 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyleKQC: A Style-Variant Paraphrase Corpus for Korean Questions and Commands
Mar 24, 2021
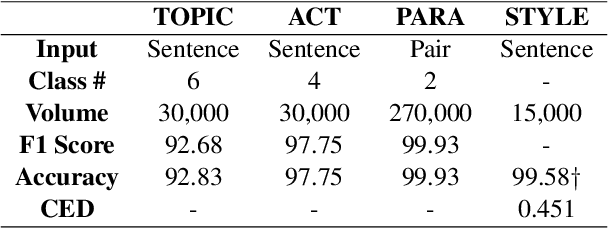
Paraphrasing is often performed with less concern for controlled style conversion. Especially for questions and commands, style-variant paraphrasing can be crucial in tone and manner, which also matters with industrial applications such as dialog system. In this paper, we attack this issue with a corpus construction scheme that simultaneously considers the core content and style of directives, namely intent and formality, for the Korean language. Utilizing manually generated natural language queries on six daily topics, we expand the corpus to formal and informal sentences by human rewriting and transferring. We verify the validity and industrial applicability of our approach by checking the adequate classification and inference performance that fit with the fine-tuning approaches, at the same time proposing a supervised formality transfer task.
Open Korean Corpora: A Practical Report
Dec 31, 2020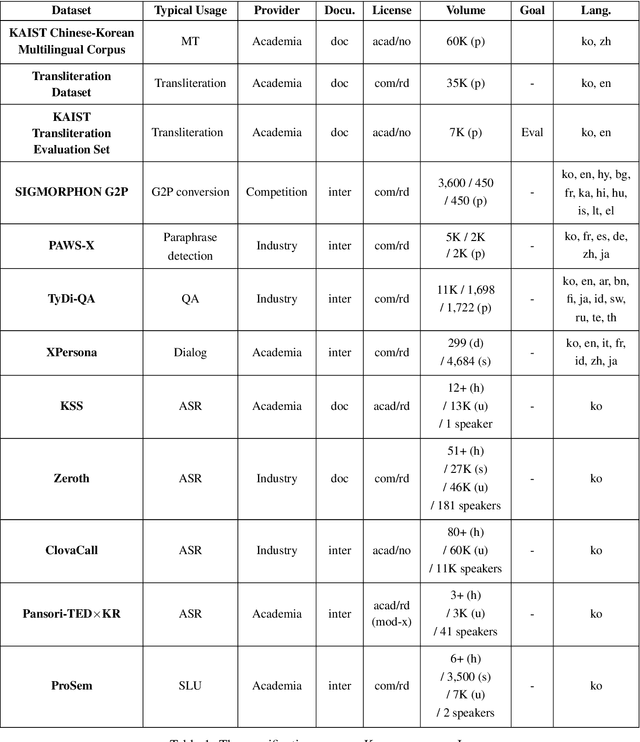
Korean is often referred to as a low-resource language in the research community. While this claim is partially true, it is also because the availability of resources is inadequately advertised and curated. This work curates and reviews a list of Korean corpora, first describing institution-level resource development, then further iterate through a list of current open datasets for different types of tasks. We then propose a direction on how open-source dataset construction and releases should be done for less-resourced languages to promote research.
