 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Concatenation Hashing with Sparse Constraint for Cross-Modal Retrieval
Mar 26, 2019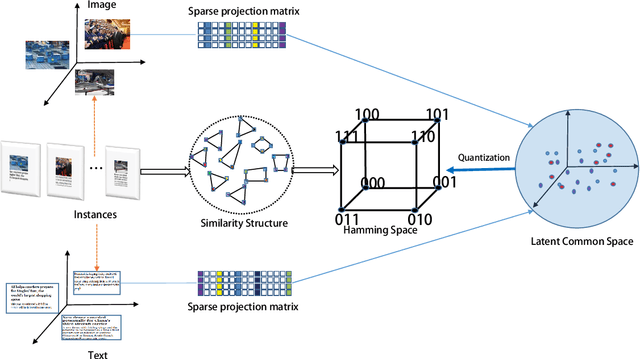
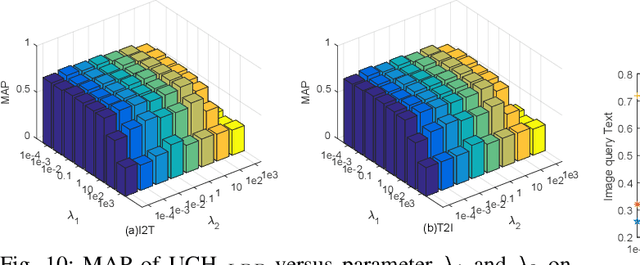
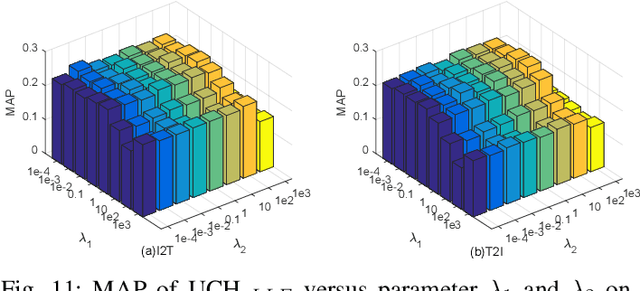
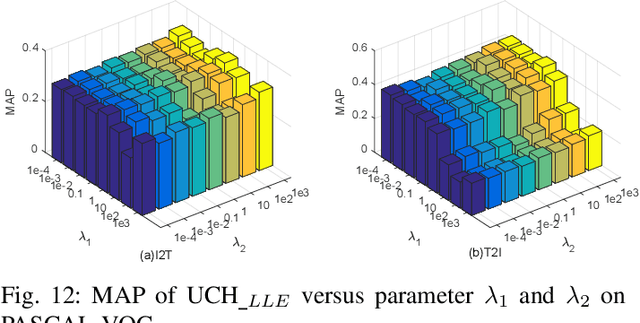
With the advantage of low storage cost and high efficiency, hashing learning has received much attention in retrieval field. As multiple modal data representing a common object semantically are complementary, many works focus on learning unified binary codes. However, these works ignore the importance of manifold structre among data. In fact, it is still an interesting problem to directly preserve the local manifold structure among samples in hamming space. Since different modalities are isomerous, we adopt the concatenated feature of multiple modality feature to represent original object. In our framework, Locally Linear Embedding and Locality Preserving Projection are introduced to reconstruct the manifold structure of original space in the Hamming space. Besides, The L21-norm regularization are imposed on the projection matrices to further exploit the discriminative features for different modalities simultaneously. Extensive experiments are performed to evaluate the proposed method, dubbed Unsupervised Concatenation Hashing (UCH), on the three publicly available datasets and the experimental results show the superior performance of UCH outperforming most of state-of-the-art unsupervised hashing models.
