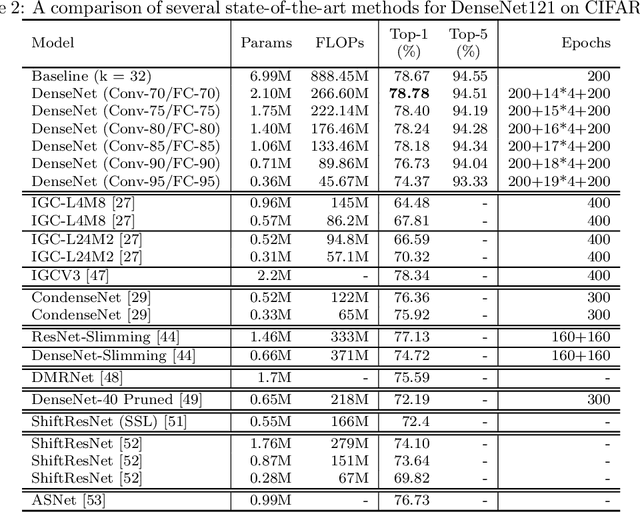
Although group convolution operators are increasingly used in deep convolutional neural networks to improve the computational efficiency and to reduce the number of parameters, most existing methods construct their group convolution architectures by a predefined partitioning of the filters of each convolutional layer into multiple regular filter groups with an equal spatial group size and data-independence, which prevents a full exploitation of their potential. To tackle this issue, we propose a novel method of designing self-grouping convolutional neural networks, called SG-CNN, in which the filters of each convolutional layer group themselves based on the similarity of their importance vectors. Concretely, for each filter, we first evaluate the importance value of their input channels to identify the importance vectors, and then group these vectors by clustering. Using the resulting \emph{data-dependent} centroids, we prune the less important connections, which implicitly minimizes the accuracy loss of the pruning, thus yielding a set of \emph{diverse} group convolution filters. Subsequently, we develop two fine-tuning schemes, i.e. (1) both local and global fine-tuning and (2) global only fine-tuning, which experimentally deliver comparable results, to recover the recognition capacity of the pruned network. Comprehensive experiments carried out on the CIFAR-10/100 and ImageNet datasets demonstrate that our self-grouping convolution method adapts to various state-of-the-art CNN architectures, such as ResNet and DenseNet, and delivers superior performance in terms of compression ratio, speedup and recognition accuracy. We demonstrate the ability of SG-CNN to generalise by transfer learning, including domain adaption and object detection, showing competitive results. Our source code is available at https://github.com/QingbeiGuo/SG-CNN.git.
DD-CNN: Depthwise Disout Convolutional Neural Network for Low-complexity Acoustic Scene Classification
Jul 25, 2020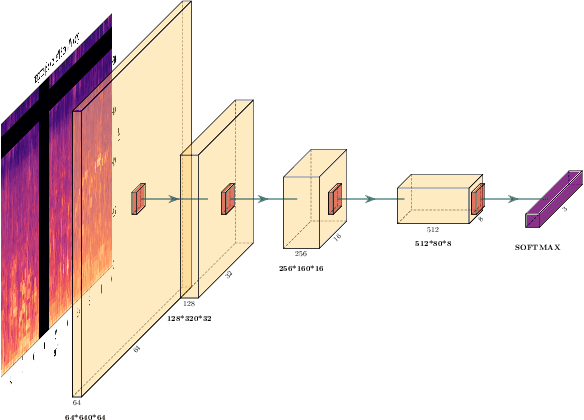
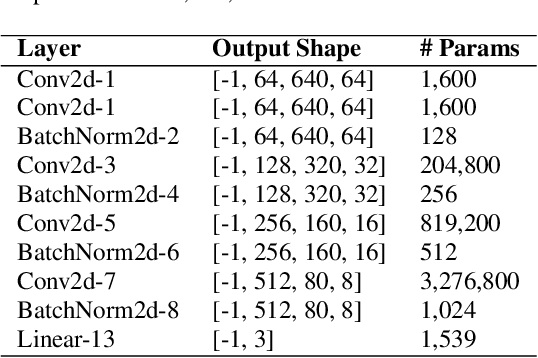
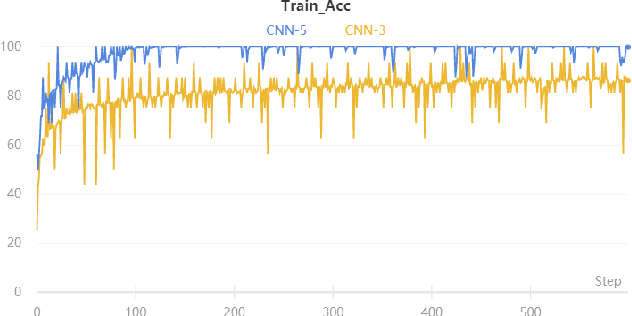
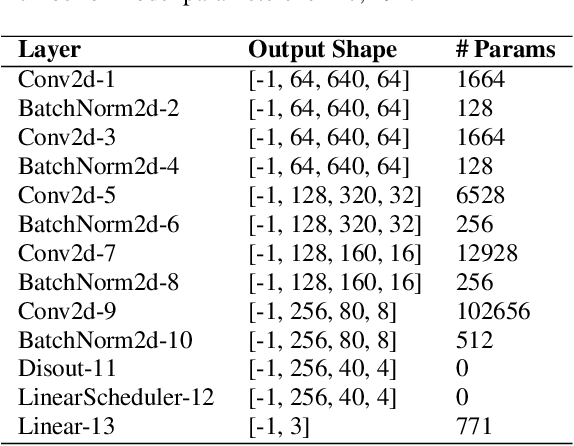
This paper presents a Depthwise Disout Convolutional Neural Network (DD-CNN) for the detection and classification of urban acoustic scenes. Specifically, we use log-mel as feature representations of acoustic signals for the inputs of our network. In the proposed DD-CNN, depthwise separable convolution is used to reduce the network complexity. Besides, SpecAugment and Disout are used for further performance boosting. Experimental results demonstrate that our DD-CNN can learn discriminative acoustic characteristics from audio fragments and effectively reduce the network complexity. Our DD-CNN was used for the low-complexity acoustic scene classification task of the DCASE2020 Challenge, which achieves 92.04% accuracy on the validation set.
