 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposing Non-Conjugate Factor Graphs with Closed-Form Variational Inference
May 28, 2026Stacking probabilistic building blocks into deeper architectures typically breaks closed-form inference. We show that closed-form inference can be preserved. We identify five factor-graph primitives: a bilinear factor, an exponential link, a Gamma prior, a Gaussian likelihood, and an equality node, and prove that any model composed from them admits closed-form variational message passing. The construction works because each primitive preserves a small set of message families: under mean-field factorization, messages on Gaussian variables remain Gaussian and messages on precision variables remain Gamma, while the only non-conjugate interface, the exponential link, remains tractable through the Gaussian moment-generating function and the sufficient statistics of the Gamma family. We demonstrate composition at increasing depth, from static ensembles through input-dependent gating to split-branch routing, and show that stacking routing layers encodes arbitrary decision trees, establishing universal function approximation with closed-form inference. Applied to ensemble time-series forecasting, the framework yields a Bayesian mixture of experts in which gating functions are inferred rather than learned, providing calibrated uncertainty over expert selection across five benchmark datasets.
Spike-Timing-Dependent Plasticity for Bernoulli Message Passing
Dec 19, 2025Bayesian inference provides a principled framework for understanding brain function, while neural activity in the brain is inherently spike-based. This paper bridges these two perspectives by designing spiking neural networks that simulate Bayesian inference through message passing for Bernoulli messages. To train the networks, we employ spike-timing-dependent plasticity, a biologically plausible mechanism for synaptic plasticity which is based on the Hebbian rule. Our results demonstrate that the network's performance closely matches the true numerical solution. We further demonstrate the versatility of our approach by implementing a factor graph example from coding theory, illustrating signal transmission over an unreliable channel.
A Spiking Neural Network Implementation of Gaussian Belief Propagation
Dec 11, 2025Bayesian inference offers a principled account of information processing in natural agents. However, it remains an open question how neural mechanisms perform their abstract operations. We investigate a hypothesis where a distributed form of Bayesian inference, namely message passing on factor graphs, is performed by a simulated network of leaky-integrate-and-fire neurons. Specifically, we perform Gaussian belief propagation by encoding messages that come into factor nodes as spike-based signals, propagating these signals through a spiking neural network (SNN) and decoding the spike-based signal back to an outgoing message. Three core linear operations, equality (branching), addition, and multiplication, are realized in networks of leaky integrate-and-fire models. Validation against the standard sum-product algorithm shows accurate message updates, while applications to Kalman filtering and Bayesian linear regression demonstrate the framework's potential for both static and dynamic inference tasks. Our results provide a step toward biologically grounded, neuromorphic implementations of probabilistic reasoning.
Coupled autoregressive active inference agents for control of multi-joint dynamical systems
Oct 14, 2024


We propose an active inference agent to identify and control a mechanical system with multiple bodies connected by joints. This agent is constructed from multiple scalar autoregressive model-based agents, coupled together by virtue of sharing memories. Each subagent infers parameters through Bayesian filtering and controls by minimizing expected free energy over a finite time horizon. We demonstrate that a coupled agent of this kind is able to learn the dynamics of a double mass-spring-damper system, and drive it to a desired position through a balance of explorative and exploitative actions. It outperforms the uncoupled subagents in terms of surprise and goal alignment.
Planning to avoid ambiguous states through Gaussian approximations to non-linear sensors in active inference agents
Sep 03, 2024


In nature, active inference agents must learn how observations of the world represent the state of the agent. In engineering, the physics behind sensors is often known reasonably accurately and measurement functions can be incorporated into generative models. When a measurement function is non-linear, the transformed variable is typically approximated with a Gaussian distribution to ensure tractable inference. We show that Gaussian approximations that are sensitive to the curvature of the measurement function, such as a second-order Taylor approximation, produce a state-dependent ambiguity term. This induces a preference over states, based on how accurately the state can be inferred from the observation. We demonstrate this preference with a robot navigation experiment where agents plan trajectories.
Bayesian grey-box identification of nonlinear convection effects in heat transfer dynamics
Jul 01, 2024



We propose a computational procedure for identifying convection in heat transfer dynamics. The procedure is based on a Gaussian process latent force model, consisting of a white-box component (i.e., known physics) for the conduction and linear convection effects and a Gaussian process that acts as a black-box component for the nonlinear convection effects. States are inferred through Bayesian smoothing and we obtain approximate posterior distributions for the kernel covariance function's hyperparameters using Laplace's method. The nonlinear convection function is recovered from the Gaussian process states using a Bayesian regression model. We validate the procedure by simulation error using the identified nonlinear convection function, on both data from a simulated system and measurements from a physical assembly.
