 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Code Hashing for Efficient Image Retrieval
Aug 04, 2020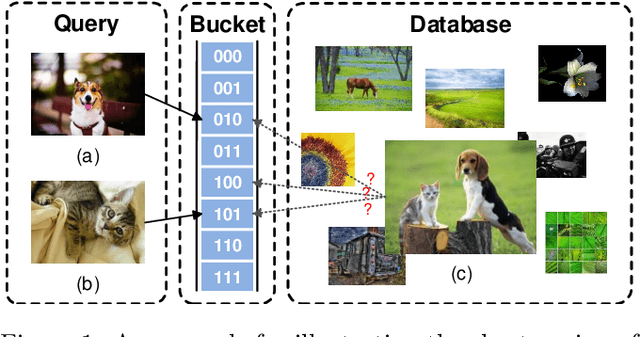

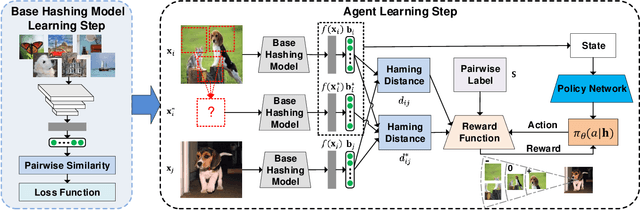
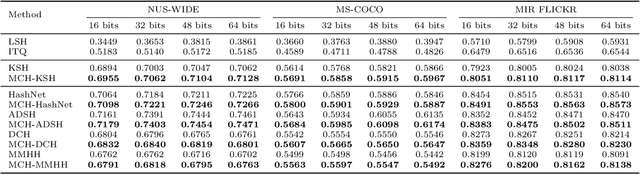
Due to its low storage cost and fast query speed, hashing has been widely used in large-scale image retrieval tasks. Hash bucket search returns data points within a given Hamming radius to each query, which can enable search at a constant or sub-linear time cost. However, existing hashing methods cannot achieve satisfactory retrieval performance for hash bucket search in complex scenarios, since they learn only one hash code for each image. More specifically, by using one hash code to represent one image, existing methods might fail to put similar image pairs to the buckets with a small Hamming distance to the query when the semantic information of images is complex. As a result, a large number of hash buckets need to be visited for retrieving similar images, based on the learned codes. This will deteriorate the efficiency of hash bucket search. In this paper, we propose a novel hashing framework, called multiple code hashing (MCH), to improve the performance of hash bucket search. The main idea of MCH is to learn multiple hash codes for each image, with each code representing a different region of the image. Furthermore, we propose a deep reinforcement learning algorithm to learn the parameters in MCH. To the best of our knowledge, this is the first work that proposes to learn multiple hash codes for each image in image retrieval. Experiments demonstrate that MCH can achieve a significant improvement in hash bucket search, compared with existing methods that learn only one hash code for each image.
ExchNet: A Unified Hashing Network for Large-Scale Fine-Grained Image Retrieval
Aug 04, 2020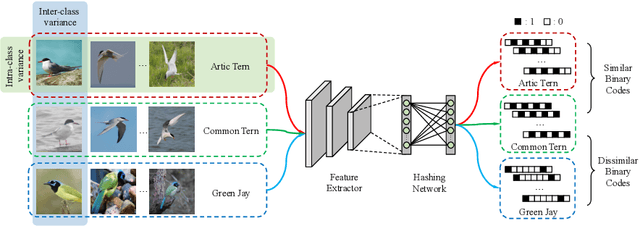
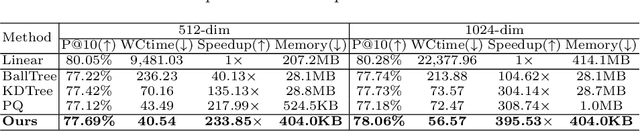
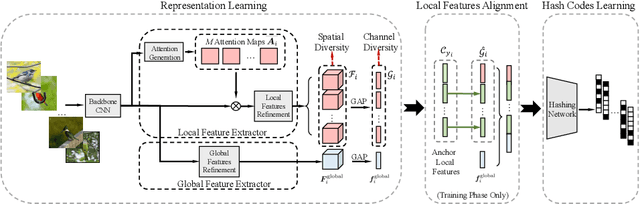
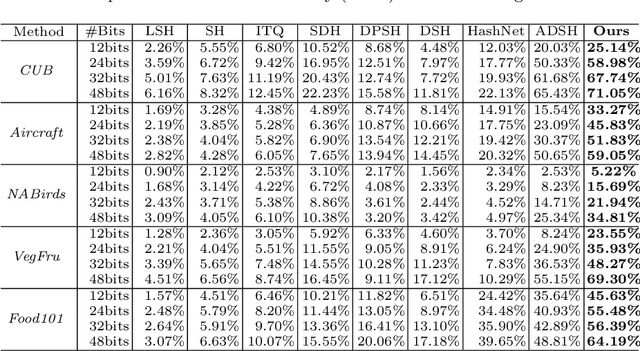
Retrieving content relevant images from a large-scale fine-grained dataset could suffer from intolerably slow query speed and highly redundant storage cost, due to high-dimensional real-valued embeddings which aim to distinguish subtle visual differences of fine-grained objects. In this paper, we study the novel fine-grained hashing topic to generate compact binary codes for fine-grained images, leveraging