BEEP! Korean Corpus of Online News Comments for Toxic Speech Detection
May 26, 2020
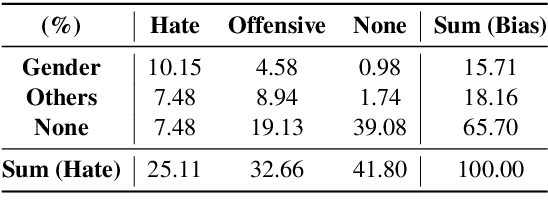
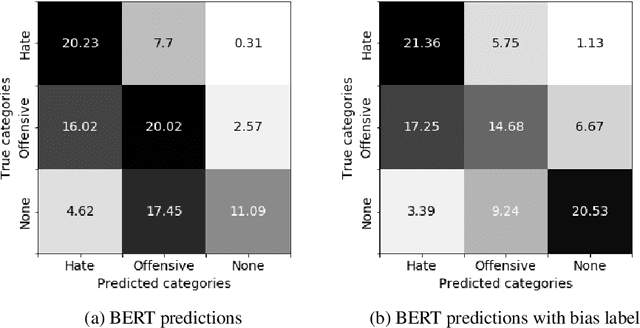
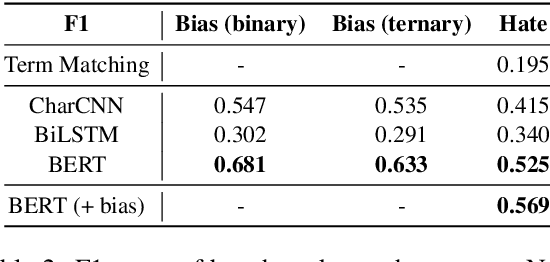
Toxic comments in online platforms are an unavoidable social issue under the cloak of anonymity. Hate speech detection has been actively done for languages such as English, German, or Italian, where manually labeled corpus has been released. In this work, we first present 9.4K manually labeled entertainment news comments for identifying Korean toxic speech, collected from a widely used online news platform in Korea. The comments are annotated regarding social bias and hate speech since both aspects are correlated. The inter-annotator agreement Krippendorff's alpha score is 0.492 and 0.496, respectively. We provide benchmarks using CharCNN, BiLSTM, and BERT, where BERT achieves the highest score on all tasks. The models generally display better performance on bias identification, since the hate speech detection is a more subjective issue. Additionally, when BERT is trained with bias label for hate speech detection, the prediction score increases, implying that bias and hate are intertwined. We make our dataset publicly available and open competitions with the corpus and benchmarks.
Speech to Text Adaptation: Towards an Efficient Cross-Modal Distillation
May 17, 2020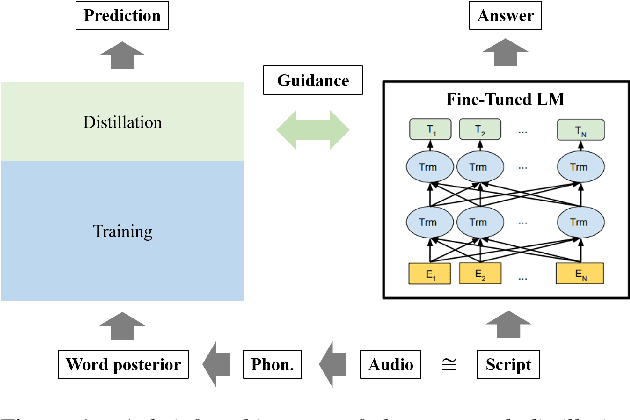
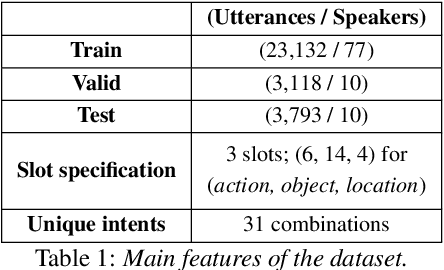
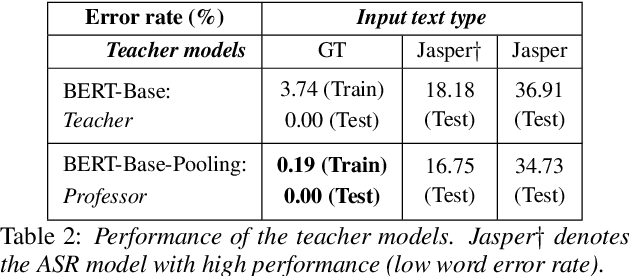
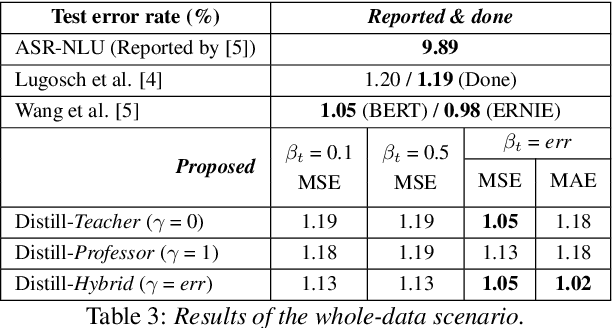
Speech is one of the most effective means of communication and is full of information that helps the transmission of utterer's thoughts. However, mainly due to the cumbersome processing of acoustic features, phoneme or word posterior probability has frequently been discarded in understanding the natural language. Thus, some recent spoken language understanding (SLU) modules have utilized an end-to-end structure that preserves the uncertainty information. This further reduces the propagation of speech recognition