 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Learning-to-Defer with Varying Experts
May 12, 2026Learning-to-Defer (L2D) methods route each query either to a predictive model or to external experts. While existing work studies this problem in batch settings, real-world deployments require handling streaming data, changing expert availability, and shifting expert distribution. We introduce the first online L2D algorithm for multiclass classification with bandit feedback and a dynamically varying pool of experts. Our method achieves regret guarantees of $O((n+n_e)T^{2/3})$ in general and $O((n+n_e)\sqrt{T})$ under a low-noise condition, where $T$ is the time horizon, $n$ is the number of labels, and $n_e$ is the number of distinct experts observed across rounds. The analysis builds on novel $\mathcal{H}$-consistency bounds for the online framework, combined with first-order methods for online convex optimization. Experiments on synthetic and real-world datasets demonstrate that our approach effectively extends standard Learning-to-Defer to settings with varying expert availability and reliability.
Beyond Augmented-Action Surrogates for Multi-Expert Learning-to-Defer
Apr 10, 2026Learning-to-Defer routes each input to the expert that minimizes expected cost, but it assumes that the information available to every expert is fixed at decision time. Many modern systems violate this assumption: after selecting an expert, one may also choose what additional information that expert should receive, such as retrieved documents, tool outputs, or escalation context. We study this problem and call it Learning-to-Defer with advice. We show that a broad family of natural separated surrogates, which learn routing and advice with distinct heads, is inconsistent even in the smallest non-trivial setting. We then introduce an augmented surrogate that operates on the composite expert--advice action space and prove an $\mathcal{H}$-consistency guarantee together with an excess-risk transfer bound, yielding recovery of the Bayes-optimal policy in the limit. Experiments on tabular, language, and multi-modal tasks show that the resulting method improves over standard Learning-to-Defer while adapting its advice-acquisition behavior to the cost regime; a synthetic benchmark confirms the failure mode predicted for separated surrogates.
SpikeCLR: Contrastive Self-Supervised Learning for Few-Shot Event-Based Vision using Spiking Neural Networks
Mar 17, 2026Event-based vision sensors provide significant advantages for high-speed perception, including microsecond temporal resolution, high dynamic range, and low power consumption. When combined with Spiking Neural Networks (SNNs), they can be deployed on neuromorphic hardware, enabling energy-efficient applications on embedded systems. However, this potential is severely limited by the scarcity of large-scale labeled datasets required to effectively train such models. In this work, we introduce SpikeCLR, a contrastive self-supervised learning framework that enables SNNs to learn robust visual representations from unlabeled event data. We adapt prior frame-based methods to the spiking domain using surrogate gradient training and introduce a suite of event-specific augmentations that leverage spatial, temporal, and polarity transformations. Through extensive experiments on CIFAR10-DVS, N-Caltech101, N-MNIST, and DVS-Gesture benchmarks, we demonstrate that self-supervised pretraining with subsequent fine-tuning outperforms supervised learning in low-data regimes, achieving consistent gains in few-shot and semi-supervised settings. Our ablation studies reveal that combining spatial and temporal augmentations is critical for learning effective spatio-temporal invariances in event data. We further show that learned representations transfer across datasets, contributing to efforts for powerful event-based models in label-scarce settings.
Learning-to-Defer with Expert-Conditioned Advice
Mar 15, 2026Learning-to-Defer routes each input to the expert that minimizes expected cost, but it assumes that the information available to every expert is fixed at decision time. Many modern systems violate this assumption: after selecting an expert, one may also choose what additional information that expert should receive, such as retrieved documents, tool outputs, or escalation context. We study this problem and call it Learning-to-Defer with advice. We show that a broad family of natural separated surrogates, which learn routing and advice with distinct heads, are inconsistent even in the smallest non-trivial setting. We then introduce an augmented surrogate that operates on the composite expert--advice action space and prove an $\mathcal{H}$-consistency guarantee together with an excess-risk transfer bound, yielding recovery of the Bayes-optimal policy in the limit. Experiments on tabular, LLMs, and multi-modal tasks show that the resulting method improves over standard Learning-to-Defer while adapting its advice-acquisition behavior to the cost regime.
Learning to Defer in Non-Stationary Time Series via Switching State-Space Models
Jan 30, 2026We study Learning to Defer for non-stationary time series with partial feedback and time-varying expert availability. At each time step, the router selects an available expert, observes the target, and sees only the queried expert's prediction. We model signed expert residuals using L2D-SLDS, a factorized switching linear-Gaussian state-space model with context-dependent regime transitions, a shared global factor enabling cross-expert information transfer, and per-expert idiosyncratic states. The model supports expert entry and pruning via a dynamic registry. Using one-step-ahead predictive beliefs, we propose an IDS-inspired routing rule that trades off predicted cost against information gained about the latent regime and shared factor. Experiments show improvements over contextual-bandit baselines and a no-shared-factor ablation.
One-Stage Top-$k$ Learning-to-Defer: Score-Based Surrogates with Theoretical Guarantees
May 15, 2025We introduce the first one-stage Top-$k$ Learning-to-Defer framework, which unifies prediction and deferral by learning a shared score-based model that selects the $k$ most cost-effective entities-labels or experts-per input. While existing one-stage L2D methods are limited to deferring to a single expert, our approach jointly optimizes prediction and deferral across multiple entities through a single end-to-end objective. We define a cost-sensitive loss and derive a novel convex surrogate that is independent of the cardinality parameter $k$, enabling generalization across Top-$k$ regimes without retraining. Our formulation recovers the Top-1 deferral policy of prior score-based methods as a special case, and we prove that our surrogate is both Bayes-consistent and $\mathcal{H}$-consistent under mild assumptions. We further introduce an adaptive variant, Top-$k(x)$, which dynamically selects the number of consulted entities per input to balance predictive accuracy and consultation cost. Experiments on CIFAR-10 and SVHN confirm that our one-stage Top-$k$ method strictly outperforms Top-1 deferral, while Top-$k(x)$ achieves superior accuracy-cost trade-offs by tailoring allocations to input complexity.