the search and storage efficiency of hash learning to alleviate the aforementioned problems. Specifically, we propose a unified end-to-end trainable network, termed as ExchNet. Based on attention mechanisms and proposed attention constraints, it can firstly obtain both local and global features to represent object parts and whole fine-grained objects, respectively. Furthermore, to ensure the discriminative ability and semantic meaning's consistency of these part-level features across images, we design a local feature alignment approach by performing a feature exchanging operation. Later, an alternative learning algorithm is employed to optimize the whole ExchNet and then generate the final binary hash codes. Validated by extensive experiments, our proposal consistently outperforms state-of-the-art generic hashing methods on five fine-grained datasets, which shows our effectiveness. Moreover, compared with other approximate nearest neighbor methods, ExchNet achieves the best speed-up and storage reduction, revealing its efficiency and practicality.
Stochastic Normalized Gradient Descent with Momentum for Large Batch Training
Jul 28, 2020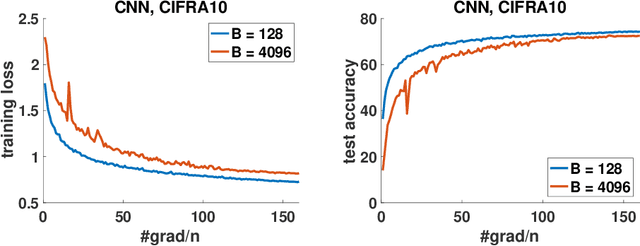

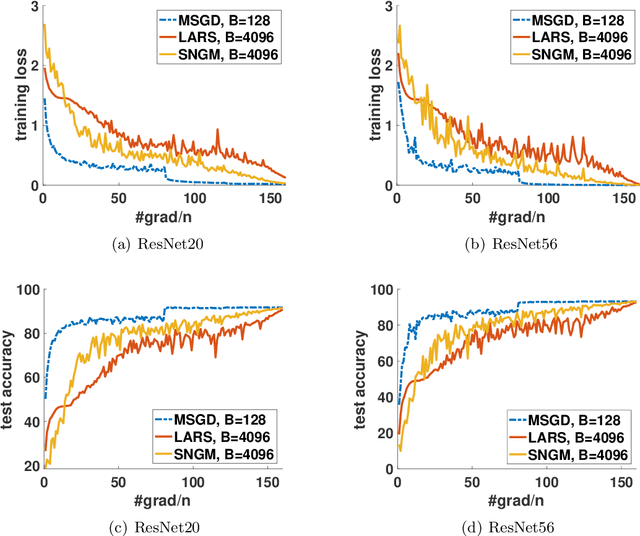
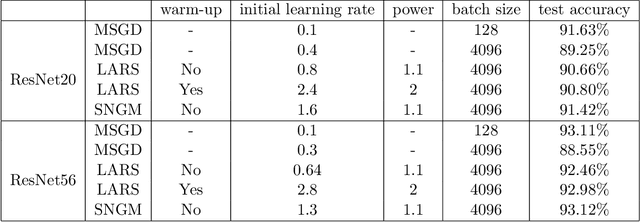
Stochastic gradient descent (SGD) and its variants have been the dominating optimization methods in machine learning. Compared with small batch training, SGD with large batch training can better utilize the computational power of current multi-core systems like GPUs and can reduce the number of communication rounds in distributed training. Hence, SGD with large batch training has attracted more and more attention. However, existing empirical results show that large batch training typically leads to a drop of generalization accuracy. As a result, large batch training has also become a challenging topic. In this paper, we propose a novel method, called stochastic normalized gradient descent with momentum (SNGM), for large batch training. We theoretically prove that compared to momentum SGD (MSGD) which is one of the most widely used variants of SGD, SNGM can adopt a larger batch size to converge to the $\epsilon$-stationary point with the same computation complexity (total number of gradient computation). Empirical results on deep learning also show that SNGM can achieve the state-of-the-art accuracy with a large batch size.
