 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXavier Giro-i-Nieto
Recurrent Neural Networks for Semantic Instance Segmentation
Sep 03, 2018
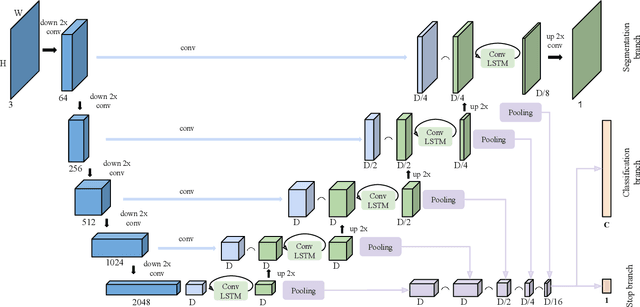

We present a recurrent model for semantic instance segmentation that sequentially generates binary masks and their associated class probabilities for every object in an image. Our proposed system is trainable end-to-end from an input image to a sequence of labeled masks and, compared to methods relying on object proposals, does not require post-processing steps on its output. We study the suitability of our recurrent model on three different instance segmentation benchmarks, namely Pascal VOC 2012, CVPPP Plant Leaf Segmentation and Cityscapes. Further, we analyze the object sorting patterns generated by our model and observe that it learns to follow a consistent pattern, which correlates with the activations learned in the encoder part of our network. Source code and models are available at https://imatge-upc.github.io/rsis/
PathGAN: Visual Scanpath Prediction with Generative Adversarial Networks
Sep 03, 2018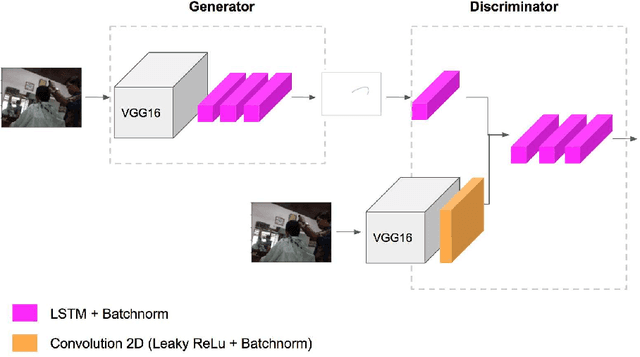

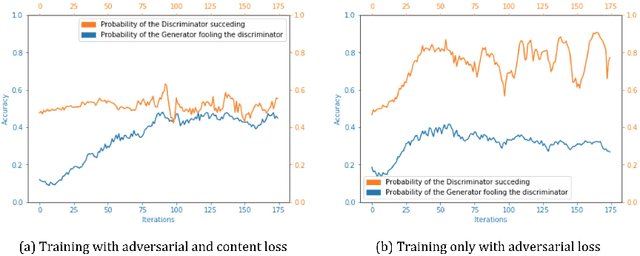
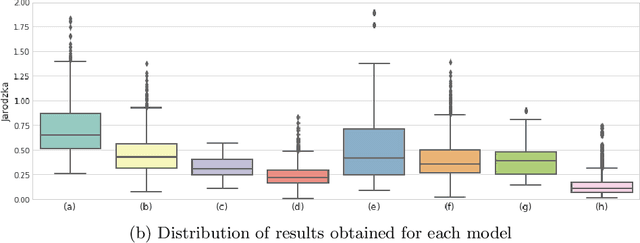
We introduce PathGAN, a deep neural network for visual scanpath prediction trained on adversarial examples. A visual scanpath is defined as the sequence of fixation points over an image defined by a human observer with its gaze. PathGAN is composed of two parts, the generator and the discriminator. Both parts extract features from images using off-the-shelf networks, and train recurrent layers to generate or discriminate scanpaths accordingly. In scanpath prediction, the stochastic nature of the data makes it very difficult to generate realistic predictions using supervised learning strategies, but we adopt adversarial training as a suitable alternative. Our experiments prove how PathGAN improves the state of the art of visual scanpath prediction on the iSUN and Salient360! datasets. Source code and models are available at https://imatge-upc.github.io/pathgan/
Online Detection of Action Start in Untrimmed, Streaming Videos
Jul 23, 2018