Non-negative representation based discriminative dictionary learning for face recognition
Mar 19, 2019



In this paper, we propose a non-negative representation based discriminative dictionary learning algorithm (NRDL) for multicategory face classification. In contrast to traditional dictionary learning methods, NRDL investigates the use of non-negative representation (NR), which contributes to learning discriminative dictionary atoms. In order to make the learned dictionary more suitable for classification, NRDL seamlessly incorporates nonnegative representation constraint, discriminative dictionary learning and linear classifier training into a unified model. Specifically, NRDL introduces a positive constraint on representation matrix to find distinct atoms from heterogeneous training samples, which results in sparse and discriminative representation. Moreover, a discriminative dictionary encouraging function is proposed to enhance the uniqueness of class-specific sub-dictionaries. Meanwhile, an inter-class incoherence constraint and a compact graph based regularization term are constructed to respectively improve the discriminability of learned classifier. Experimental results on several benchmark face data sets verify the advantages of our NRDL algorithm over the state-of-the-art dictionary learning methods.
Fisher Discriminative Least Square Regression with Self-Adaptive Weighting for Face Recognition
Mar 19, 2019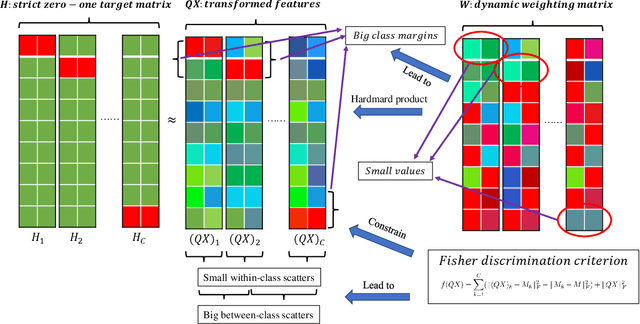
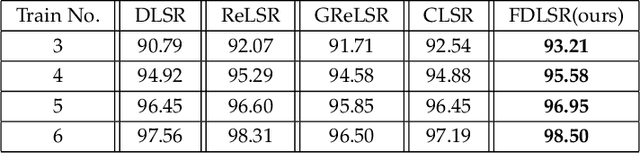

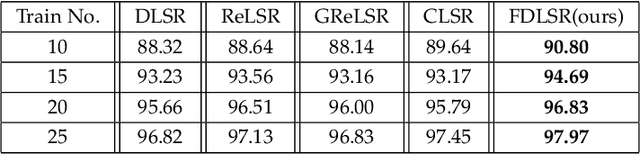
As a supervised classification method, least square regression (LSR) has shown promising performance in multiclass face recognition tasks. However, the latest LSR based classification methods mainly focus on learning a relaxed regression target to replace traditional zero-one label matrix while ignoring the discriminability of transformed features. Based on the assumption that the transformed features of samples from the same class have similar structure while those of samples from different classes are uncorrelated, in this paper we propose a novel discriminative LSR method based on the Fisher discrimination criterion (FDLSR), where the projected features have small within-class scatter and large inter-class scatter simultaneously. Moreover, different from other methods, we explore relax regression from the view of transformed features rather than the regression targets. Specifically, we impose a dynamic non-negative weight matrix on the transformed features to enlarge the margin between the true and the false classes by self-adaptively assigning appropriate weights to different features. Above two factors can encourage the learned transformation for regression to be more discriminative and thus achieving better classification performance. Extensive experiments on various databases demonstrate that the proposed FDLSR method achieves superior performance to other state-of-the-art LSR based classification methods.
