 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGET: Unlocking the Multi-modal Potential of CLIP for Generalized Category Discovery
Mar 15, 2024



Given unlabelled datasets containing both old and new categories, generalized category discovery (GCD) aims to accurately discover new classes while correctly classifying old classes, leveraging the class concepts learned from labeled samples. Current GCD methods only use a single visual modality of information, resulting in poor classification of visually similar classes. Though certain classes are visually confused, their text information might be distinct, motivating us to introduce text information into the GCD task. However, the lack of class names for unlabelled data makes it impractical to utilize text information. To tackle this challenging problem, in this paper, we propose a Text Embedding Synthesizer (TES) to generate pseudo text embeddings for unlabelled samples. Specifically, our TES leverages the property that CLIP can generate aligned vision-language features, converting visual embeddings into tokens of the CLIP's text encoder to generate pseudo text embeddings. Besides, we employ a dual-branch framework, through the joint learning and instance consistency of different modality branches, visual and semantic information mutually enhance each other, promoting the interaction and fusion of visual and text embedding space. Our method unlocks the multi-modal potentials of CLIP and outperforms the baseline methods by a large margin on all GCD benchmarks, achieving new state-of-the-art. The code will be released at \url{https://github.com/enguangW/GET}.
Fine-Grained Knowledge Selection and Restoration for Non-Exemplar Class Incremental Learning
Dec 20, 2023Non-exemplar class incremental learning aims to learn both the new and old tasks without accessing any training data from the past. This strict restriction enlarges the difficulty of alleviating catastrophic forgetting since all techniques can only be applied to current task data. Considering this challenge, we propose a novel framework of fine-grained knowledge selection and restoration. The conventional knowledge distillation-based methods place too strict constraints on the network parameters and features to prevent forgetting, which limits the training of new tasks. To loose this constraint, we proposed a novel fine-grained selective patch-level distillation to adaptively balance plasticity and stability. Some task-agnostic patches can be used to preserve the decision boundary of the old task. While some patches containing the important foreground are favorable for learning the new task. Moreover, we employ a task-agnostic mechanism to generate more realistic prototypes of old tasks with the current task sample for reducing classifier bias for fine-grained knowledge restoration. Extensive experiments on CIFAR100, TinyImageNet and ImageNet-Subset demonstrate the effectiveness of our method. Code is available at https://github.com/scok30/vit-cil.
Class Incremental Learning with Pre-trained Vision-Language Models
Oct 31, 2023



With the advent of large-scale pre-trained models, interest in adapting and exploiting them for continual learning scenarios has grown. In this paper, we propose an approach to exploiting pre-trained vision-language models (e.g. CLIP) that enables further adaptation instead of only using zero-shot learning of new tasks. We augment a pre-trained CLIP model with additional layers after the Image Encoder or before the Text Encoder. We investigate three different strategies: a Linear Adapter, a Self-attention Adapter, each operating on the image embedding, and Prompt Tuning which instead modifies prompts input to the CLIP text encoder. We also propose a method for parameter retention in the adapter layers that uses a measure of parameter importance to better maintain stability and plasticity during incremental learning. Our experiments demonstrate that the simplest solution -- a single Linear Adapter layer with parameter retention -- produces the best results. Experiments on several conventional benchmarks consistently show a significant margin of improvement over the current state-of-the-art.
Masked Autoencoders are Efficient Class Incremental Learners
Aug 24, 2023



Class Incremental Learning (CIL) aims to sequentially learn new classes while avoiding catastrophic forgetting of previous knowledge. We propose to use Masked Autoencoders (MAEs) as efficient learners for CIL. MAEs were originally designed to learn useful representations through reconstructive unsupervised learning, and they can be easily integrated with a supervised loss for classification. Moreover, MAEs can reliably reconstruct original input images from randomly selected patches, which we use to store exemplars from past tasks more efficiently for CIL. We also propose a bilateral MAE framework to learn from image-level and embedding-level fusion, which produces better-quality reconstructed images and more stable representations. Our experiments confirm that our approach performs better than the state-of-the-art on CIFAR-100, ImageNet-Subset, and ImageNet-Full. The code is available at https://github.com/scok30/MAE-CIL .