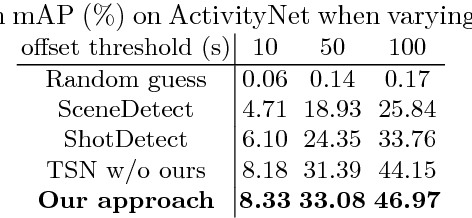
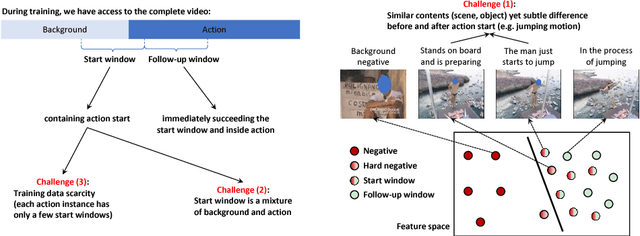
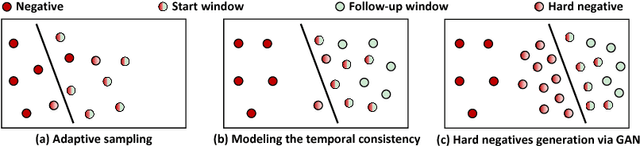
We aim to tackle a novel task in action detection - Online Detection of Action Start (ODAS) in untrimmed, streaming videos. The goal of ODAS is to detect the start of an action instance, with high categorization accuracy and low detection latency. ODAS is important in many applications such as early alert generation to allow timely security or emergency response. We propose three novel methods to specifically address the challenges in training ODAS models: (1) hard negative samples generation based on Generative Adversarial Network (GAN) to distinguish ambiguous background, (2) explicitly modeling the temporal consistency between data around action start and data succeeding action start, and (3) adaptive sampling strategy to handle the scarcity of training data. We conduct extensive experiments using THUMOS'14 and ActivityNet. We show that our proposed methods lead to significant performance gains and improve the state-of-the-art methods. An ablation study confirms the effectiveness of each proposed method.
SalGAN: Visual Saliency Prediction with Generative Adversarial Networks
Jul 01, 2018
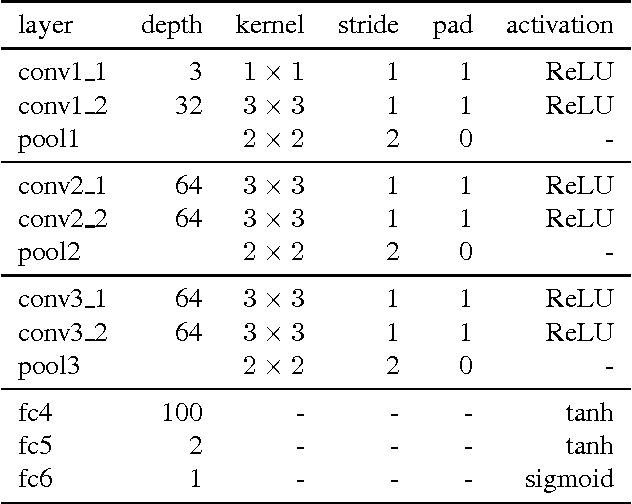
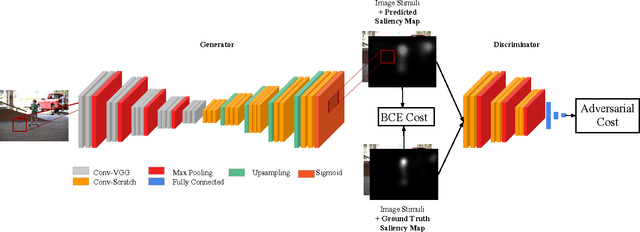
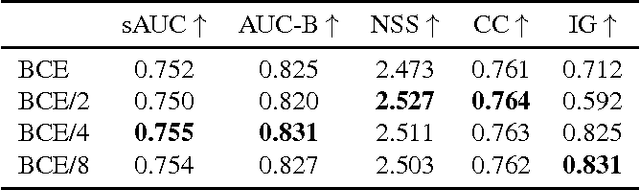
We introduce SalGAN, a deep convolutional neural network for visual saliency prediction trained with adversarial examples. The first stage of the network consists of a generator model whose weights are learned by back-propagation computed from a binary cross entropy (BCE) loss over downsampled versions of the saliency maps. The resulting prediction is processed by a discriminator network trained to solve a binary classification task between the saliency maps generated by the generative stage and the ground truth ones. Our experiments show how adversarial training allows reaching state-of-the-art performance across different metrics when combined with a widely-used loss function like BCE. Our results can be reproduced with the source code and trained models available at https://imatge-upc.github.io/saliency-salgan-2017/.