Information-seeking polynomial NARX model-predictive control through expected free energy minimization
Dec 22, 2023


We propose an adaptive model-predictive controller that balances driving the system to a goal state and seeking system observations that are informative with respect to the parameters of a nonlinear autoregressive exogenous model. The controller's objective function is derived from an expected free energy functional and contains information-theoretic terms expressing uncertainty over model parameters and output predictions. Experiments illustrate how parameter uncertainty affects the control objective and evaluate the proposed controller for a pendulum swing-up task.
Variational Bayes for robust radar single object tracking
Sep 28, 2022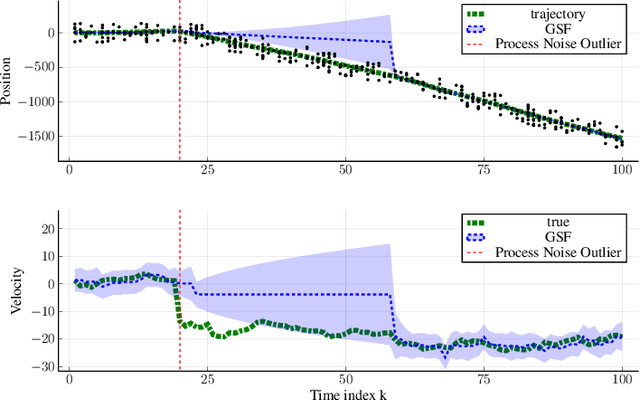
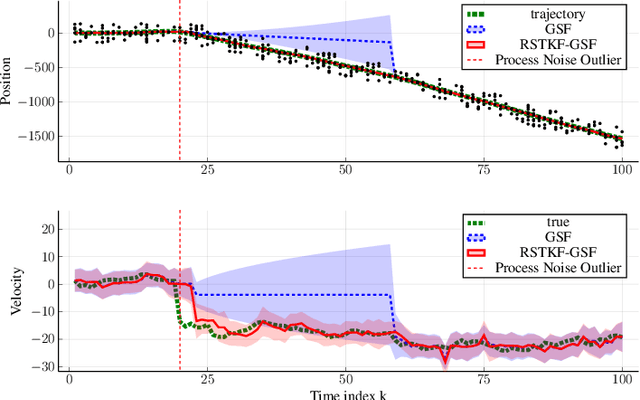
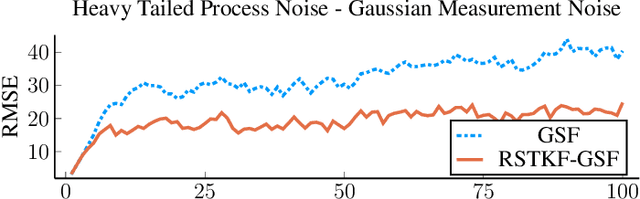
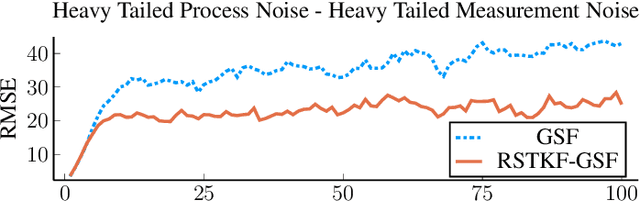
We address object tracking by radar and the robustness of the current state-of-the-art methods to process outliers. The standard tracking algorithms extract detections from radar image space to use it in the filtering stage. Filtering is performed by a Kalman filter, which assumes Gaussian distributed noise. However, this assumption does not account for large modeling errors and results in poor tracking performance during abrupt motions. We take the Gaussian Sum Filter (single-object variant of the Multi Hypothesis Tracker) as our baseline and propose a modification by modelling process noise with a distribution that has heavier tails than a Gaussian. Variational Bayes provides a fast, computationally cheap inference algorithm. Our simulations show that - in the presence of process outliers - the robust tracker outperforms the Gaussian Sum filter when tracking single objects.