Lighting Every Darkness in Two Pairs: A Calibration-Free Pipeline for RAW Denoising
Aug 07, 2023Calibration-based methods have dominated RAW image denoising under extremely low-light environments. However, these methods suffer from several main deficiencies: 1) the calibration procedure is laborious and time-consuming, 2) denoisers for different cameras are difficult to transfer, and 3) the discrepancy between synthetic noise and real noise is enlarged by high digital gain. To overcome the above shortcomings, we propose a calibration-free pipeline for Lighting Every Drakness (LED), regardless of the digital gain or camera sensor. Instead of calibrating the noise parameters and training repeatedly, our method could adapt to a target camera only with few-shot paired data and fine-tuning. In addition, well-designed structural modification during both stages alleviates the domain gap between synthetic and real noise without any extra computational cost. With 2 pairs for each additional digital gain (in total 6 pairs) and 0.5% iterations, our method achieves superior performance over other calibration-based methods. Our code is available at https://github.com/Srameo/LED .
Robust Saliency Guidance for Data-free Class Incremental Learning
Dec 16, 2022



Data-Free Class Incremental Learning (DFCIL) aims to sequentially learn tasks with access only to data from the current one. DFCIL is of interest because it mitigates concerns about privacy and long-term storage of data, while at the same time alleviating the problem of catastrophic forgetting in incremental learning. In this work, we introduce robust saliency guidance for DFCIL and propose a new framework, which we call RObust Saliency Supervision (ROSS), for mitigating the negative effect of saliency drift. Firstly, we use a teacher-student architecture leveraging low-level tasks to supervise the model with global saliency. We also apply