NestFuse: An Infrared and Visible Image Fusion Architecture based on Nest Connection and Spatial/Channel Attention Models
Jul 11, 2020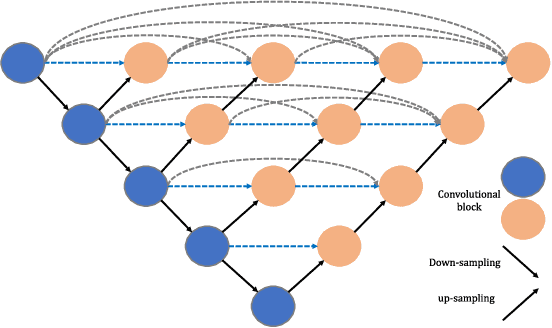



In this paper we propose a novel method for infrared and visible image fusion where we develop nest connection-based network and spatial/channel attention models. The nest connection-based network can preserve significant amounts of information from input data in a multi-scale perspective. The approach comprises three key elements: encoder, fusion strategy and decoder respectively. In our proposed fusion strategy, spatial attention models and channel attention models are developed that describe the importance of each spatial position and of each channel with deep features. Firstly, the source images are fed into the encoder to extract multi-scale deep features. The novel fusion strategy is then developed to fuse these features for each scale. Finally, the fused image is reconstructed by the nest connection-based decoder. Experiments are performed on publicly available datasets. These exhibit that our proposed approach has better fusion performance than other state-of-the-art methods. This claim is justified through both subjective and objective evaluation. The code of our fusion method is available at https://github.com/hli1221/imagefusion-nestfuse
Affine Non-negative Collaborative Representation Based Pattern Classification
Jul 10, 2020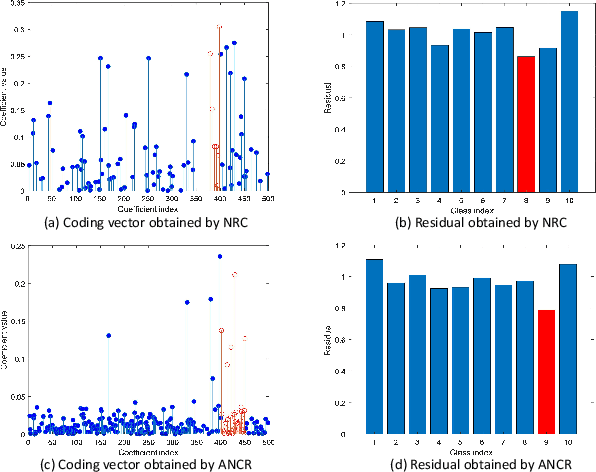



During the past decade, representation-based classification methods have received considerable attention in pattern recognition. In particular, the recently proposed non-negative representation based classification (NRC) method has been reported to achieve promising results in a wide range of classification tasks. However, NRC has two major drawbacks. First, there is no regularization term in the formulation of NRC, which may result in unstable solution and misclassification. Second, NRC ignores the fact that data usually lies in a union of multiple affine subspaces, rather than linear subspaces in practical applications. To address the above issues, this paper presents an affine non-negative collaborative representation (ANCR) model for pattern classification. To be more specific, ANCR imposes a regularization term on the coding vector. Moreover, ANCR introduces an affine constraint to better represent the data from affine subspaces. The experimental results on several benchmarking datasets demonstrate the merits of the proposed ANCR method. The source code of our ANCR is publicly available at https://github.com/yinhefeng/ANCR.