The Data Representativeness Criterion: Predicting the Performance of Supervised Classification Based on Data Set Similarity
Feb 27, 2020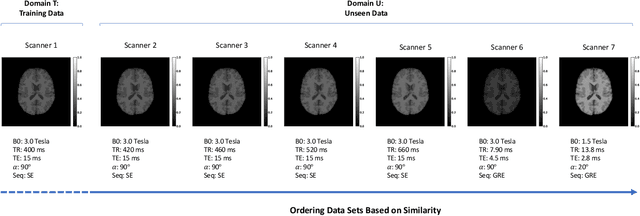
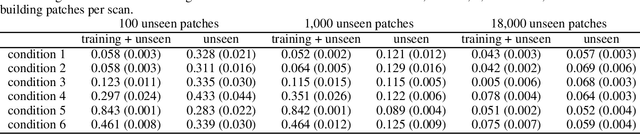
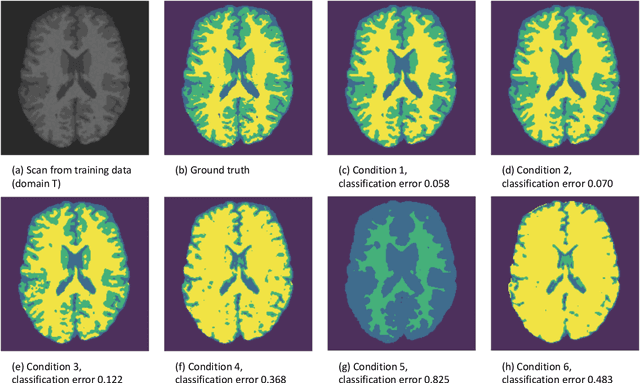
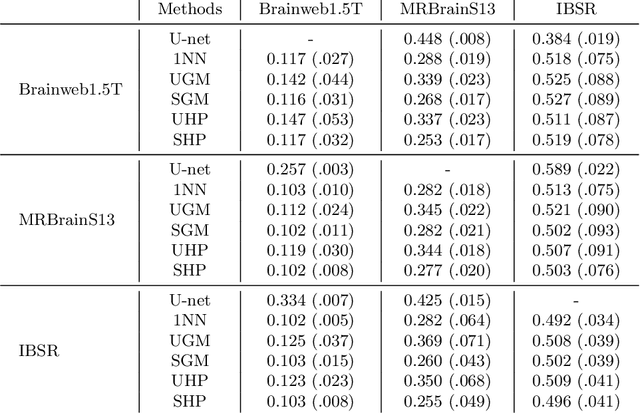
In a broad range of fields it may be desirable to reuse a supervised classification algorithm and apply it to a new data set. However, generalization of such an algorithm and thus achieving a similar classification performance is only possible when the training data used to build the algorithm is similar to new unseen data one wishes to apply it to. It is often unknown in advance how an algorithm will perform on new unseen data, being a crucial reason for not deploying an algorithm at all. Therefore, tools are needed to measure the similarity of data sets. In this paper, we propose the Data Representativeness Criterion (DRC) to determine how representative a training data set is of a new unseen data set. We present a proof of principle, to see whether the DRC can quantify the similarity of data sets and whether the DRC relates to the performance of a supervised classification algorithm. We compared a number of magnetic resonance imaging (MRI) data sets, ranging from subtle to severe difference is acquisition parameters. Results indicate that, based on the similarity of data sets, the DRC is able to give an indication as to when the performance of a supervised classifier decreases. The strictness of the DRC can be set by the user, depending on what one considers to be an acceptable underperformance.
A cross-center smoothness prior for variational Bayesian brain tissue segmentation
Mar 11, 2019
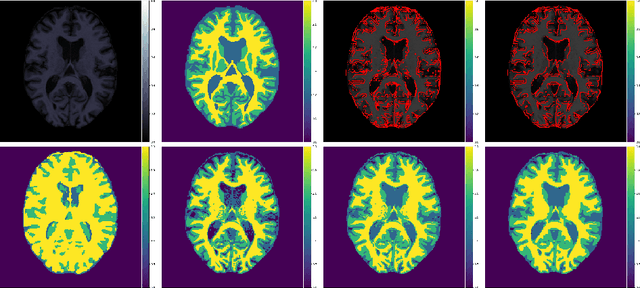
Suppose one is faced with the challenge of tissue segmentation in MR images, without annotators at their center to provide labeled training data. One option is to go to another medical center for a trained classifier. Sadly, tissue classifiers do not generalize well across centers due to voxel intensity shifts caused by center-specific acquisition protocols. However, certain aspects of segmentations, such as spatial smoothness, remain relatively consistent and can be learned separately. Here we present a smoothness prior that is fit to segmentations produced at another medical center. This informative prior is presented to an unsupervised Bayesian model. The model clusters the voxel intensities, such that it produces segmentations that are similarly smooth to those of the other medical center. In addition, the unsupervised Bayesian model is extended to a semi-supervised variant, which needs no visual interpretation of clusters into tissues.