boundary-guided saliency to protect it from drifting across object boundaries at intermediate layers. Finally, we introduce a module for injecting and recovering saliency noise to increase robustness of saliency preservation. Our experiments demonstrate that our method can retain better saliency maps across tasks and achieve state-of-the-art results on the CIFAR-100, Tiny-ImageNet and ImageNet-Subset DFCIL benchmarks. Code will be made publicly available.
Positive Pair Distillation Considered Harmful: Continual Meta Metric Learning for Lifelong Object Re-Identification
Oct 04, 2022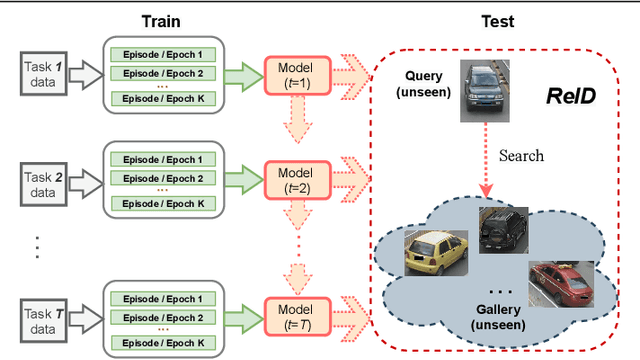

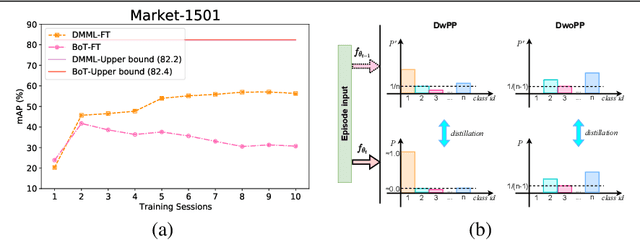

Lifelong object re-identification incrementally learns from a stream of re-identification tasks. The objective is to learn a representation that can be applied to all tasks and that generalizes to previously unseen re-identification tasks. The main challenge is that at inference time the representation must generalize to previously unseen identities. To address this problem, we apply continual meta metric learning to lifelong object re-identification. To prevent forgetting of previous tasks, we use knowledge distillation and explore the roles of positive and negative pairs. Based on our observation that the distillation and metric losses are antagonistic, we propose to remove positive pairs from distillation to robustify model updates. Our method, called Distillation without Positive Pairs (DwoPP), is evaluated on extensive intra-domain experiments on person and vehicle re-identification datasets, as well as inter-domain experiments on the LReID benchmark. Our experiments demonstrate that DwoPP significantly outperforms the state-of-the-art. The code is here: https://github.com/wangkai930418/DwoPP_code
Long-Tailed Class Incremental Learning
Oct 01, 2022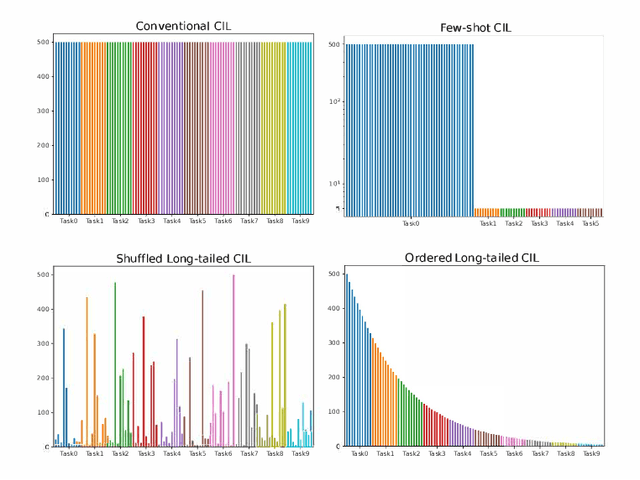
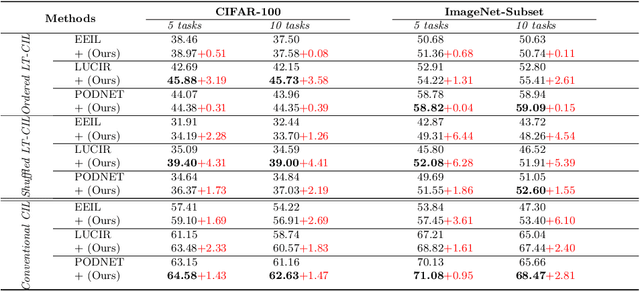
