 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Detection to Recovery: Operational Analysis on LLM Pre-training with 504 GPUs
May 10, 2026Large-scale AI training is now fundamentally a distributed systems problem, and hardware failures have become routine operating conditions rather than rare exceptions. Public operational evidence from production training clusters, however, remains scarce. This technical report presents an empirical analysis of a 63-node NVIDIA B200 production cluster (504 GPUs), using 55 days of Prometheus time-series data and 73 days of operational logs covering 224 multi-node training sessions. The cluster operates within a cross-organizational environment in which five parties (SKT, Upstage, Lablup, NVIDIA Korea, and VAST Data) share a unified monitoring pipeline. This arrangement enabled joint diagnosis of a 60-node-scale storage I/O bottleneck that did not appear at 2-4-node scale, a production-scale phenomenon no single team could isolate alone. Drawing on a months-long pre-training campaign, we perform three quantitative analyses yielding four findings. First, statistical analysis over 751 Prometheus metrics and 10 XID-identified GPU failures achieves a 10/10 detection rate (2/10 pre-XID) at ~0.84 false positives per day. No single metric is consistently dominant across failure types, motivating a multi-signal detection strategy. Second, profiling 523 checkpoint events along the GPU VRAM to NFS path attributes the "bandwidth paradox" (1.4-10.4% utilization of 200 Gbps RoCE) to saturation of the 128-slot NFS RPC layer. Third, multi-node failure response shows concentrated exclusions (top 3 of 63 nodes account for >50% of all exclusions) and an auto-retry chain success rate of 33.3% over 12 chains (73 attempts), 2.7x the 12.5% manual recovery rate; the median retry interval is 11 min (IQR 10-11). All analyses are grounded in production infrastructure providing session-level workload management, GPU-centric scheduling, and unified observability.
KoGEC : Korean Grammatical Error Correction with Pre-trained Translation Models
Jun 13, 2025This research introduces KoGEC, a Korean Grammatical Error Correction system using pre\--trained translation models. We fine-tuned NLLB (No Language Left Behind) models for Korean GEC, comparing their performance against large language models like GPT-4 and HCX-3. The study used two social media conversation datasets for training and testing. The NLLB models were fine-tuned using special language tokens to distinguish between original and corrected Korean sentences. Evaluation was done using BLEU scores and an "LLM as judge" method to classify error types. Results showed that the fine-tuned NLLB (KoGEC) models outperformed GPT-4o and HCX-3 in Korean GEC tasks. KoGEC demonstrated a more balanced error correction profile across various error types, whereas the larger LLMs tended to focus less on punctuation errors. We also developed a Chrome extension to make the KoGEC system accessible to users. Finally, we explored token vocabulary expansion to further improve the model but found it to decrease model performance. This research contributes to the field of NLP by providing an efficient, specialized Korean GEC system and a new evaluation method. It also highlights the potential of compact, task-specific models to compete with larger, general-purpose language models in specialized NLP tasks.
* 11 pages, 2 figures
Stop learning it all to mitigate visual hallucination, Focus on the hallucination target
Jun 13, 2025



Multimodal Large Language Models (MLLMs) frequently suffer from hallucination issues, generating information about objects that are not present in input images during vision-language tasks. These hallucinations particularly undermine model reliability in practical applications requiring accurate object identification. To address this challenge, we propose \mymethod,\ a preference learning approach that mitigates hallucinations by focusing on targeted areas where they occur. To implement this, we build a dataset containing hallucinated responses, correct responses, and target information (i.e., objects present in the images and the corresponding chunk positions in responses affected by hallucinations). By applying a preference learning method restricted to these specific targets, the model can filter out irrelevant signals and focus on correcting hallucinations. This allows the model to produce more factual responses by concentrating solely on relevant information. Experimental results demonstrate that \mymethod\ effectively reduces hallucinations across multiple vision hallucination tasks, improving the reliability and performance of MLLMs without diminishing overall performance.
* Accepted to CVPR 2025
Better Safe Than Sorry? Overreaction Problem of Vision Language Models in Visual Emergency Recognition
May 21, 2025



Vision-Language Models (VLMs) have demonstrated impressive capabilities in understanding visual content, but their reliability in safety-critical contexts remains under-explored. We introduce VERI (Visual Emergency Recognition Dataset), a carefully designed diagnostic benchmark of 200 images (100 contrastive pairs). Each emergency scene is matched with a visually similar but safe counterpart through multi-stage human verification and iterative refinement. Using a two-stage protocol - risk identification and emergency response - we evaluate 14 VLMs (2B-124B parameters) across medical emergencies, accidents, and natural disasters. Our analysis reveals a systematic overreaction problem: models excel at identifying real emergencies (70-100 percent success rate) but suffer from an alarming rate of false alarms, misidentifying 31-96 percent of safe situations as dangerous, with 10 scenarios failed by all models regardless of scale. This "better-safe-than-sorry" bias manifests primarily through contextual overinterpretation (88-93 percent of errors), challenging VLMs' reliability for safety applications. These findings highlight persistent limitations that are not resolved by increasing model scale, motivating targeted approaches for improving contextual safety assessment in visually misleading scenarios.
Open Korean Corpora: A Practical Report
Dec 31, 2020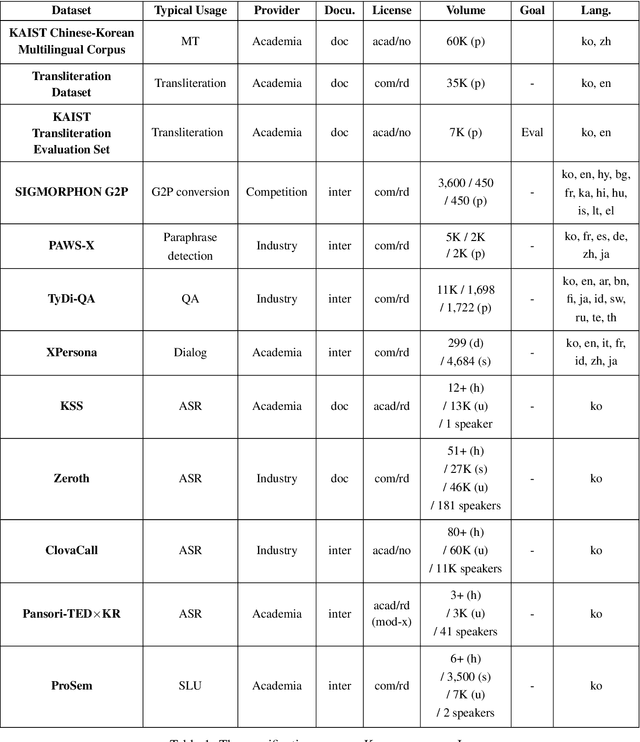
Korean is often referred to as a low-resource language in the research community. While this claim is partially true, it is also because the availability of resources is inadequately advertised and curated. This work curates and reviews a list of Korean corpora, first describing institution-level resource development, then further iterate through a list of current open datasets for different types of tasks. We then propose a direction on how open-source dataset construction and releases should be done for less-resourced languages to promote research.