 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Forgetting Knowledge Allocation with Bi-level Competition for Class-Incremental Learning
May 28, 2026Class-Incremental Learning (CIL) with pre-trained models (PTMs) aims to sequentially adapt PTMs to new categories without forgetting old knowledge. Built upon PTMs, existing adapter-based methods mainly train models via distinct task-specific adapters, and present a uniform knowledge allocation for each adapter during inference. However, this allocation mechanism ignores the nature of task discrepancy and leads to suboptimal utilization of adapters. Also, under CIL constraint, an allocator is prone to forgetting when tasks evolve. To address these issues, we propose a Non-Forgetting Allocation with Bi-Level Competition (NoFA-BC). NoFA-BC constructs a non-forgetting allocator (NFA) by transforming the allocator training into a recursive least-squares problem and achieves an allocator equivalent to that trained with all data. Based on the NFA, a Bi-Level Competition (BLC) including an intra-task level Winner-Takes-All (WTA) mechanism and inter-task Last-Ones-Fall (LOF) elimination is proposed to provide better allocation of adapter knowledge. WTA extracts the most significant logit within a task to represent the adapter's contribution and LOF suppresses the irrelevant adapters. With BLC, participation ratio of each adapter can be tailored for each input. Moreover, a Stability Enhancement (SE) process is incorporated to further improve the performance of old tasks.
Rethinking Adapter Placement: A Dominant Adaptation Module Perspective
May 07, 2026Low-rank adaptation (LoRA) is a widely used parameter-efficient fine-tuning method that places trainable low-rank adapters into frozen pre-trained models. Recent studies show that using fewer LoRA adapters may still maintain or even improve performance, but existing methods still distribute adapters broadly, leaving where to place a limited number of adapters to maximize performance largely open. To investigate this, we introduce PAGE (Projected Adapter Gradient Energy), a gradient-based sensitivity probe that estimates the initial trainable gradient energy available to each candidate LoRA adapter. Surprisingly, we find that PAGE is highly concentrated on a single shallow FFN down-projection across two model families and four downstream tasks. We term this module the dominant adaptation module and show that its layer index is architecture-dependent but task-stable. Motivated by this finding, we propose DomLoRA, a placement method that places a single adapter at the dominant adaptation module. With only ~0.7% of vanilla LoRA's trainable parameters, DomLoRA outperforms it on average across various downstream tasks, including instruction following, mathematical reasoning, code generation, and multi-turn conversation. This method also improves other LoRA variants, supporting the dominant adaptation module perspective as a practical placement guideline.
Cooperative Multi-Agent Reinforcement Learning Based Distributed Dynamic Spectrum Access in Cognitive Radio Networks
Jun 17, 2021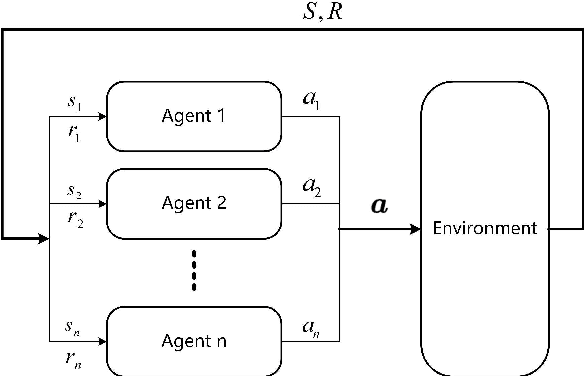
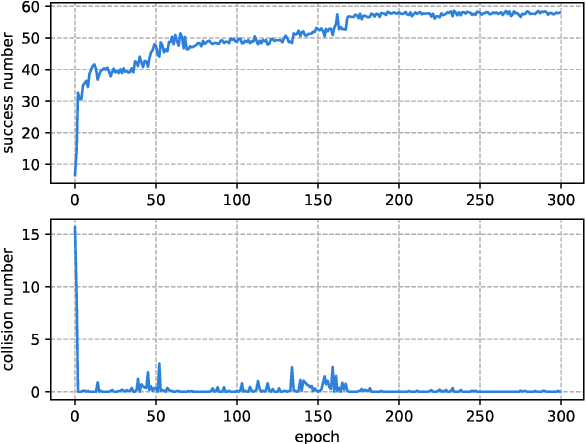
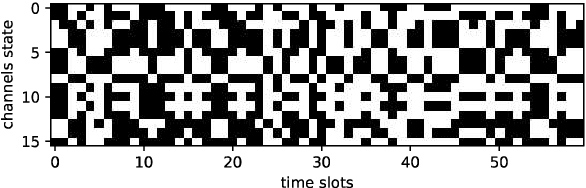
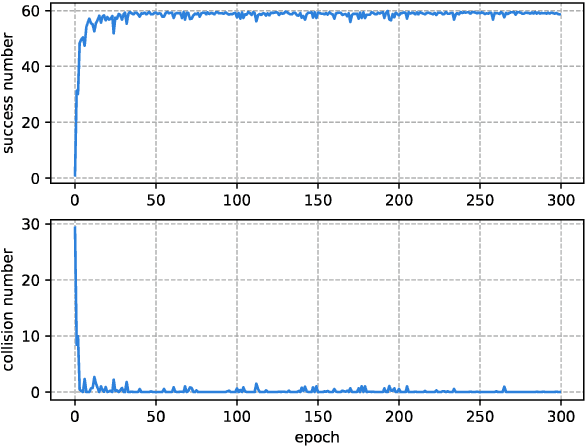
With the development of the 5G and Internet of Things, amounts of wireless devices need to share the limited spectrum resources. Dynamic spectrum access (DSA) is a promising paradigm to remedy the problem of inefficient spectrum utilization brought upon by the historical command-and-control approach to spectrum allocation. In this paper, we investigate the distributed DSA problem for multi-user in a typical multi-channel cognitive radio network. The problem is formulated as a decentralized partially observable Markov decision process (Dec-POMDP), and we proposed a centralized off-line training and distributed on-line execution framework based on cooperative multi-agent reinforcement learning (MARL). We employ the deep recurrent Q-network (DRQN) to address the partial observability of the state for each cognitive user. The ultimate goal is to learn a cooperative strategy which maximizes the sum throughput of cognitive radio network in distributed fashion without coordination information exchange between cognitive users. Finally, we validate the proposed algorithm in various settings through extensive experiments. From the simulation results, we can observe that the proposed algorithm can converge fast and achieve almost the optimal performance.