AFAT: Adaptive Failure-Aware Tracker for Robust Visual Object Tracking
May 27, 2020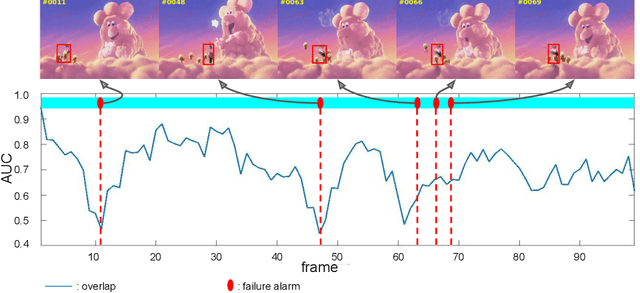
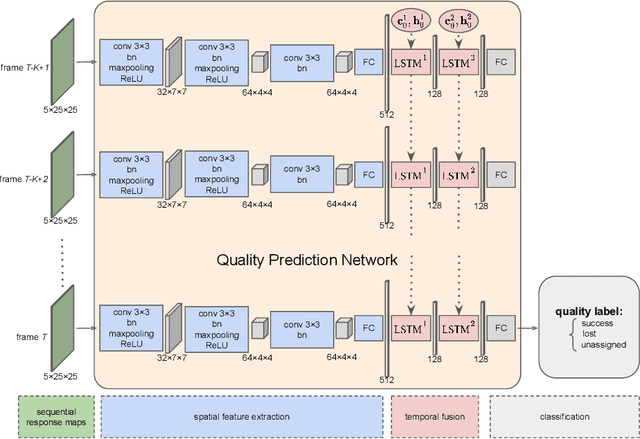
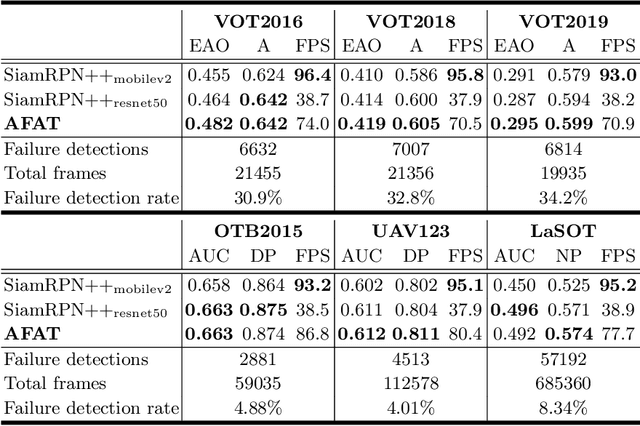
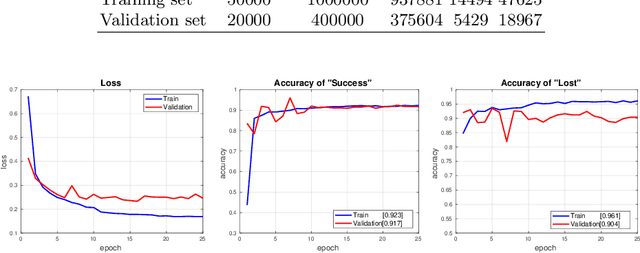
Siamese approaches have achieved promising performance in visual object tracking recently. The key to the success of Siamese trackers is to learn appearance-invariant feature embedding functions via pair-wise offline training on large-scale video datasets. However, the Siamese paradigm uses one-shot learning to model the online tracking task, which impedes online adaptation in the tracking process. Additionally, the uncertainty of an online tracking response is not measured, leading to the problem of ignoring potential failures. In this paper, we advocate online adaptation in the tracking stage. To this end, we propose a failure-aware system, realised by a Quality Prediction Network (QPN), based on convolutional and LSTM modules in the decision stage, enabling online reporting of potential tracking failures. Specifically, sequential response maps from previous successive frames as well as current frame are collected to predict the tracking confidence, realising spatio-temporal fusion in the decision level. In addition, we further provide an Adaptive Failure-Aware Tracker (AFAT) by combing the state-of-the-art Siamese trackers with our system. The experimental results obtained on standard benchmarking datasets demonstrate the effectiveness of the proposed failure-aware system and the merits of our AFAT tracker, with outstanding and balanced performance in both accuracy and speed.