error and guarantees computational efficiency. We claim that in this process, the speech comprehension can benefit from the inference of massive pre-trained language models (LMs). We transfer the knowledge from a concrete Transformer-based text LM to an SLU module which can face a data shortage, based on recent cross-modal distillation methodologies. We demonstrate the validity of our proposal upon the performance on the Fluent Speech Command dataset. Thereby, we experimentally verify our hypothesis that the knowledge could be shared from the top layer of the LM to a fully speech-based module, in which the abstracted speech is expected to meet the semantic representation.
Machines Getting with the Program: Understanding Intent Arguments of Non-Canonical Directives
Dec 01, 2019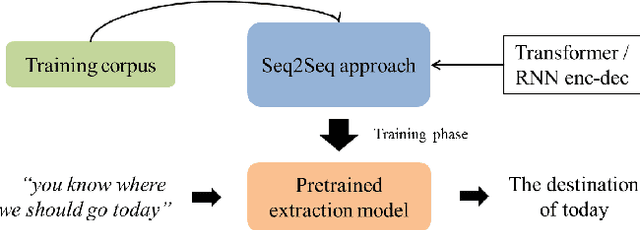
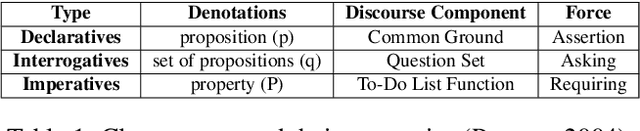
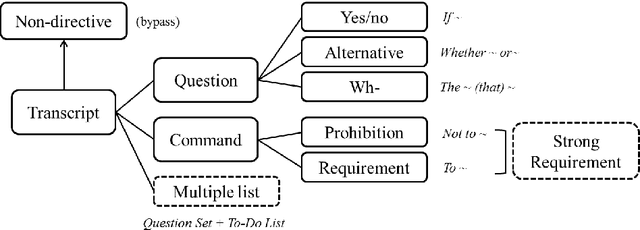
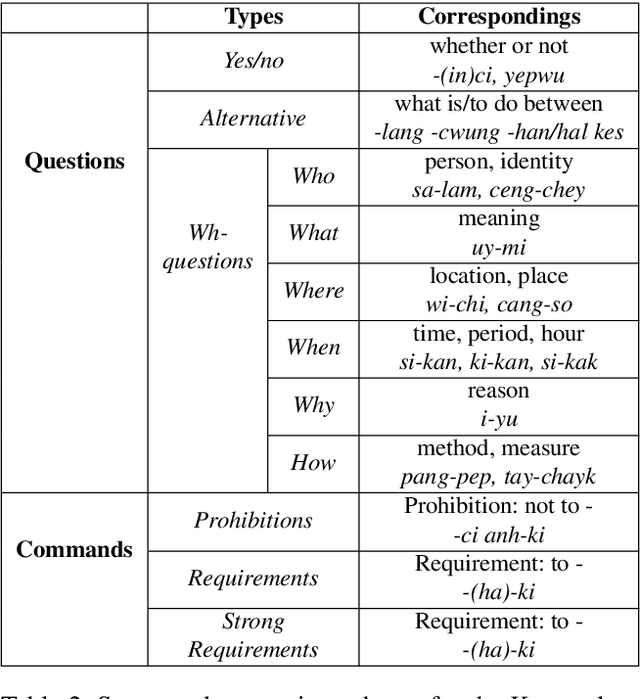
Modern dialog managers face the challenge of having to fulfill human-level conversational skills as part of common user expectations, including but not limited to discourse with no clear objective. Along with these requirements, agents are expected to extrapolate intent from the user's dialogue even when subjected to non-canonical forms of speech. This depends on the agent's comprehension of paraphrased forms of such utterances. In low-resource languages, the lack of data is a bottleneck that prevents advancements of the comprehension performance for these types of agents. In this paper, we demonstrate the necessity of being able to extract the intent argument of non-canonical directives, and also define guidelines for building paired corpora for this purpose. Following the guidelines, we label a dataset consisting of 30K instances of question/command-intent pairs, including annotations for a classification task for predicting the utterance type. We also propose a method for mitigating class imbalance in the final dataset, and demonstrate the potential applications of the corpus generation method and dataset.