Comparing Fixed and Adaptive Computation Time for Recurrent Neural Networks
Mar 21, 2018
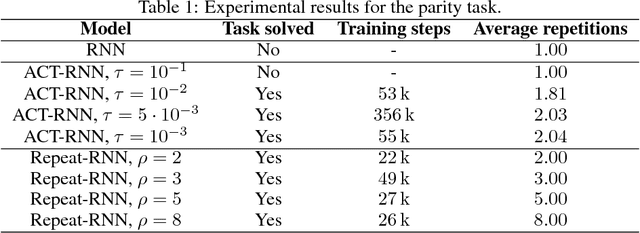
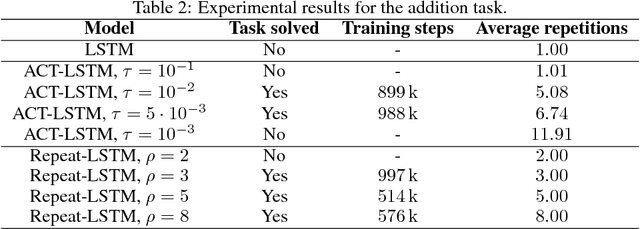
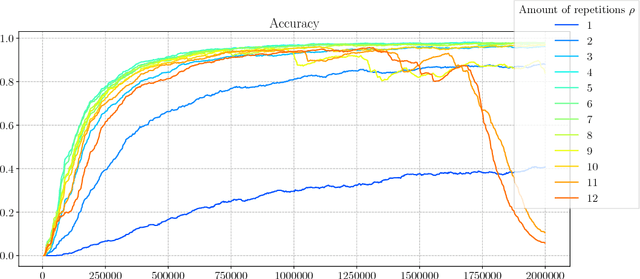
Adaptive Computation Time for Recurrent Neural Networks (ACT) is one of the most promising architectures for variable computation. ACT adapts to the input sequence by being able to look at each sample more than once, and learn how many times it should do it. In this paper, we compare ACT to Repeat-RNN, a novel architecture based on repeating each sample a fixed number of times. We found surprising results, where Repeat-RNN performs as good as ACT in the selected tasks. Source code in TensorFlow and PyTorch is publicly available at https://imatge-upc.github.io/danifojo-2018-repeatrnn/
Skip RNN: Learning to Skip State Updates in Recurrent Neural Networks
Feb 05, 2018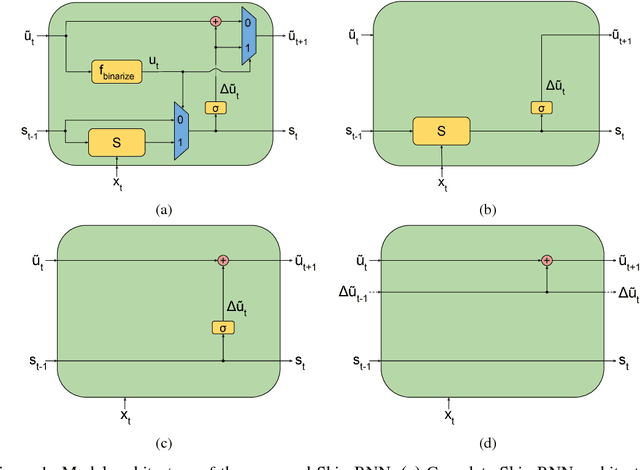
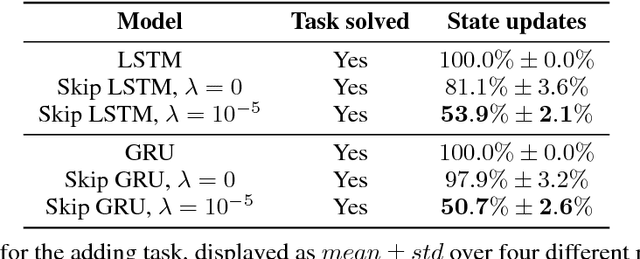
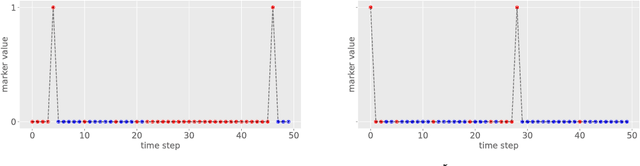
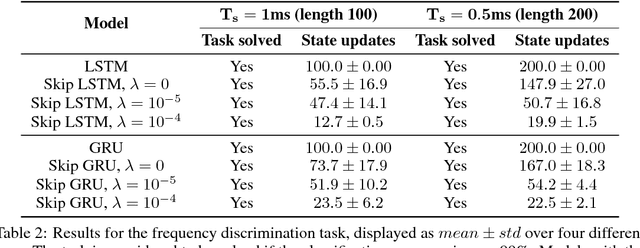
Recurrent Neural Networks (RNNs) continue to show outstanding performance in sequence modeling tasks. However, training RNNs on long sequences often face challenges like slow inference, vanishing gradients and difficulty in capturing long term dependencies. In backpropagation through time settings, these issues are tightly coupled with the large, sequential computational graph resulting from unfolding the RNN in time. We introduce the Skip RNN model which extends existing RNN models by learning to skip state updates and shortens the effective size of the computational graph. This model can also be encouraged to perform fewer state updates through a budget constraint. We evaluate the proposed model on various tasks and show how it can reduce the number of required RNN updates while preserving, and sometimes even improving, the performance of the baseline RNN models. Source code is publicly available at https://imatge-upc.github.io/skiprnn-2017-telecombcn/ .
