 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoMamba: A Geometry-driven MambaVision Framework and Dataset for Fine-grained Optical-SAR Object Retrieval
May 19, 2026Multi-source remote sensing enables complementary observation of ground objects, while cross-modal fine-grained object retrieval remains challenging, especially under unaligned optical and SAR conditions. Unlike conventional retrieval settings that rely on paired or spatially aligned samples, practical optical-SAR retrieval is affected by substantial modality discrepancy, speckle noise, and structural inconsistency, which limit robust cross-modal representation learning. To address this problem, we propose GeoMamba, a geometry-driven framework tailored for optical-SAR fine-grained retrieval. Specifically, GeoMamba introduces a Geometric Feature Injection (GFI) module that enhances cross-modal feature interaction and incorporates structural priors, thereby improving the robustness of SAR representations and promoting geometry-consistent feature learning. In addition, a Geometric Consistency Constraint (GCC) module, together with a Deep Supervision (DS) strategy, imposes hierarchical geometric constraints using classical operators, which helps preserve informative object structures during representation learning. We further construct a new dataset, FGOS-as, containing 11 aerospace and maritime categories for evaluating unaligned cross-modal fine-grained object retrieval in realistic remote sensing scenarios. Extensive experiments on FGOS-as demonstrate that GeoMamba outperforms existing methods, achieving 63.3% mAP and 77.0% Rank-1 accuracy in all-to-all retrieval setting.
Edge-aware Guidance Fusion Network for RGB Thermal Scene Parsing
Dec 09, 2021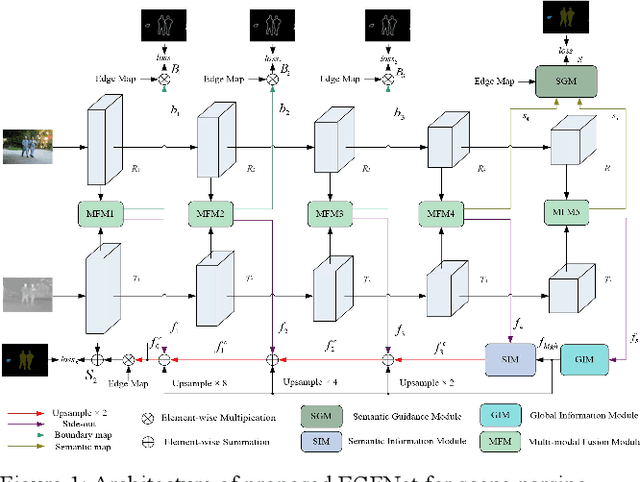
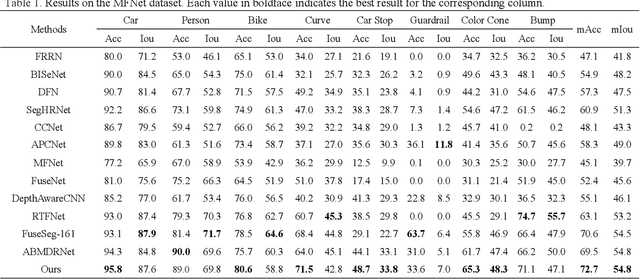
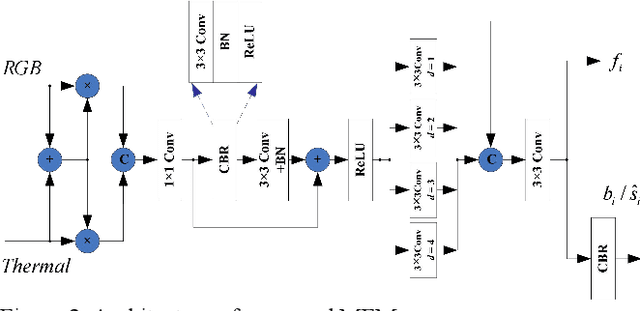

RGB thermal scene parsing has recently attracted increasing research interest in the field of computer vision. However, most existing methods fail to perform good boundary extraction for prediction maps and cannot fully use high level features. In addition, these methods simply fuse the features from RGB and thermal modalities but are unable to obtain comprehensive fused features. To address these problems, we propose an edge-aware guidance fusion network (EGFNet) for RGB thermal scene parsing. First, we introduce a prior edge map generated using the RGB and thermal images to capture detailed information in the prediction map and then embed the prior edge information in the feature maps. To effectively fuse the RGB and thermal information, we propose a multimodal fusion module that guarantees adequate cross-modal fusion. Considering the importance of high level semantic information, we propose a global information module and a semantic information module to extract rich semantic information from the high-level features. For decoding, we use simple elementwise addition for cascaded feature fusion. Finally, to improve the parsing accuracy, we apply multitask deep supervision to the semantic and boundary maps. Extensive experiments were performed on benchmark datasets to demonstrate the effectiveness of the proposed EGFNet and its superior performance compared with state of the art methods. The code and results can be found at https://github.com/ShaohuaDong2021/EGFNet.