 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the calibration of Just-in-time Defect Prediction
Apr 16, 2025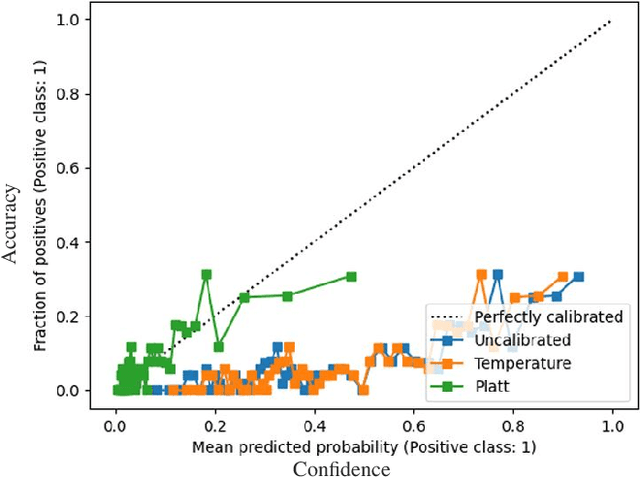
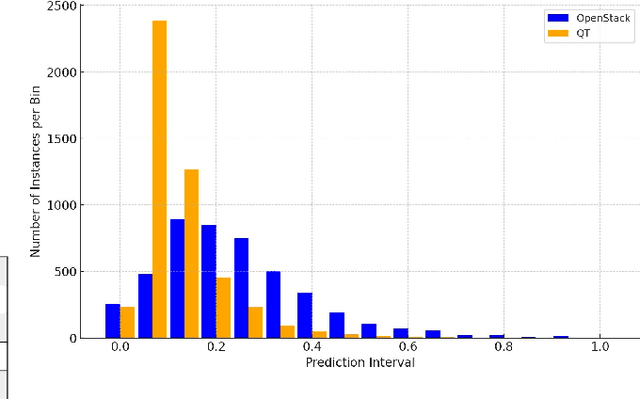
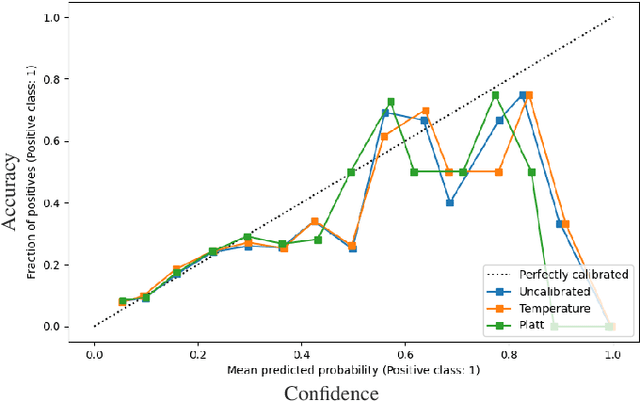
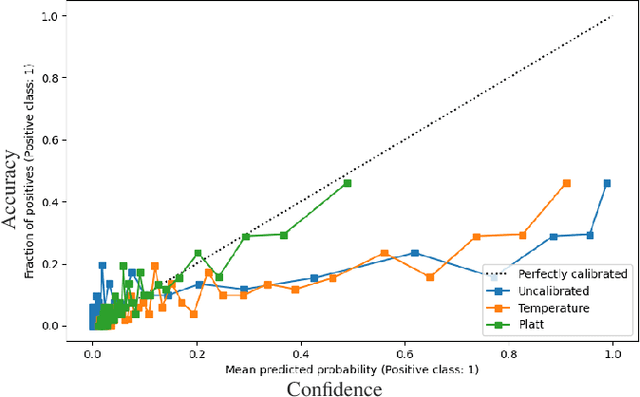
Just in time defect prediction (JIT DP) leverages ML to identify defect-prone code commits, enabling quality assurance (QA) teams to allocate resources more efficiently by focusing on commits that are most likely to contain defects. Although JIT DP techniques have introduced improvements in terms of predictive accuracy, they are still susceptible to misclassification errors such as false positives and negatives. This can lead to wasted resources or undetected defects, a particularly critical concern when QA resources are limited. To mitigate these challenges and preserve the practical utility of JIT DP tools, it becomes essential to estimate the reliability of the predictions, i.e., computing confidence scores. Such scores can help practitioners determine the trustworthiness of predictions and thus prioritize them efficiently. A simple approach to computing confidence scores is to extract, alongside each prediction, the corresponding prediction probabilities and use them as indicators of confidence. However, for these probabilities to reliably serve as confidence scores, the predictive model must be well-calibrated. This means that the prediction probabilities must accurately represent the true likelihood of each prediction being correct. Miscalibration, common in modern ML models, distorts probability scores such that they do not align with the actual correctness probability. In this study, we evaluate the calibration of three JIT DP techniques to determine whether and to what extent they exhibit poor calibration. Furthermore, we assess whether post-calibration methods can improve the calibration of existing JIT defect prediction models. Our results reveal that all evaluated JIT DP models exhibit some level of miscalibration, with ECE ranging from 2-35%. Furthermore, post-calibration methods do not consistently improve the calibration.
Variance of ML-based software fault predictors: are we really improving fault prediction?
Oct 26, 2023Software quality assurance activities become increasingly difficult as software systems become more and more complex and continuously grow in size. Moreover, testing becomes even more expensive when dealing with large-scale systems. Thus, to effectively allocate quality assurance resources, researchers have proposed fault prediction (FP) which utilizes machine learning (ML) to predict fault-prone code areas. However, ML algorithms typically make use of stochastic elements to increase the prediction models' generalizability and efficiency of the training process. These stochastic elements, also known as nondeterminism-introducing (NI) factors, lead to variance in the training process and as a result, lead to variance in prediction accuracy and training time. This variance poses a challenge for reproducibility in research. More importantly, while fault prediction models may have shown good performance in the lab (e.g., often-times involving multiple runs and averaging outcomes), high variance of results can pose the risk that these models show low performance when applied in practice. In this work, we experimentally analyze the variance of a state-of-the-art fault prediction approach. Our experimental results indicate that NI factors can indeed cause considerable variance in the fault prediction models' accuracy. We observed a maximum variance of 10.10% in terms of the per-class accuracy metric. We thus, also discuss how to deal with such variance.