TOMA: Topological Map Abstraction for Reinforcement Learning
May 11, 2020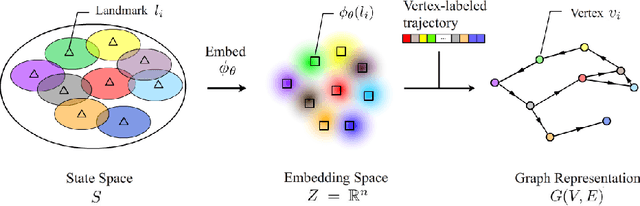

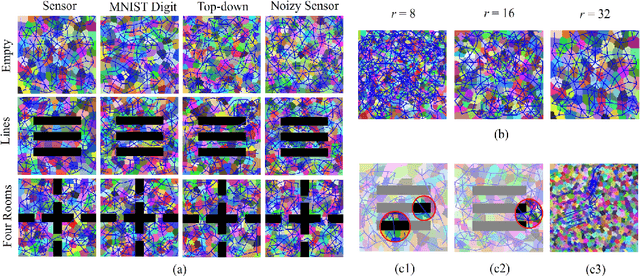
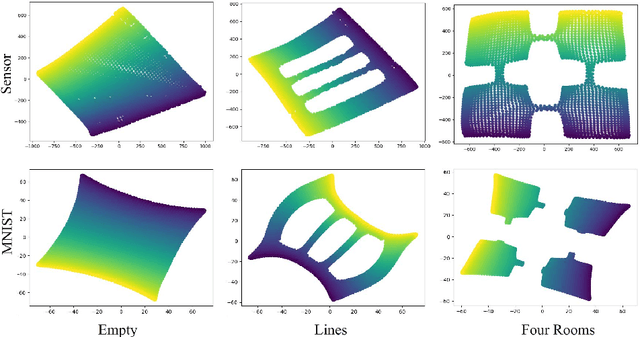
Animals are able to discover the topological map (graph) of surrounding environment, which will be used for navigation. Inspired by this biological phenomenon, researchers have recently proposed to generate topological map (graph) representation for Markov decision process (MDP) and use such graphs for planning in reinforcement learning (RL). However, existing graph generation methods suffer from many drawbacks. One drawback is that existing methods do not learn an abstraction for graphs, which results in high memory cost. Another drawback is that these existing methods can only work in some specific settings, which limits their application. In this paper, we propose a new method, called TOpological Map Abstraction (TOMA), for graph generation. TOMA can generate an abstract graph representation for MDP, which costs much less memory than existing methods. Furthermore, the generated graphs of TOMA can be used as a basic multi-purpose tool for different RL applications. As an application example, we propose planning to explore, in which TOMA is used to accelerate exploration by guiding the agent towards unexplored states. A novel experience replay module called vertex memory is also proposed to improve exploration performance. Experimental results show that TOMA can robustly generate abstract graph representation on several 2D world environments with different types of observation. Under the guidance of such graph representation, the agent can escape local minima during exploration.