Discriminative Supervised Hashing for Cross-Modal similarity Search
Dec 06, 2018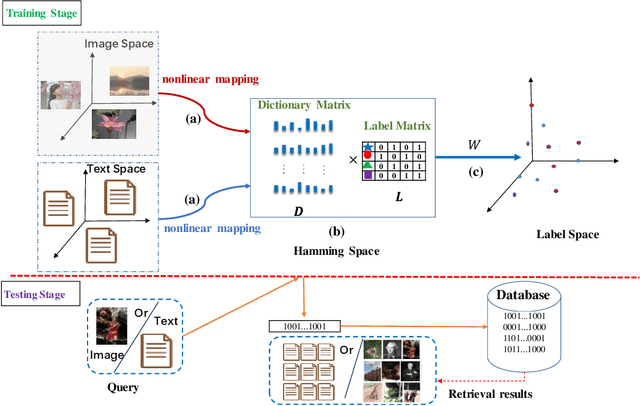
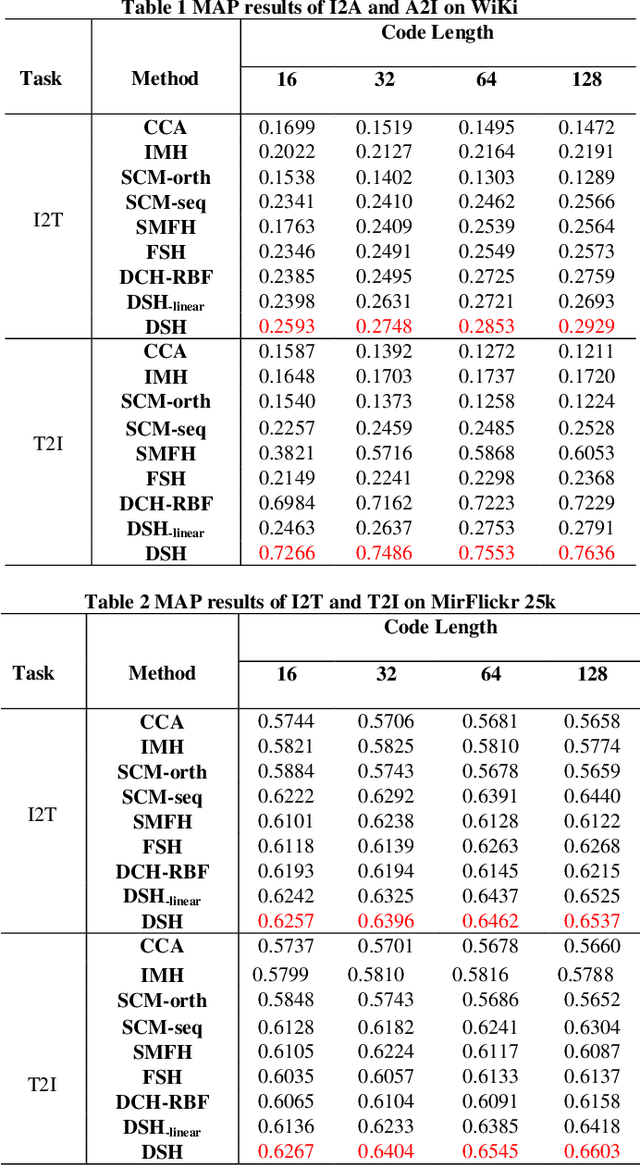
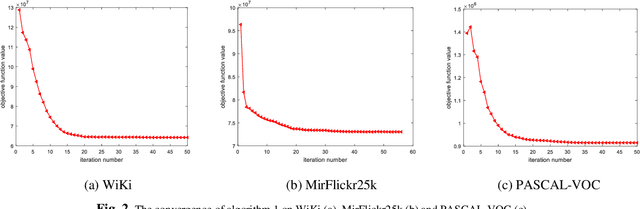
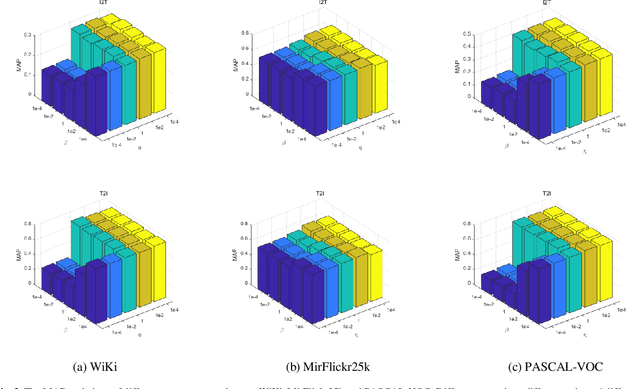
With the advantage of low storage cost and high retrieval efficiency, hashing techniques have recently been an emerging topic in cross-modal similarity search. As multiple modal data reflect similar semantic content, many researches aim at learning unified binary codes. However, discriminative hashing features learned by these methods are not adequate. This results in lower accuracy and robustness. We propose a novel hashing learning framework which jointly performs classifier learning, subspace learning and matrix factorization to preserve class-specific semantic content, termed Discriminative Supervised Hashing (DSH), to learn the discrimative unified binary codes for multi-modal data. Besides, reducing the loss of information and preserving the non-linear structure of data, DSH non-linearly projects different modalities into the common space in which the similarity among heterogeneous data points can be measured. Extensive experiments conducted on the three publicly available datasets demonstrate that the framework proposed in this paper outperforms several state-of -the-art methods.