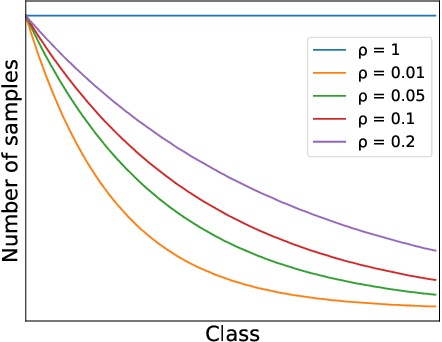
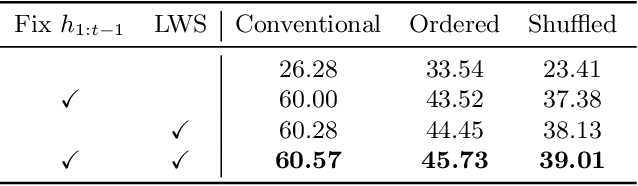
In class incremental learning (CIL) a model must learn new classes in a sequential manner without forgetting old ones. However, conventional CIL methods consider a balanced distribution for each new task, which ignores the prevalence of long-tailed distributions in the real world. In this work we propose two long-tailed CIL scenarios, which we term ordered and shuffled LT-CIL. Ordered LT-CIL considers the scenario where we learn from head classes collected with more samples than tail classes which have few. Shuffled LT-CIL, on the other hand, assumes a completely random long-tailed distribution for each task. We systematically evaluate existing methods in both LT-CIL scenarios and demonstrate very different behaviors compared to conventional CIL scenarios. Additionally, we propose a two-stage learning baseline with a learnable weight scaling layer for reducing the bias caused by long-tailed distribution in LT-CIL and which in turn also improves the performance of conventional CIL due to the limited exemplars. Our results demonstrate the superior performance (up to 6.44 points in average incremental accuracy) of our approach on CIFAR-100 and ImageNet-Subset. The code is available at https://github.com/xialeiliu/Long-Tailed-CIL
Universal Representations: A Unified Look at Multiple Task and Domain Learning
Apr 06, 2022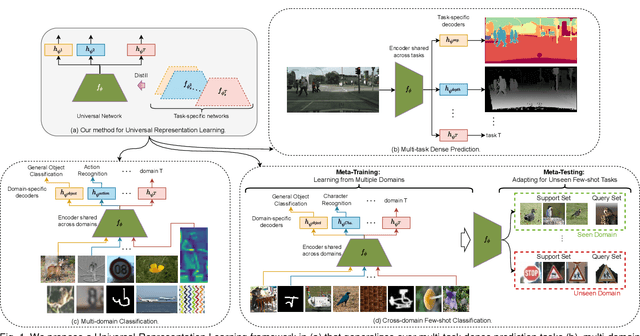
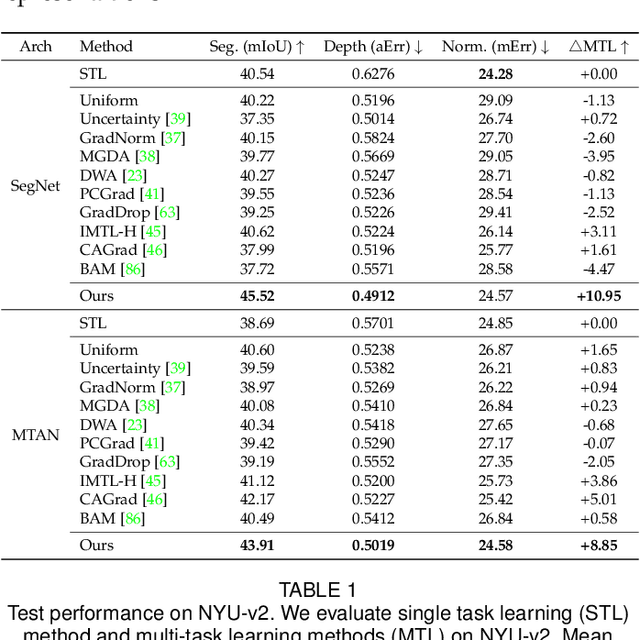
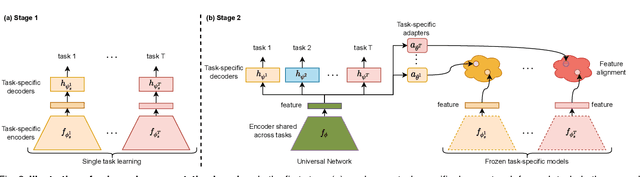
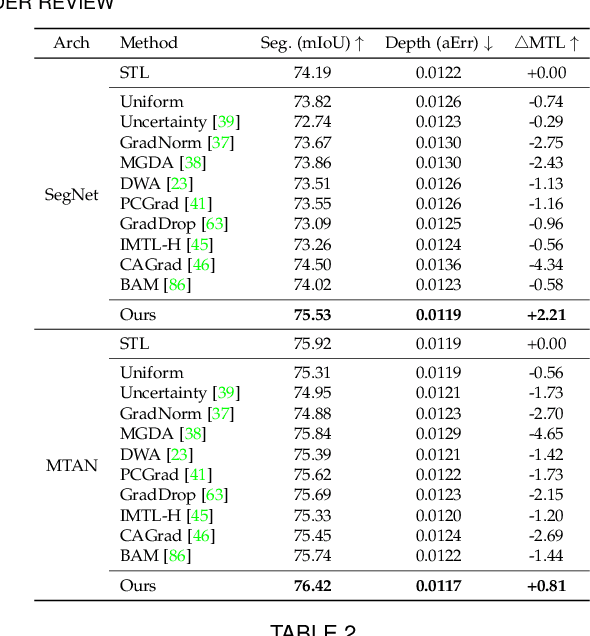
We propose a unified look at jointly learning multiple vision tasks and visual domains through universal representations, a single deep neural network. Learning multiple problems simultaneously involves minimizing a weighted sum of multiple loss functions with different magnitudes and characteristics and thus results in