BASGD: Buffered Asynchronous SGD for Byzantine Learning
Mar 03, 2020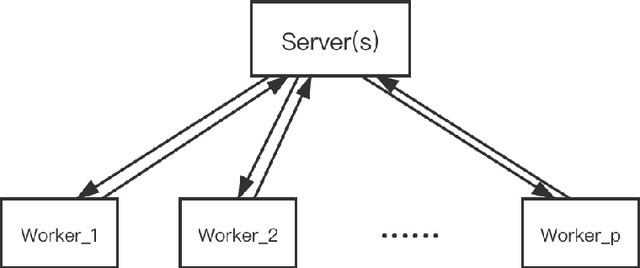
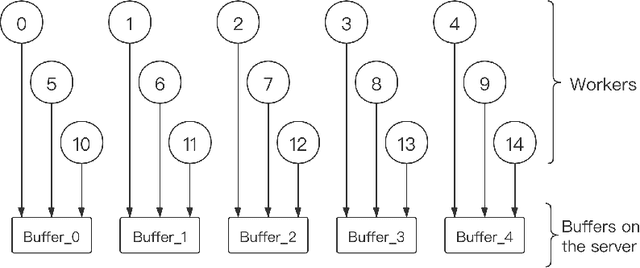
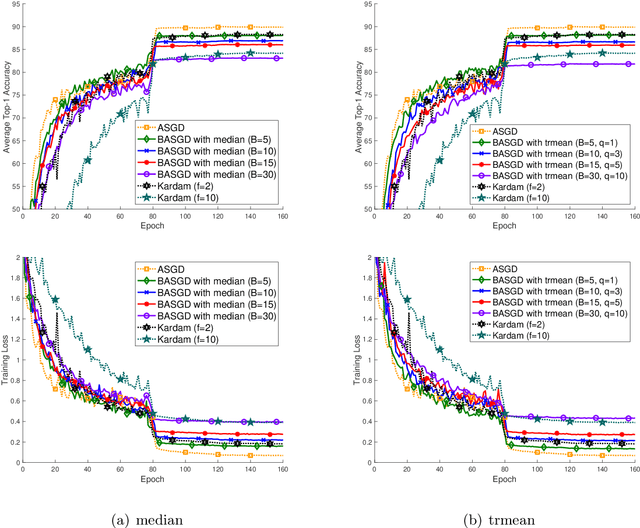
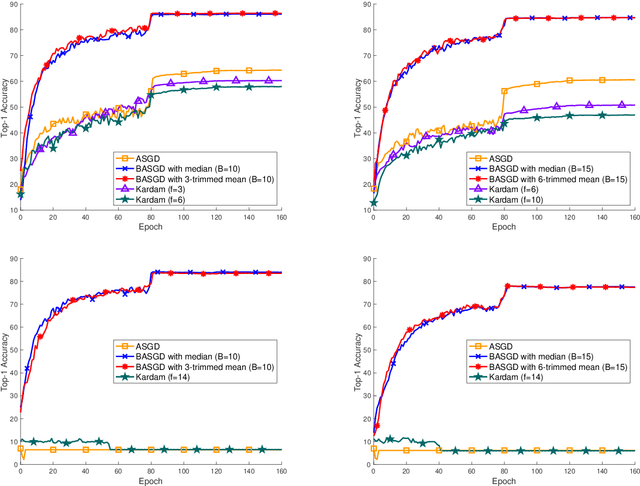
Distributed learning has become a hot research topic, due to its wide application in cluster-based large-scale learning, federated learning, edge computing and so on. Most distributed learning methods assume no error and attack on the workers. However, many unexpected cases, such as communication error and even malicious attack, may happen in real applications. Hence, Byzantine learning (BL), which refers to distributed learning with attack or error, has recently attracted much attention. Most existing BL methods are synchronous, which will result in slow convergence when there exist heterogeneous workers. Furthermore, in some applications like federated learning and edge computing, synchronization cannot even be performed most of the time due to the online workers (clients or edge servers). Hence, asynchronous BL (ABL) is more general and practical than synchronous BL (SBL). To the best of our knowledge, there exist only two ABL methods. One of them cannot resist malicious attack. The other needs to store some training instances on the server, which has the privacy leak problem. In this paper, we propose a novel method, called buffered asynchronous stochastic gradient descent (BASGD), for BL. BASGD is an asynchronous method. Furthermore, BASGD has no need to store any training instances on the server, and hence can preserve privacy in ABL. BASGD is theoretically proved to have the ability of resisting against error and malicious attack. Moreover, BASGD has a similar theoretical convergence rate to that of vanilla asynchronous SGD (ASGD), with an extra constant variance. Empirical results show that BASGD can significantly outperform vanilla ASGD and other ABL baselines, when there exists error or attack on workers.
