 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAMO: A Conditional Neural Solver for the Multi-objective Multiple Traveling Salesman Problem
Mar 19, 2026Robotic systems often require a team of robots to collectively visit multiple targets while optimizing competing objectives, such as total travel cost and makespan. This setting can be formulated as the Multi-Objective Multiple Traveling Salesman Problem (MOMTSP). Although learning-based methods have shown strong performance on the single-agent TSP and multi-objective TSP variants, they rarely address the combined challenges of multi-agent coordination and multi-objective trade-offs, which introduce dual sources of complexity. To bridge this gap, we propose CAMO, a conditional neural solver for MOMTSP that generalizes across varying numbers of targets, agents, and preference vectors, and yields high-quality approximations to the Pareto front (PF). Specifically, CAMO consists of a conditional encoder to fuse preferences into instance representations, enabling explicit control over multi-objective trade-offs, and a collaborative decoder that coordinates all agents by alternating agent selection and node selection to construct multi-agent tours autoregressively. To further improve generalization, we train CAMO with a REINFORCE-based objective over a mixed distribution of problem sizes. Extensive experiments show that CAMO outperforms both neural and conventional heuristics, achieving a closer approximation of PFs. In addition, ablation results validate the contributions of CAMO's key components, and real-world tests on a mobile robot platform demonstrate its practical applicability.
DL-DRL: A double-layer deep reinforcement learning approach for large-scale task scheduling of multi-UAV
Aug 04, 2022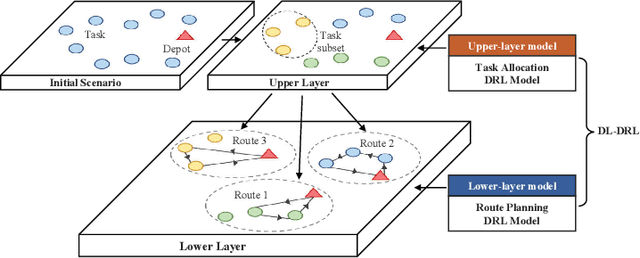
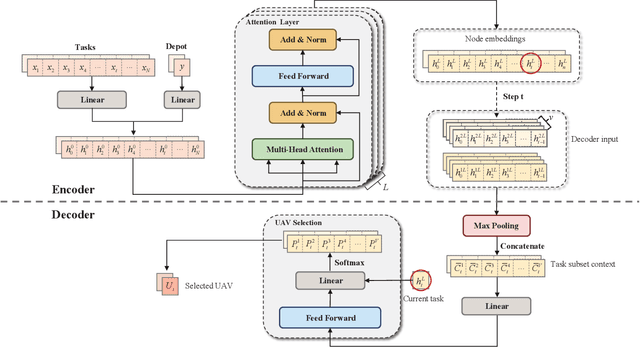
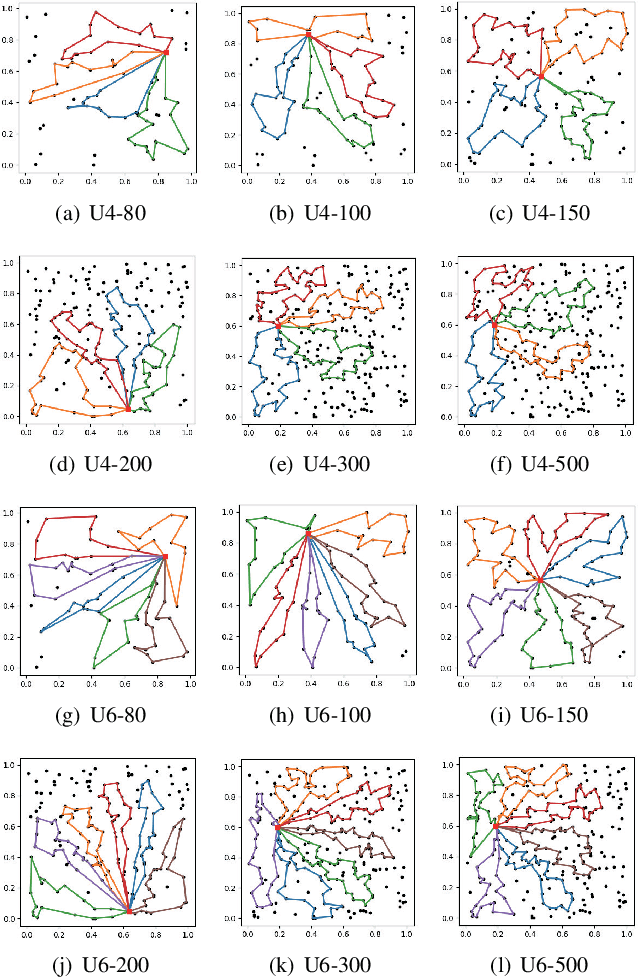
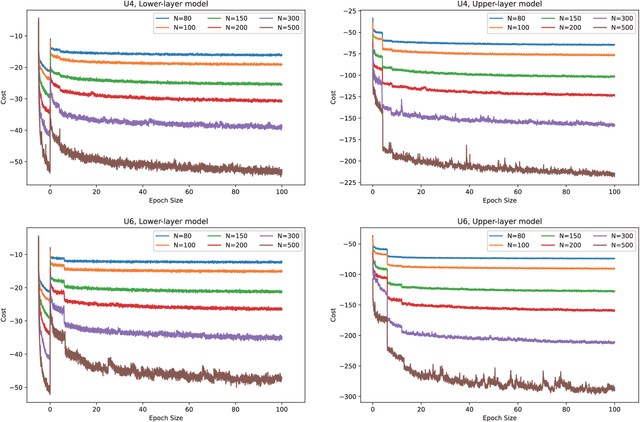
This paper studies deep reinforcement learning (DRL) for the task scheduling problem of multiple unmanned aerial vehicles (UAVs). Current approaches generally use exact and heuristic algorithms to solve the problem, while the computation time rapidly increases as the task scale grows and heuristic rules need manual design. As a self-learning method, DRL can obtain a high-quality solution quickly without hand-engineered rules. However, the huge decision space makes the training of DRL models becomes unstable in situations with large-scale tasks. In this work, to address the large-scale problem, we develop a divide and conquer-based framework (DCF) to decouple the original problem into a task allocation and a UAV route planning subproblems, which are solved in the upper and lower layers, respectively. Based on DCF, a double-layer deep reinforcement learning approach (DL-DRL) is proposed, where an upper-layer DRL model is designed to allocate tasks to appropriate UAVs and a lower-layer DRL model [i.e., the widely used attention model (AM)] is applied to generate viable UAV routes. Since the upper-layer model determines the input data distribution of the lower-layer model, and its reward is calculated via the lower-layer model during training, we develop an interactive training strategy (ITS), where the whole training process consists of pre-training, intensive training, and alternate training processes. Experimental results show that our DL-DRL outperforms mainstream learning-based and most traditional methods, and is competitive with the state-of-the-art heuristic method [i.e., OR-Tools], especially on large-scale problems. The great generalizability of DL-DRL is also verified by testing the model learned for a problem size to larger ones. Furthermore, an ablation study demonstrates that our ITS can reach a compromise between the model performance and training duration.