Infrared and visible image fusion using a novel deep decomposition method
Nov 19, 2018
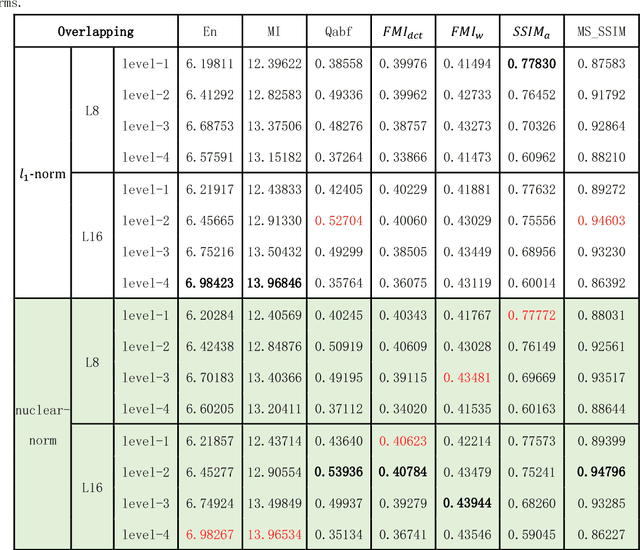
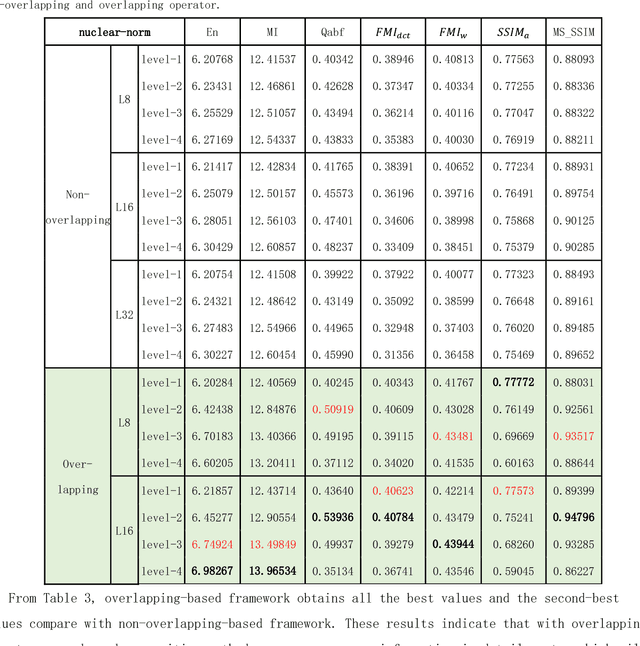
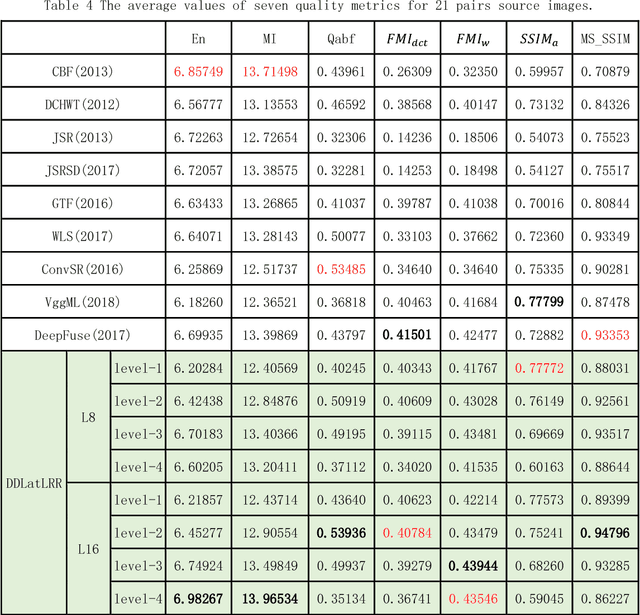
Infrared and visible image fusion is an important problem in image fusion tasks which has been applied widely in many fields. To better preserve the useful information from source images, in this paper, we propose an effective image fusion framework using a novel deep decomposition method which based on Latent Low-Rank Representation(LatLRR). And this decomposition method is also named DDLatLRR. Firstly, the LatLRR is utilized to learn a project matrix which used to extract salient features. Then, the base part and multi-level detail parts are obtained by DDLatLRR. With adaptive fusion strategies, the fused base part and the fused detail parts are reconstructed. Finally, the fused image is obtained by combine the fused base part and the detail parts. Compared with other fusion methods experimentally, the proposed algorithm has better fusion performance than state-of-the-art fusion methods in both subjective and objective evaluation. The Code of our fusion method is available at https://github.com/exceptionLi/imagefusion_deepdecomposition
Wing Loss for Robust Facial Landmark Localisation with Convolutional Neural Networks
Oct 23, 2018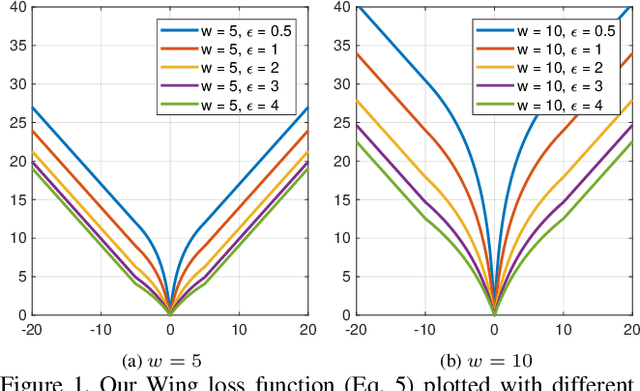