Stagewise Enlargement of Batch Size for SGD-based Learning
Feb 27, 2020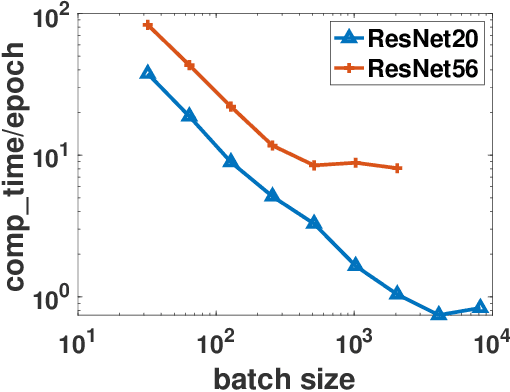
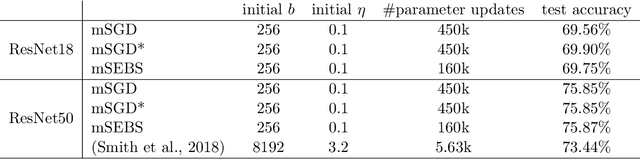
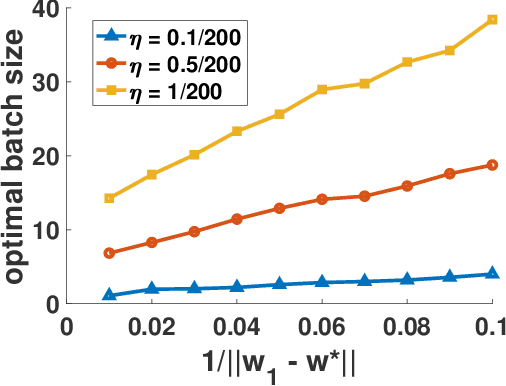
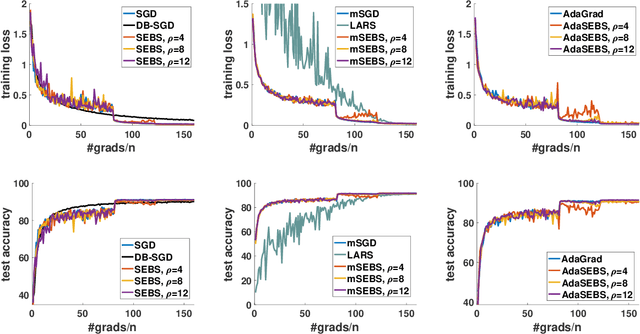
Existing research shows that the batch size can seriously affect the performance of stochastic gradient descent~(SGD) based learning, including training speed and generalization ability. A larger batch size typically results in less parameter updates. In distributed training, a larger batch size also results in less frequent communication. However, a larger batch size can make a generalization gap more easily. Hence, how to set a proper batch size for SGD has recently attracted much attention. Although some methods about setting batch size have been proposed, the batch size problem has still not been well solved. In this paper, we first provide theory to show that a proper batch size is related to the gap between initialization and optimum of the model parameter. Then based on this theory, we propose a novel method, called \underline{s}tagewise \underline{e}nlargement of \underline{b}atch \underline{s}ize~(\mbox{SEBS}), to set proper batch size for SGD. More specifically, \mbox{SEBS} adopts a multi-stage scheme, and enlarges the batch size geometrically by stage. We theoretically prove that, compared to classical stagewise SGD which decreases learning rate by stage, \mbox{SEBS} can reduce the number of parameter updates without increasing generalization error. SEBS is suitable for \mbox{SGD}, momentum \mbox{SGD} and AdaGrad. Empirical results on real data successfully verify the theories of \mbox{SEBS}. Furthermore, empirical results also show that SEBS can outperform other baselines.