Disambiguating Speech Intention via Audio-Text Co-attention Framework: A Case of Prosody-semantics Interface
Oct 21, 2019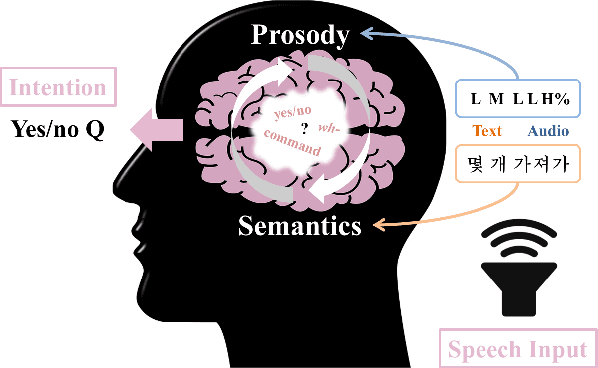
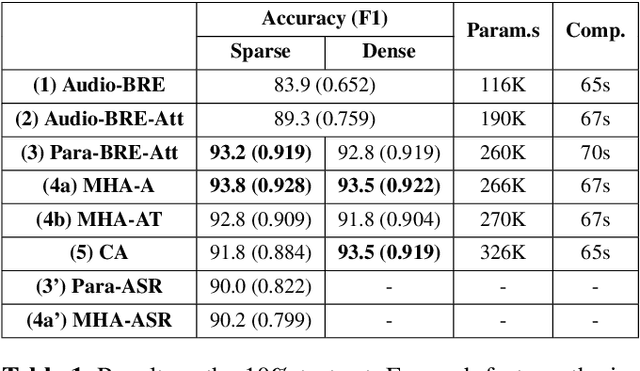
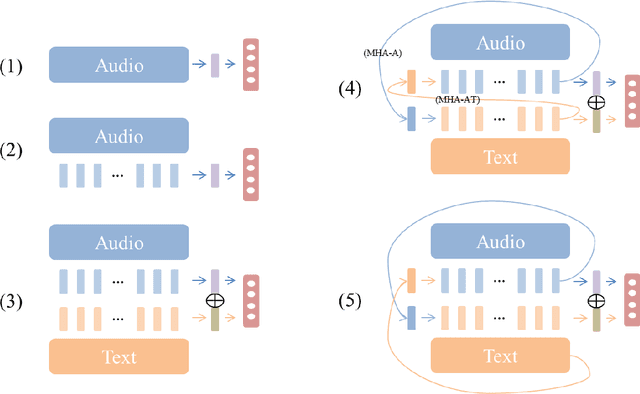
Understanding the intention of an utterance is challenging for some prosody-sensitive cases, especially when it is in the written form. The main concern is to detect the directivity or rhetoricalness of an utterance and to distinguish the type of question. Since it is inevitable to face both the issues regarding prosody and semantics, the identification is expected to benefit from the observations of human language processing mechanism. In this paper, we combat the task with attentive recurrent neural networks that exploit acoustic and textual features, using a manually created speech corpus that incorporates only the syntactically ambiguous utterances which require prosody for disambiguation. We found out that co-attention frameworks on audio-text data, namely multi-hop attention and cross-attention, can perform better than previously suggested speech-based/text-aided networks. By this, we infer that understanding the genuine intention of the ambiguous utterances incorporates recognizing the interaction between auditory and linguistic processes.