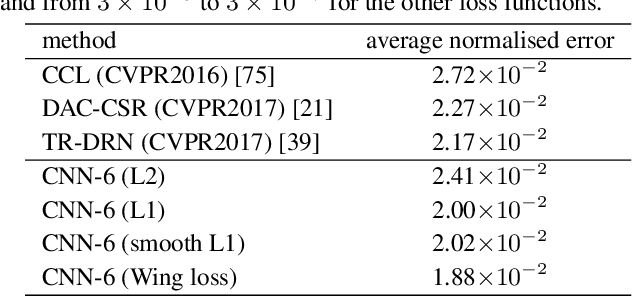
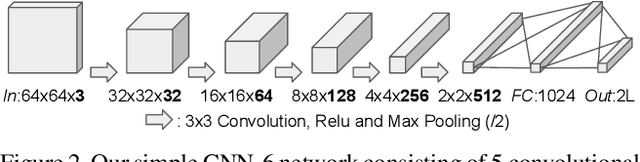
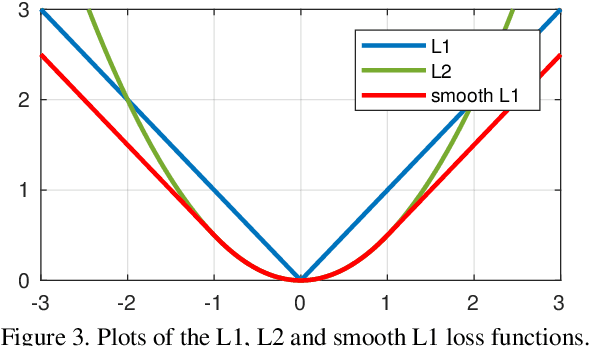
We present a new loss function, namely Wing loss, for robust facial landmark localisation with Convolutional Neural Networks (CNNs). We first compare and analyse different loss functions including L2, L1 and smooth L1. The analysis of these loss functions suggests that, for the training of a CNN-based localisation model, more attention should be paid to small and medium range errors. To this end, we design a piece-wise loss function. The new loss amplifies the impact of errors from the interval (-w, w) by switching from L1 loss to a modified logarithm function. To address the problem of under-representation of samples with large out-of-plane head rotations in the training set, we propose a simple but effective boosting strategy, referred to as pose-based data balancing. In particular, we deal with the data imbalance problem by duplicating the minority training samples and perturbing them by injecting random image rotation, bounding box translation and other data augmentation approaches. Last, the proposed approach is extended to create a two-stage framework for robust facial landmark localisation. The experimental results obtained on AFLW and 300W demonstrate the merits of the Wing loss function, and prove the superiority of the proposed method over the state-of-the-art approaches.