Weight Normalization based Quantization for Deep Neural Network Compression
Jul 01, 2019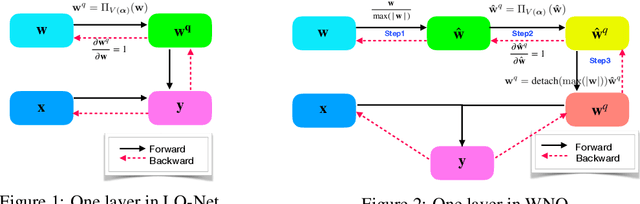
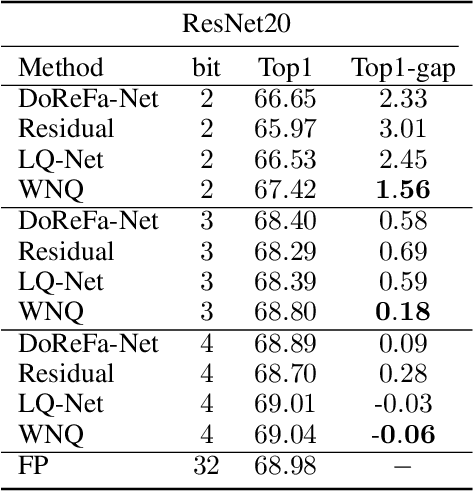
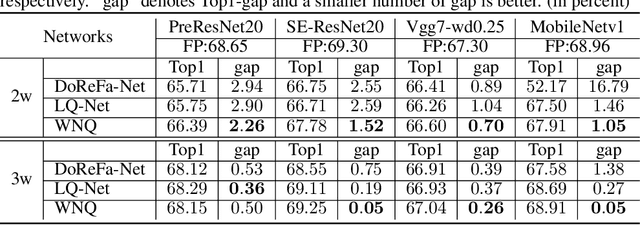
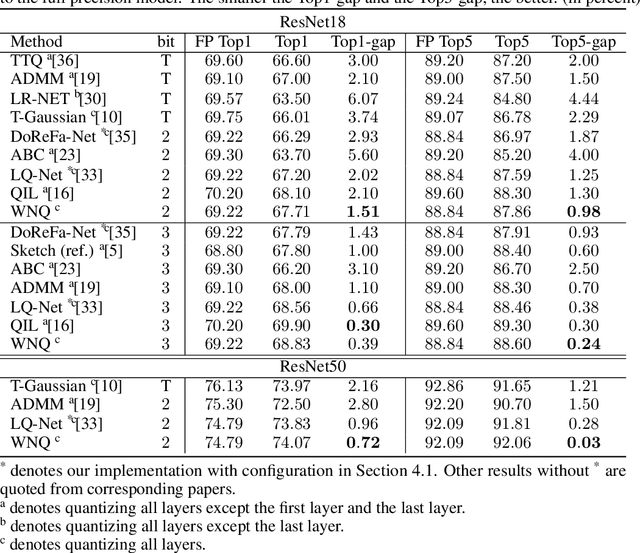
With the development of deep neural networks, the size of network models becomes larger and larger. Model compression has become an urgent need for deploying these network models to mobile or embedded devices. Model quantization is a representative model compression technique. Although a lot of quantization methods have been proposed, many of them suffer from a high quantization error caused by a long-tail distribution of network weights. In this paper, we propose a novel quantization method, called weight normalization based quantization (WNQ), for model compression. WNQ adopts weight normalization to avoid the long-tail distribution of network weights and subsequently reduces the quantization error. Experiments on CIFAR-100 and ImageNet show that WNQ can outperform other baselines to achieve state-of-the-art performance.
ADASS: Adaptive Sample Selection for Training Acceleration
Jun 11, 2019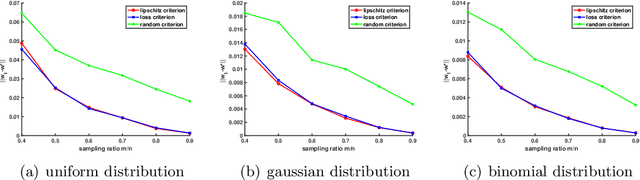
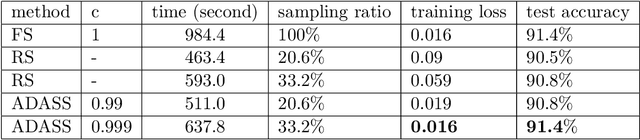
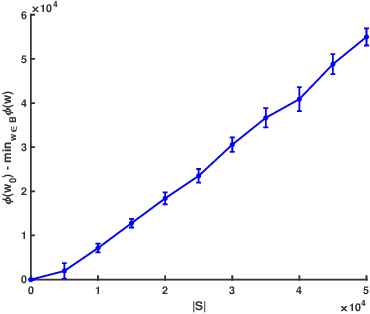
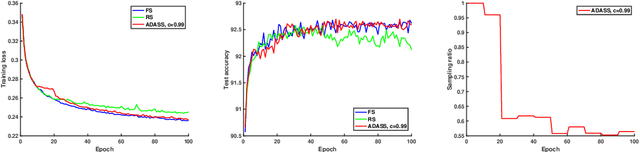
Stochastic gradient decent~(SGD) and its variants, including some accelerated variants, have become popular for training in machine learning. However, in all existing SGD and its variants, the sample size in each iteration~(epoch) of training is the same as the size of the full training set. In this paper, we propose a new method, called \underline{ada}ptive \underline{s}ample \underline{s}election~(ADASS), for training acceleration. During different epoches of training, ADASS only need to visit different training subsets which are adaptively selected from the full training set according to the Lipschitz constants of the loss functions on samples. It means that in ADASS the sample size in each epoch of training can be smaller than the size of the full training set, by discarding some samples. ADASS can be seamlessly integrated with existing optimization methods, such as SGD and momentum SGD, for training acceleration. Theoretical results show that the learning accuracy of ADASS is comparable to that of counterparts with full training set. Furthermore, empirical results on both shallow models and deep models also show that ADASS can accelerate the training process of existing methods without sacrificing accuracy.
