 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Film-Making Production Dialogue, Narration, Monologue Adaptive Moving Dubbing Benchmarks
Apr 30, 2025Movie dubbing has advanced significantly, yet assessing the real-world effectiveness of these models remains challenging. A comprehensive evaluation benchmark is crucial for two key reasons: 1) Existing metrics fail to fully capture the complexities of dialogue, narration, monologue, and actor adaptability in movie dubbing. 2) A practical evaluation system should offer valuable insights to improve movie dubbing quality and advancement in film production. To this end, we introduce Talking Adaptive Dubbing Benchmarks (TA-Dubbing), designed to improve film production by adapting to dialogue, narration, monologue, and actors in movie dubbing. TA-Dubbing offers several key advantages: 1) Comprehensive Dimensions: TA-Dubbing covers a variety of dimensions of movie dubbing, incorporating metric evaluations for both movie understanding and speech generation. 2) Versatile Benchmarking: TA-Dubbing is designed to evaluate state-of-the-art movie dubbing models and advanced multi-modal large language models. 3) Full Open-Sourcing: We fully open-source TA-Dubbing at https://github.com/woka- 0a/DeepDubber- V1 including all video suits, evaluation methods, annotations. We also continuously integrate new movie dubbing models into the TA-Dubbing leaderboard at https://github.com/woka- 0a/DeepDubber-V1 to drive forward the field of movie dubbing.
End2end-ALARA: Approaching the ALARA Law in CT Imaging with End-to-end Learning
Apr 09, 2025Computed tomography (CT) examination poses radiation injury to patient. A consensus performing CT imaging is to make the radiation dose as low as reasonably achievable, i.e. the ALARA law. In this paper, we propose an end-to-end learning framework, named End2end-ALARA, that jointly optimizes dose modulation and image reconstruction to meet the goal of ALARA in CT imaging. End2end-ALARA works by building a dose modulation module and an image reconstruction module, connecting these modules with a differentiable simulation function, and optimizing the them with a constrained hinge loss function. The objective is to minimize radiation dose subject to a prescribed image quality (IQ) index. The results show that End2end-ALARA is able to preset personalized dose levels to gain a stable IQ level across patients, which may facilitate image-based diagnosis and downstream model training. Moreover, compared to fixed-dose and conventional dose modulation strategies, End2end-ALARA consumes lower dose to reach the same IQ level. Our study sheds light on a way of realizing the ALARA law in CT imaging.
Improving Embedded Knowledge Graph Multi-hop Question Answering by introducing Relational Chain Reasoning
Oct 25, 2021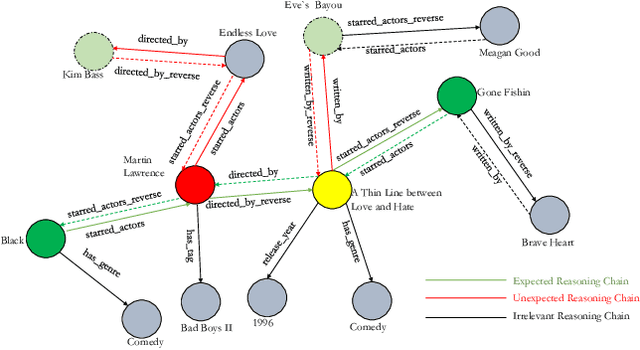
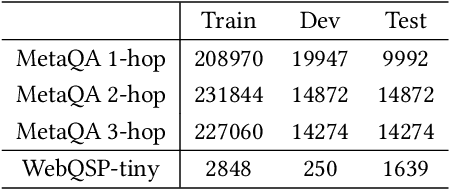
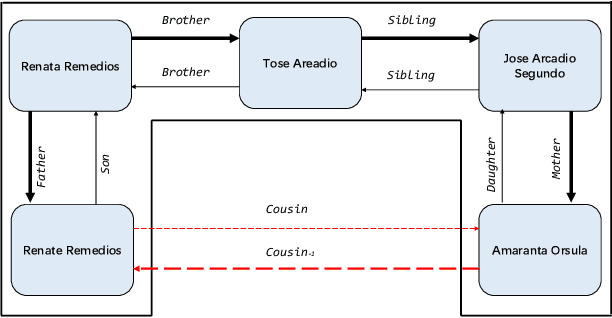
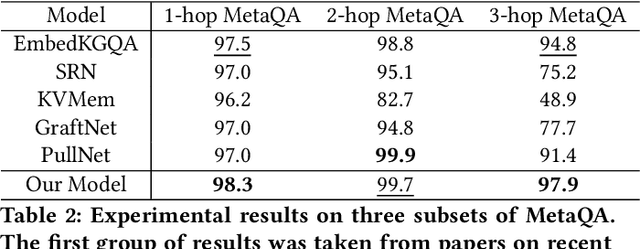
Knowledge Base Question Answering (KBQA) aims to answer userquestions from a knowledge base (KB) by identifying the reasoningrelations between topic entity and answer. As a complex branchtask of KBQA, multi-hop KGQA requires reasoning over multi-hop relational chains preserved in KG to arrive at the right answer.Despite the successes made in recent years, the existing works onanswering multi-hop complex question face the following challenges: i) suffering from poor performances due to the neglect of explicit relational chain order and its relational types reflected inuser questions; ii) failing to consider implicit relations between thetopic entity and the answer implied in structured KG because oflimited neighborhood size constraints in subgraph retrieval based algorithms. To address these issues in multi-hop KGQA, we proposea novel model in this paper, namely Relational Chain-based Embed-ded KGQA (Rce-KGQA), which simultaneously utilizes the explicitrelational chain described in natural language questions and the implicit relational chain stored in structured KG. Our extensiveempirical study on two open-domain benchmarks proves that ourmethod significantly outperforms the state-of-the-art counterpartslike GraftNet, PullNet and EmbedKGQA. Comprehensive ablation experiments also verify the effectiveness of our method for multi-hop KGQA tasks. We have made our model's source code availableat Github: https://github.com/albert-jin/Rce-KGQA.