Multi-focus Noisy Image Fusion using Low-Rank Representation
Oct 09, 2018
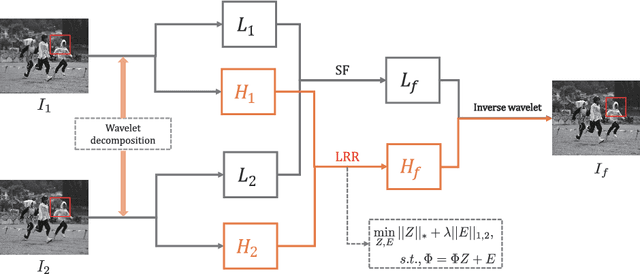
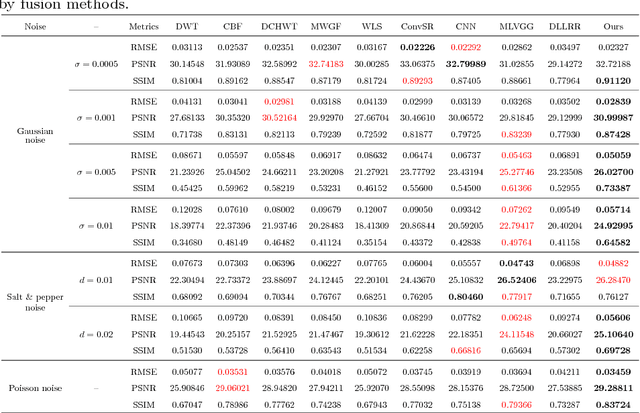
In the process of image acquisition, the noise is inevitable for source image. The multi-focus noisy image fusion is a very challenging task. However, there is no truly adaptive noisy image fusion approaches at present. As we all know, Low-Rank representation(LRR) is robust to noise and outliers. In this paper, we propose a novel fusion method based on LRR for multi-focus noisy image fusion. In the discrete wavelet transform(DWT) framework, the low frequency coefficients are fused by spatial frequency, the high frequency coefficients are fused by LRR coefficients and choose-max strategy. Finally, the fused image is obtained by inverse DWT. Experimental results demonstrate that the proposed algorithm can obtain state-of-the-art performance when the source images contain noise. The Code of our fusion method is available at https://github.com/exceptionLi/imagefusion_noisy_lrr
DenseFuse: A Fusion Approach to Infrared and Visible Images
Sep 05, 2018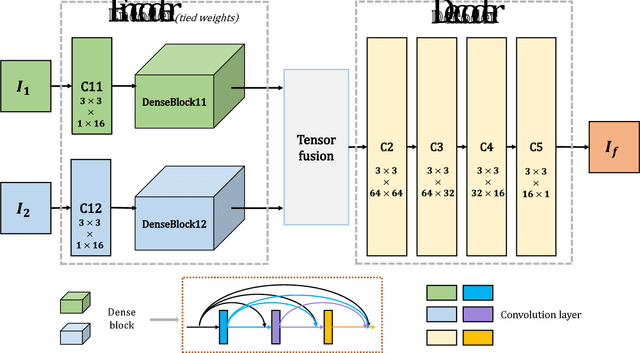
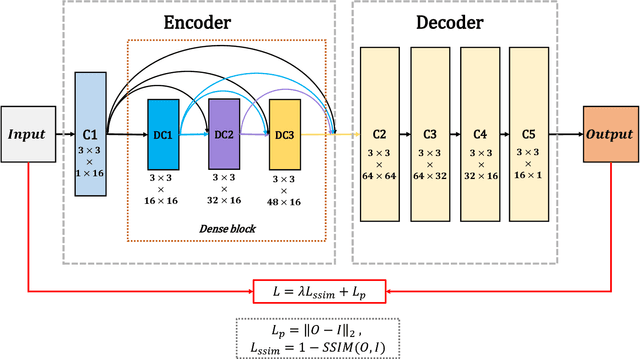
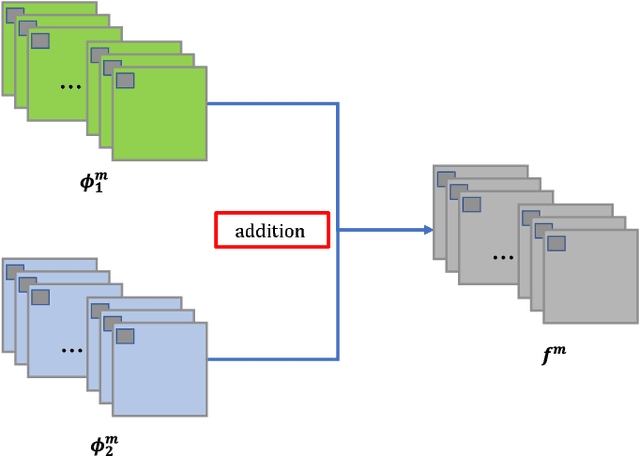
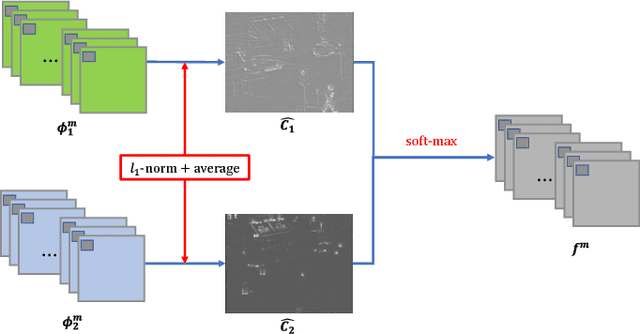
In this paper, we present a novel deep learning architecture for infrared and visible images fusion problem. In contrast to conventional convolutional networks, our encoding network is combined by convolutional neural network layer, fusion layer and dense block in which the output of each layer is connected to every other layer. We attempt to use this architecture to get more useful features from source images in encoding process. And two fusion layers are designed to fuse these features. Finally, the fused image is reconstructed by decoder. Compared with existing fusion methods, the proposed fusion method achieves state-of-the-art performance in objective and subjective assessment. Code and pre-trained models are available at https://github.com/exceptionLi/imagefusion_densefuse
Landmark Weighting for 3DMM Shape Fitting
Aug 16, 2018


Human face is a 3D object with shape and surface texture. 3D Morphable Model (3DMM) is a powerful tool for reconstructing the 3D face from a single 2D face image. In the shape fitting process, 3DMM estimates the correspondence between 2D and 3D landmarks. Most traditional 3DMM fitting methods fail to reconstruct an accurate model because face shape fitting is a difficult non-linear optimization problem. In this paper we show that landmark weighting is instrumental to improve the accuracy of shape reconstruction and propose a novel 3D Morphable Model Fitting method. Different from previous works that treat all landmarks equally, we take into consideration the estimated errors for each pair of 2D and 3D corresponding landmarks. The landmark points are weighted in the optimization cost function based on these errors. Obviously, these landmarks have different semantics because they locate on different facial components. In the context of the solution of fitting is approximated, there are deviations in landmarks matching. However, these landmarks with different semantics have different effects on reconstructing 3D faces. Thus, it is necessary to consider each landmark individually. To our knowledge, we are the first to analyze each feature point for 3D face reconstruction by 3DMM. The weight is adaptive with the estimation residuals of landmarks. Experimental results show that the proposed method significantly reduces the reconstruction error and improves the authenticity of the 3D model expression.