Learning efficient structured dictionary for image classification
Feb 09, 2020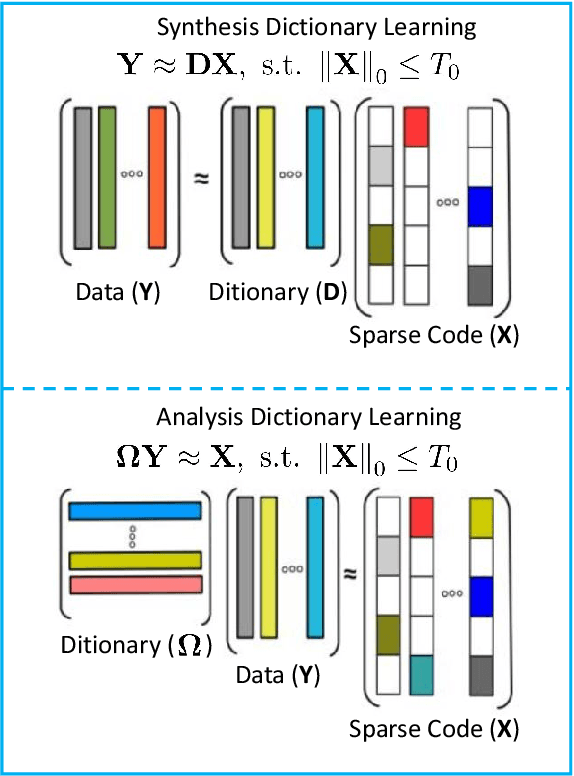
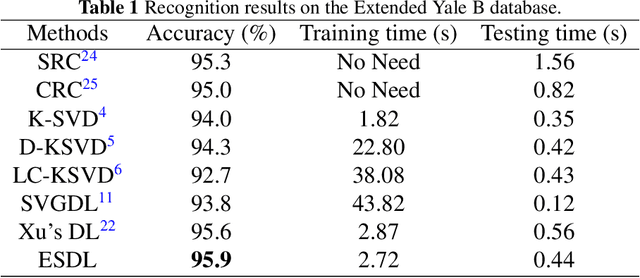

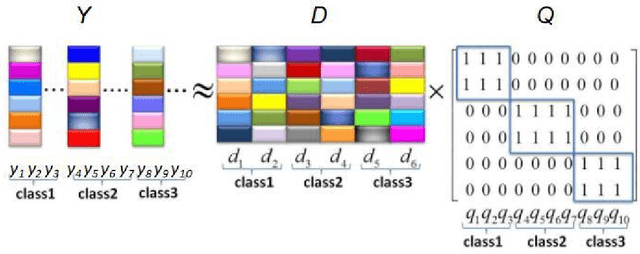
Recent years have witnessed the success of dictionary learning (DL) based approaches in the domain of pattern classification. In this paper, we present an efficient structured dictionary learning (ESDL) method which takes both the diversity and label information of training samples into account. Specifically, ESDL introduces alternative training samples into the process of dictionary learning. To increase the discriminative capability of representation coefficients for classification, an ideal regularization term is incorporated into the objective function of ESDL. Moreover, in contrast with conventional DL approaches which impose computationally expensive L1-norm constraint on the coefficient matrix, ESDL employs L2-norm regularization term. Experimental results on benchmark databases (including four face databases and one scene dataset) demonstrate that ESDL outperforms previous DL approaches. More importantly, ESDL can be applied in a wide range of pattern classification tasks. The demo code of our proposed ESDL will be available at https://github.com/li-zi-qi/ESDL.
Improved dual channel pulse coupled neural network and its application to multi-focus image fusion
Feb 04, 2020



This paper presents an improved dual channel pulse coupled neural network (IDC-PCNN) model for image fusion. The model can overcome some defects of standard PCNN model. In this fusion scheme, the multiplication rule is replaced by addition rule in the information fusion pool of dual channel PCNN (DC-PCNN) model. Meanwhile the sum of modified Laplacian (SML) measure is adopted, which is better than other focus measures. This method not only inherits the good characteristics of the standard PCNN model but also enhances the computing efficiency and fusion quality. The performance of the proposed method is evaluated by using four criteria including average cross entropy, root mean square error, peak value signal to noise ratio and structure similarity index. Comparative studies show that the proposed fusion algorithm outperforms the standard PCNN method and the DC-PCNN method.