unbalanced state of one loss dominating the optimization and poor results compared to learning a separate model for each problem. To this end, we propose distilling knowledge of multiple task/domain-specific networks into a single deep neural network after aligning its representations with the task/domain-specific ones through small capacity adapters. We rigorously show that universal representations achieve state-of-the-art performances in learning of multiple dense prediction problems in NYU-v2 and Cityscapes, multiple image classification problems from diverse domains in Visual Decathlon Dataset and cross-domain few-shot learning in MetaDataset. Finally we also conduct multiple analysis through ablation and qualitative studies.
Representation Compensation Networks for Continual Semantic Segmentation
Mar 10, 2022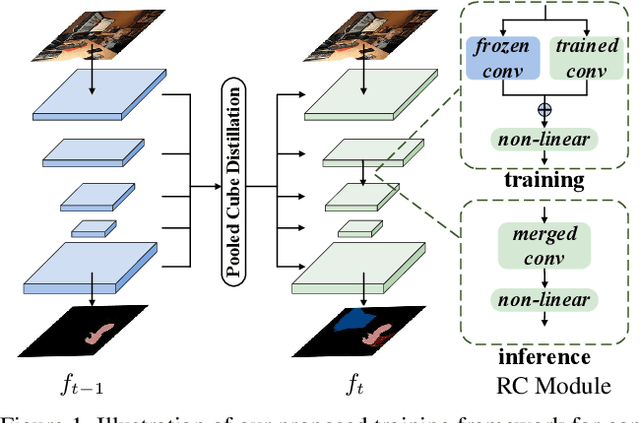
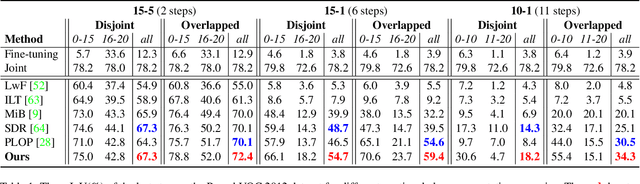
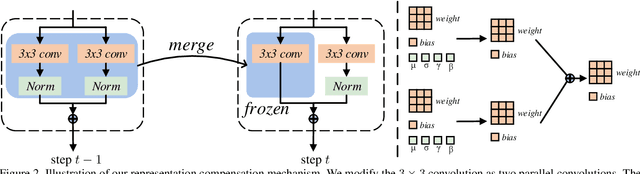

In this work, we study the continual semantic segmentation problem, where the deep neural networks are required to incorporate new classes continually without catastrophic forgetting. We propose to use a structural re-parameterization mechanism, named representation compensation (RC) module, to decouple the representation learning of both old and new knowledge. The RC module consists of two dynamically evolved branches with one frozen and one trainable. Besides, we design a pooled cube knowledge distillation strategy on both spatial and channel dimensions to further enhance the plasticity and stability of the model. We conduct experiments on two challenging continual semantic segmentation scenarios, continual class segmentation and continual domain segmentation. Without any extra computational overhead and parameters during inference, our method outperforms state-of-the-art performance. The code is available at \url{https://github.com/zhangchbin/RCIL}.