Learning Discriminative Hashing Codes for Cross-Modal Retrieval based on Multiorder Statistical Features
Aug 13, 2018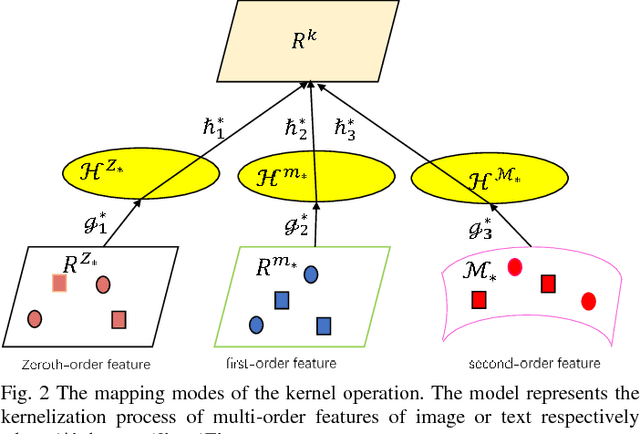
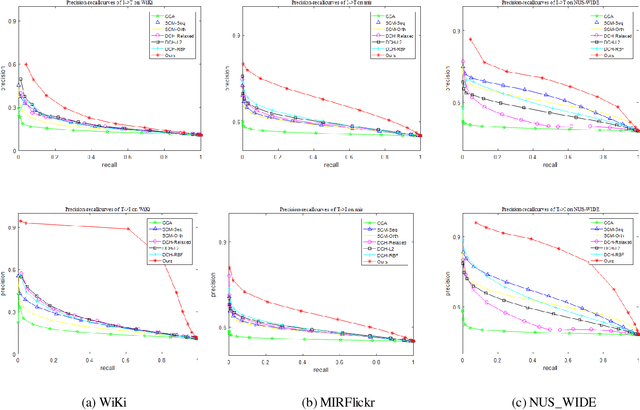
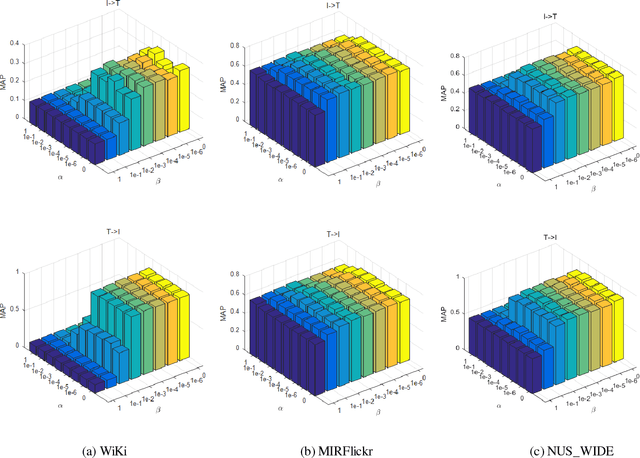
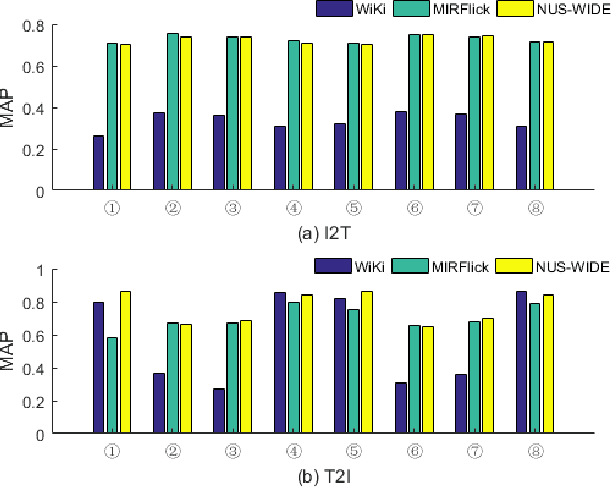
Hashing techniques have been applied broadly in large-scale retrieval tasks due to their low storage requirements and high speed of processing. Many hashing methods have shown promising performance but as they fail to exploit all structural information in learning the hashing function, they leave a scope for improvement. The paper proposes a novel discrete hashing learning framework which jointly performs classifier learning and subspace learning for cross-modal retrieval. Concretely, the framework proposed in the paper includes two stages, namely a kernelization process and a quantization process. The aim of kernelization is to learn a common subspace where heterogeneous data can be fused. The quantization process is designed to learn discriminative unified hashing codes. Extensive experiments on three publicly available datasets clearly indicate the superiority of our method compared with the state-of-the-art methods.