Detection-aided liver lesion segmentation using deep learning
Nov 29, 2017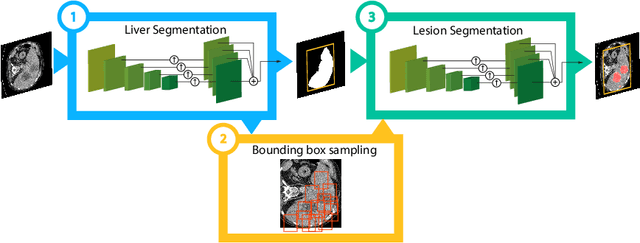
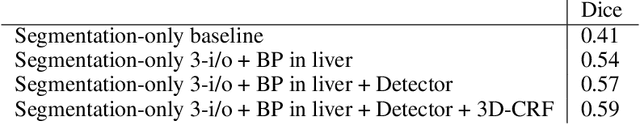
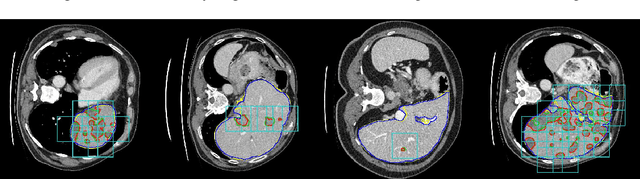
A fully automatic technique for segmenting the liver and localizing its unhealthy tissues is a convenient tool in order to diagnose hepatic diseases and assess the response to the according treatments. In this work we propose a method to segment the liver and its lesions from Computed Tomography (CT) scans using Convolutional Neural Networks (CNNs), that have proven good results in a variety of computer vision tasks, including medical imaging. The network that segments the lesions consists of a cascaded architecture, which first focuses on the region of the liver in order to segment the lesions on it. Moreover, we train a detector to localize the lesions, and mask the results of the segmentation network with the positive detections. The segmentation architecture is based on DRIU, a Fully Convolutional Network (FCN) with side outputs that work on feature maps of different resolutions, to finally benefit from the multi-scale information learned by different stages of the network. The main contribution of this work is the use of a detector to localize the lesions, which we show to be beneficial to remove false positives triggered by the segmentation network. Source code and models are available at https://imatge-upc.github.io/liverseg-2017-nipsws/ .
Saliency Weighted Convolutional Features for Instance Search
Nov 29, 2017


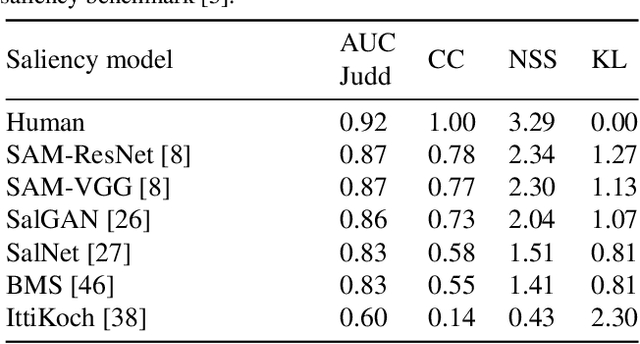
This work explores attention models to weight the contribution of local convolutional representations for the instance search task. We present a retrieval framework based on bags of local convolutional features (BLCF) that benefits from saliency weighting to build an efficient image representation. The use of human visual attention models (saliency) allows significant improvements in retrieval performance without the need to conduct region analysis or spatial verification, and without requiring any feature fine tuning. We investigate the impact of different saliency models, finding that higher performance on saliency benchmarks does not necessarily equate to improved