Investigating an Effective Character-level Embedding in Korean Sentence Classification
May 31, 2019
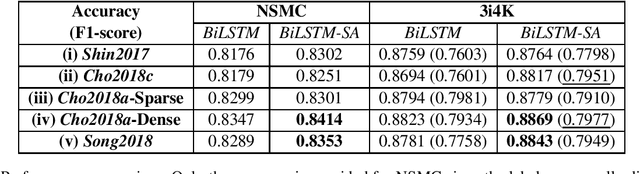
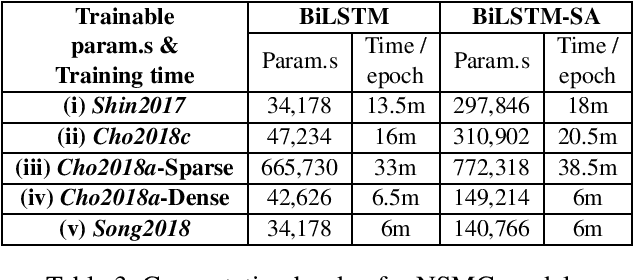
Different from the writing systems of many Romance and Germanic languages, some languages or language families show complex conjunct forms in character composition. For such cases where the conjuncts consist of the components representing consonant(s) and vowel, various character encoding schemes can be adopted beyond merely making up a one-hot vector. However, there has been little work done on intra-language comparison regarding performances using each representation. In this study, utilizing the Korean language which is character-rich and agglutinative, we investigate an encoding scheme that is the most effective among Jamo-level one-hot, character-level one-hot, character-level dense, and character-level multi-hot. Classification performance with each scheme is evaluated on two corpora: one on binary sentiment analysis of movie reviews, and the other on multi-class identification of intention types. The result displays that the character-level features show higher performance in general, although the Jamo-level features may show compatibility with the attention-based models if guaranteed adequate parameter size.
On Measuring Gender Bias in Translation of Gender-neutral Pronouns
May 28, 2019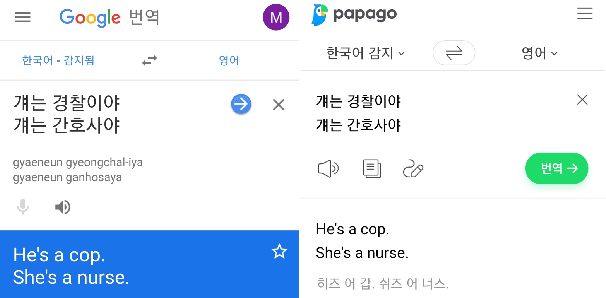
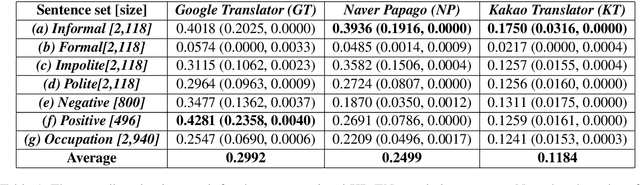
Ethics regarding social bias has recently thrown striking issues in natural language processing. Especially for gender-related topics, the need for a system that reduces the model bias has grown in areas such as image captioning, content recommendation, and automated employment. However, detection and evaluation of gender bias in the machine translation systems are not yet thoroughly investigated, for the task being cross-lingual and challenging to define. In this paper, we propose a scheme for making up a test set that evaluates the gender bias in a machine translation system, with Korean, a language with gender-neutral pronouns. Three word/phrase sets are primarily constructed, each incorporating positive/negative expressions or occupations; all the terms are gender-independent or at least not biased to one side severely. Then, additional sentence lists are constructed concerning formality of the pronouns and politeness of the sentences. With the generated sentence set of size 4,236 in total, we evaluate gender bias in conventional machine translation systems utilizing the proposed measure, which is termed here as translation gender bias index (TGBI). The corpus and the code for evaluation is available on-line.
