 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the calibration of Just-in-time Defect Prediction
Apr 16, 2025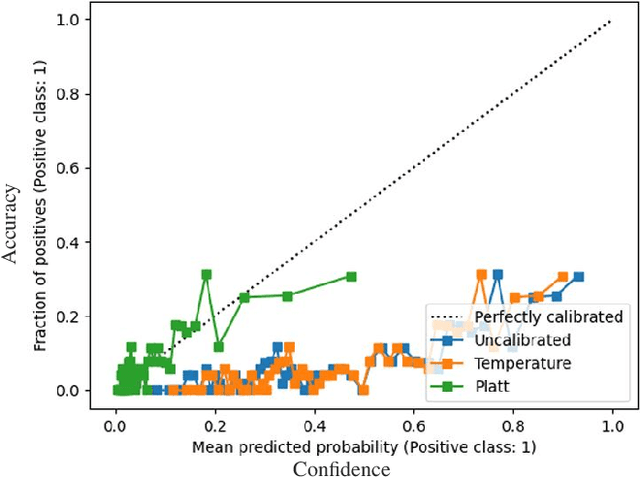
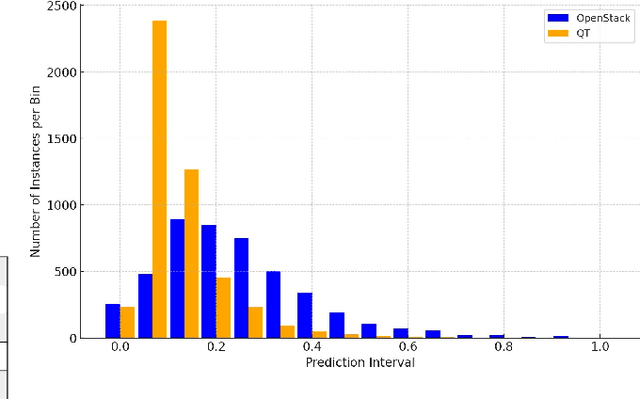
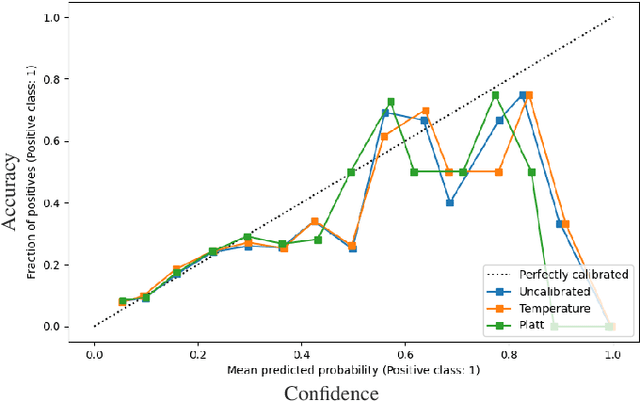
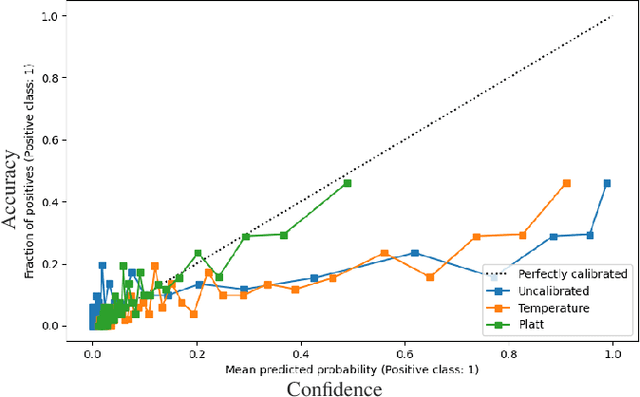
Just in time defect prediction (JIT DP) leverages ML to identify defect-prone code commits, enabling quality assurance (QA) teams to allocate resources more efficiently by focusing on commits that are most likely to contain defects. Although JIT DP techniques have introduced improvements in terms of predictive accuracy, they are still susceptible to misclassification errors such as false positives and negatives. This can lead to wasted resources or undetected defects, a particularly critical concern when QA resources are limited. To mitigate these challenges and preserve the practical utility of JIT DP tools, it becomes essential to estimate the reliability of the predictions, i.e., computing confidence scores. Such scores can help practitioners determine the trustworthiness of predictions and thus prioritize them efficiently. A simple approach to computing confidence scores is to extract, alongside each prediction, the corresponding prediction probabilities and use them as indicators of confidence. However, for these probabilities to reliably serve as confidence scores, the predictive model must be well-calibrated. This means that the prediction probabilities must accurately represent the true likelihood of each prediction being correct. Miscalibration, common in modern ML models, distorts probability scores such that they do not align with the actual correctness probability. In this study, we evaluate the calibration of three JIT DP techniques to determine whether and to what extent they exhibit poor calibration. Furthermore, we assess whether post-calibration methods can improve the calibration of existing JIT defect prediction models. Our results reveal that all evaluated JIT DP models exhibit some level of miscalibration, with ECE ranging from 2-35%. Furthermore, post-calibration methods do not consistently improve the calibration.
An AI Chatbot for Explaining Deep Reinforcement Learning Decisions of Service-oriented Systems
Sep 25, 2023Deep Reinforcement Learning (Deep RL) is increasingly used to cope with the open-world assumption in service-oriented systems. Deep RL was successfully applied to problems such as dynamic service composition, job scheduling, and offloading, as well as service adaptation. While Deep RL offers many benefits, understanding the decision-making of Deep RL is challenging because its learned decision-making policy essentially appears as a black box. Yet, understanding the decision-making of Deep RL is key to help service developers perform debugging, support service providers to comply with relevant legal frameworks, and facilitate service users to build trust. We introduce Chat4XAI to facilitate the understanding of the decision-making of Deep RL by providing natural-language explanations. Compared with visual explanations, the reported benefits of natural-language explanations include better understandability for non-technical users, increased user acceptance and trust, as well as more efficient explanations. Chat4XAI leverages modern AI chatbot technology and dedicated prompt engineering. Compared to earlier work on natural-language explanations using classical software-based dialogue systems, using an AI chatbot eliminates the need for eliciting and defining potential questions and answers up-front. We prototypically realize Chat4XAI using OpenAI's ChatGPT API and evaluate the fidelity and stability of its explanations using an adaptive service exemplar.