Face Verification via learning the kernel matrix
Jan 21, 2020
The kernel function is introduced to solve the nonlinear pattern recognition problem. The advantage of a kernel method often depends critically on a proper choice of the kernel function. A promising approach is to learn the kernel from data automatically. Over the past few years, some methods which have been proposed to learn the kernel have some limitations: learning the parameters of some prespecified kernel function and so on. In this paper, the nonlinear face verification via learning the kernel matrix is proposed. A new criterion is used in the new algorithm to avoid inverting the possibly singular within-class which is a computational problem. The experimental results obtained on the facial database XM2VTS using the Lausanne protocol show that the verification performance of the new method is superior to that of the primary method Client Specific Kernel Discriminant Analysis (CSKDA). The method CSKDA needs to choose a proper kernel function through many experiments, while the new method could learn the kernel from data automatically which could save a lot of time and have the robust performance.
Multiplication fusion of sparse and collaborative-competitive representation for image classification
Jan 20, 2020
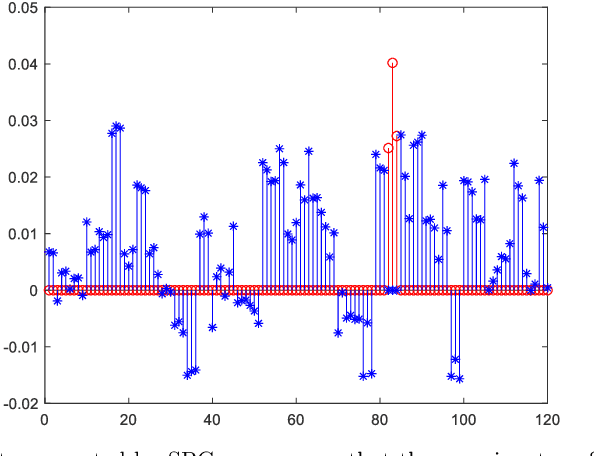
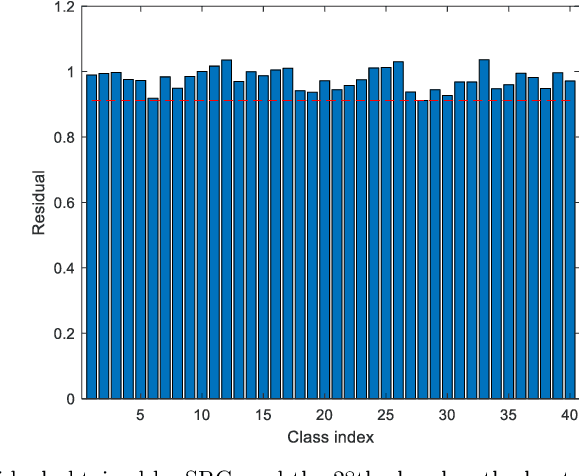
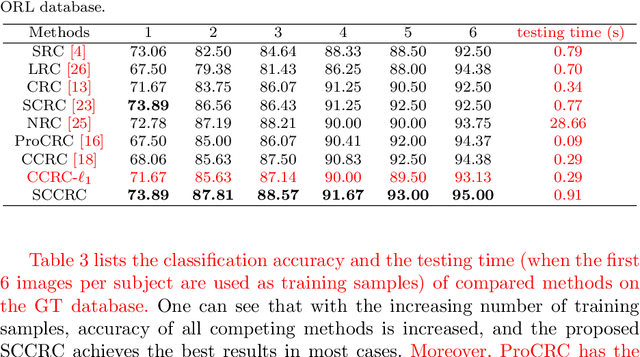
Representation based classification methods have become a hot research topic during the past few years, and the two most prominent approaches are sparse representation based classification (SRC) and collaborative representation based classification (CRC). CRC reveals that it is the collaborative representation rather than the sparsity that makes SRC successful. Nevertheless, the dense representation of CRC may not be discriminative which will degrade its performance for classification tasks. To alleviate this problem to some extent, we propose a new method called sparse and collaborative-competitive representation based classification (SCCRC) for image classification. Firstly, the coefficients of the test sample are obtained by SRC and CCRC, respectively. Then the fused coefficient is derived by multiplying the coefficients of SRC and CCRC. Finally, the test sample is designated to the class that has the minimum residual. Experimental results on several benchmark databases demonstrate the efficacy of our proposed SCCRC. The source code of SCCRC is accessible at https://github.com/li-zi-qi/SCCRC.