Clustered Reinforcement Learning
Jun 06, 2019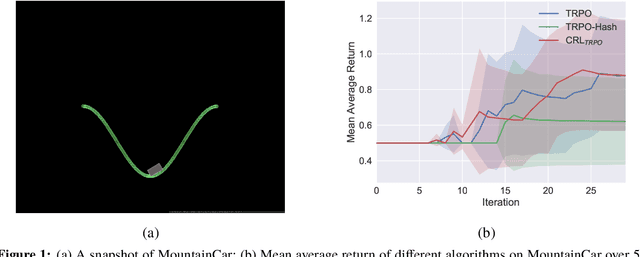
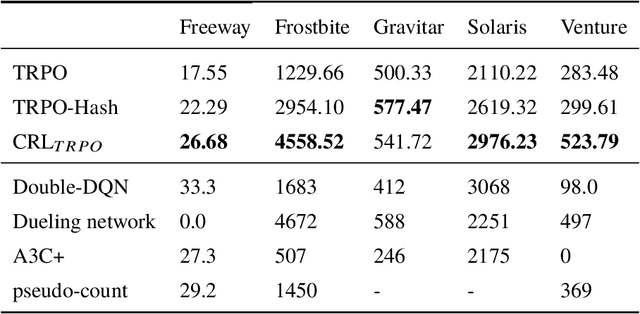
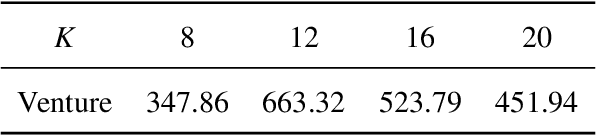
Exploration strategy design is one of the challenging problems in reinforcement learning~(RL), especially when the environment contains a large state space or sparse rewards. During exploration, the agent tries to discover novel areas or high reward~(quality) areas. In most existing methods, the novelty and quality in the neighboring area of the current state are not well utilized to guide the exploration of the agent. To tackle this problem, we propose a novel RL framework, called \underline{c}lustered \underline{r}einforcement \underline{l}earning~(CRL), for efficient exploration in RL. CRL adopts clustering to divide the collected states into several clusters, based on which a bonus reward reflecting both novelty and quality in the neighboring area~(cluster) of the current state is given to the agent. Experiments on a continuous control task and several \emph{Atari 2600} games show that CRL can outperform other state-of-the-art methods to achieve the best performance in most cases.
On the Convergence of Memory-Based Distributed SGD
May 30, 2019
Distributed stochastic gradient descent~(DSGD) has been widely used for optimizing large-scale machine learning models, including both convex and non-convex models. With the rapid growth of model size, huge communication cost has been the bottleneck of traditional DSGD. Recently, many communication compression methods have been proposed. Memory-based distributed stochastic gradient descent~(M-DSGD) is one of the efficient methods since each worker communicates a sparse vector in each iteration so that the communication cost is small. Recent works propose the convergence rate of M-DSGD when it adopts vanilla SGD. However, there is still a lack of convergence theory for M-DSGD when it adopts momentum SGD. In this paper, we propose a universal convergence analysis for M-DSGD by introducing \emph{transformation equation}. The transformation equation describes the relation between traditional DSGD and M-DSGD so that we can transform M-DSGD to its corresponding DSGD. Hence we get the convergence rate of M-DSGD with momentum for both convex and non-convex problems. Furthermore, we combine M-DSGD and stagewise learning that the learning rate of M-DSGD in each stage is a constant and is decreased by stage, instead of iteration. Using the transformation equation, we propose the convergence rate of stagewise M-DSGD which bridges the gap between theory and practice.