Why Ask One When You Can Ask $k$? Two-Stage Learning-to-Defer to the Top-$k$ Experts
Apr 22, 2025



Learning-to-Defer (L2D) enables decision-making systems to improve reliability by selectively deferring uncertain predictions to more competent agents. However, most existing approaches focus exclusively on single-agent deferral, which is often inadequate in high-stakes scenarios that require collective expertise. We propose Top-$k$ Learning-to-Defer, a generalization of the classical two-stage L2D framework that allocates each query to the $k$ most confident agents instead of a single one. To further enhance flexibility and cost-efficiency, we introduce Top-$k(x)$ Learning-to-Defer, an adaptive extension that learns the optimal number of agents to consult for each query, based on input complexity, agent competency distributions, and consultation costs. For both settings, we derive a novel surrogate loss and prove that it is Bayes-consistent and $(\mathcal{R}, \mathcal{G})$-consistent, ensuring convergence to the Bayes-optimal allocation. Notably, we show that the well-established model cascades paradigm arises as a restricted instance of our Top-$k$ and Top-$k(x)$ formulations. Extensive experiments across diverse benchmarks demonstrate the effectiveness of our framework on both classification and regression tasks.
Adversarial Robustness in Two-Stage Learning-to-Defer: Algorithms and Guarantees
Feb 03, 2025Learning-to-Defer (L2D) facilitates optimal task allocation between AI systems and decision-makers. Despite its potential, we show that current two-stage L2D frameworks are highly vulnerable to adversarial attacks, which can misdirect queries or overwhelm decision agents, significantly degrading system performance. This paper conducts the first comprehensive analysis of adversarial robustness in two-stage L2D frameworks. We introduce two novel attack strategies -- untargeted and targeted -- that exploit inherent structural vulnerabilities in these systems. To mitigate these threats, we propose SARD, a robust, convex, deferral algorithm rooted in Bayes and $(\mathcal{R},\mathcal{G})$-consistency. Our approach guarantees optimal task allocation under adversarial perturbations for all surrogates in the cross-entropy family. Extensive experiments on classification, regression, and multi-task benchmarks validate the robustness of SARD.
Cost-Effective Active Learning for Melanoma Segmentation
Nov 28, 2017
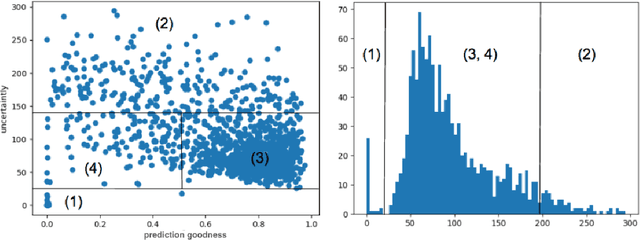
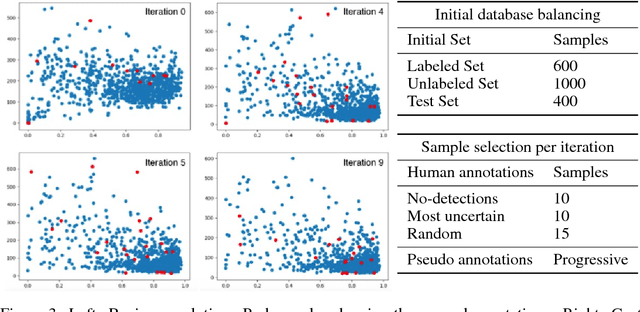
We propose a novel Active Learning framework capable to train effectively a convolutional neural network for semantic segmentation of medical imaging, with a limited amount of training labeled data. Our contribution is a practical Cost-Effective Active Learning approach using dropout at test time as Monte Carlo sampling to model the pixel-wise uncertainty and to analyze the image information to improve the training performance. The source code of this project is available at https://marc-gorriz.github.io/CEAL-Medical-Image-Segmentation/ .
Quality Control in Crowdsourced Object Segmentation
May 01, 2015

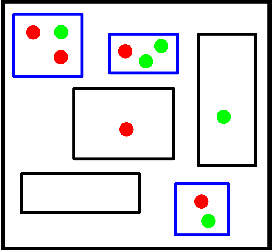
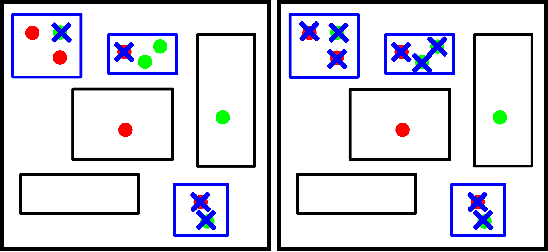
This paper explores processing techniques to deal with noisy data in crowdsourced object segmentation tasks. We use the data collected with "Click'n'Cut", an online interactive segmentation tool, and we perform several experiments towards improving the segmentation results. First, we introduce different superpixel-based techniques to filter users' traces, and assess their impact on the segmentation result. Second, we present different criteria to detect and discard the traces from potential bad users, resulting in a remarkable increase in performance. Finally, we show a novel superpixel-based segmentation algorithm which does not require any prior filtering and is based on weighting each user's contribution according to his/her level of expertise.