Speech Intention Understanding in a Head-final Language: A Disambiguation Utilizing Intonation-dependency
Nov 10, 2018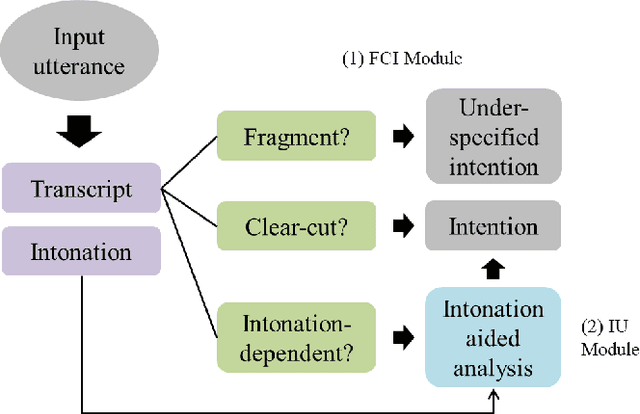
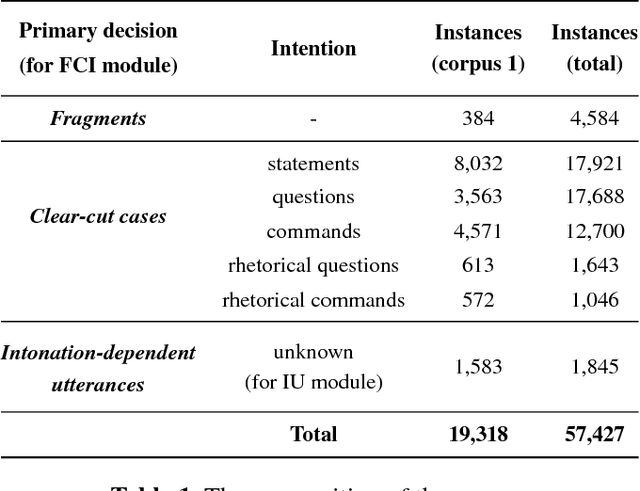
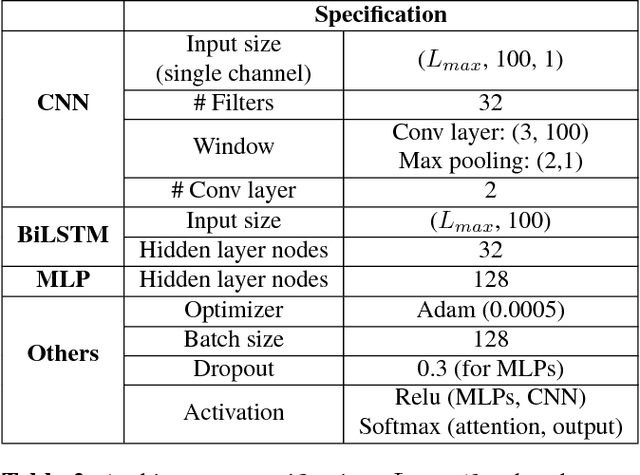
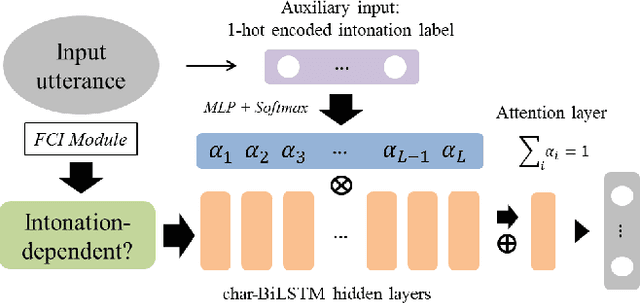
For a large portion of real-life utterances, the intention cannot be solely decided by either their semantics or syntax. Although all the socio-linguistic and pragmatic information cannot be digitized, at least phonetic features are indispensable in understanding the spoken language. Especially in head-final languages such as Korean, sentence-final intonation has great importance in identifying the speaker's intention. This paper suggests a system which identifies the intention of an utterance, given its acoustic feature and text. The proposed multi-stage classification system decides whether given utterance is a fragment, statement, question, command, or a rhetorical one, utilizing the intonation-dependency coming from head-finality. Based on an intuitive understanding of Korean language which is engaged in data annotation, we construct a network identifying the intention of a speech and validate its utility with sample sentences. The system, if combined with the speech recognizers, is expected to be flexibly inserted into various language understanding modules.