performance when used in instance search tasks. The proposed approach outperforms the state-of-the-art on the challenging INSTRE benchmark by a large margin, and provides similar performance on the Oxford and Paris benchmarks compared to more complex methods that use off-the-shelf representations. The source code used in this project is available at https://imatge-upc.github.io/salbow/
Cost-Effective Active Learning for Melanoma Segmentation
Nov 28, 2017
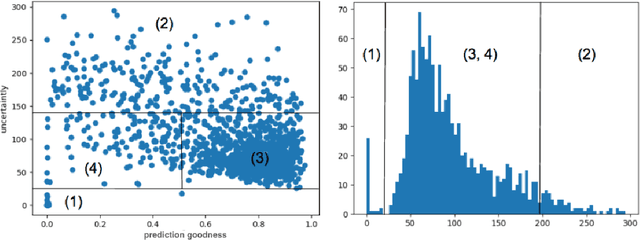
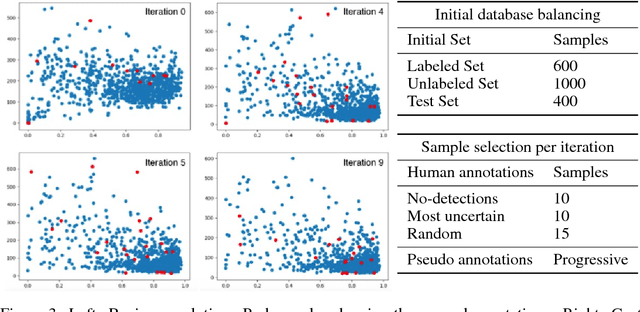
We propose a novel Active Learning framework capable to train effectively a convolutional neural network for semantic segmentation of medical imaging, with a limited amount of training labeled data. Our contribution is a practical Cost-Effective Active Learning approach using dropout at test time as Monte Carlo sampling to model the pixel-wise uncertainty and to analyze the image information to improve the training performance. The source code of this project is available at https://marc-gorriz.github.io/CEAL-Medical-Image-Segmentation/ .
More cat than cute? Interpretable Prediction of Adjective-Noun Pairs
Aug 21, 2017
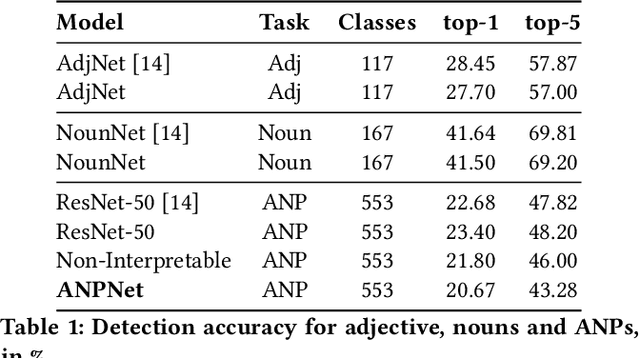
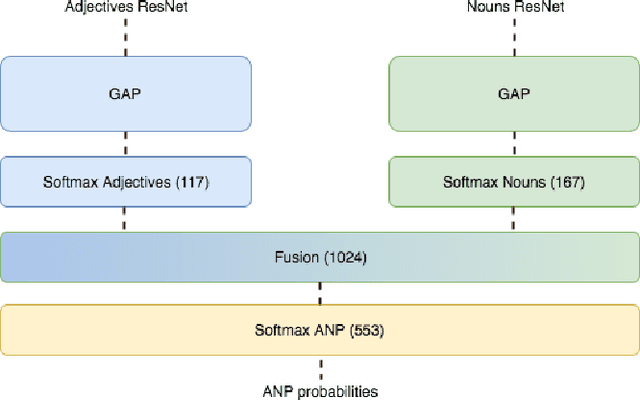
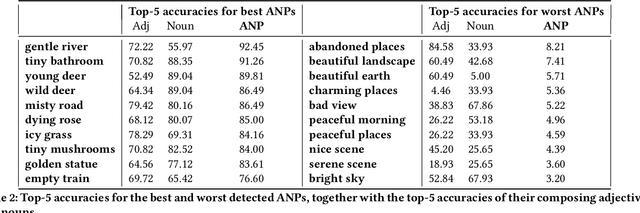
The increasing availability of affect-rich multimedia resources has bolstered interest in understanding sentiment and emotions in and from visual content. Adjective-noun pairs (ANP) are a popular mid-level semantic construct for capturing affect via visually detectable concepts such as "cute dog" or "beautiful landscape". Current state-of-the-art methods approach ANP prediction by considering each of these compound concepts as individual tokens, ignoring the underlying relationships in ANPs. This work aims at disentangling the contributions of the `adjectives' and `nouns' in the visual prediction of ANPs. Two specialised classifiers, one trained for detecting adjectives and another for nouns, are fused to predict 553 different ANPs. The resulting ANP prediction model is more interpretable as it allows us to study contributions of the adjective and noun components. Source code and models are available at https://imatge-upc.github.io/affective-2017-musa2/ .