Real-time Automatic Word Segmentation for User-generated Text
Oct 31, 2018
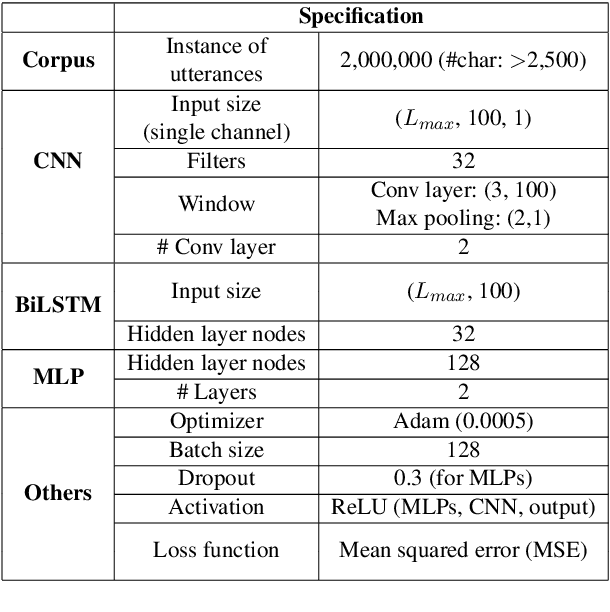
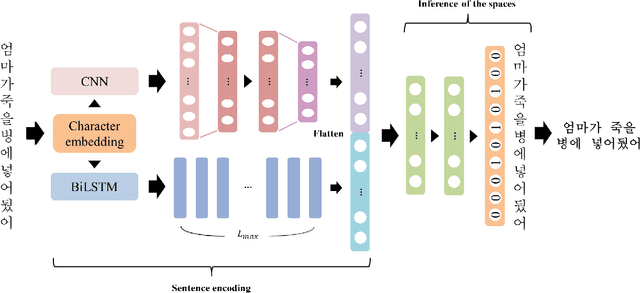
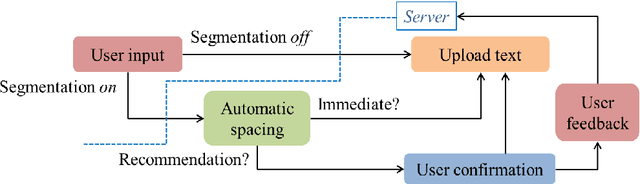
For readability and possibly for disambiguation, appropriate word segmentation is recommended for written text. In this paper, we propose a real-time assistive technology that utilizes an automatic segmentation. The language primarily investigated is Korean, a head-final language with the various morpho-syllabic blocks as a character set. The training scheme is fully neural network-based and extensible to other languages, as is implemented in this study for English. Besides, we show how the proposed system can be utilized in a web-based fine-tuning for a user-generated text. With a qualitative and quantitative comparison with widely used text processing toolkits, we show the reliability of the proposed system and how it fits with conversation-style and non-canonical texts. Demonstration for both languages is freely available online.