 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntraSeismic: a coordinate-based learning approach to seismic inversion
Dec 17, 2023



Seismic imaging is the numerical process of creating a volumetric representation of the subsurface geological structures from elastic waves recorded at the surface of the Earth. As such, it is widely utilized in the energy and construction sectors for applications ranging from oil and gas prospection, to geothermal production and carbon capture and storage monitoring, to geotechnical assessment of infrastructures. Extracting quantitative information from seismic recordings, such as an acoustic impedance model, is however a highly ill-posed inverse problem, due to the band-limited and noisy nature of the data. This paper introduces IntraSeismic, a novel hybrid seismic inversion method that seamlessly combines coordinate-based learning with the physics of the post-stack modeling operator. Key features of IntraSeismic are i) unparalleled performance in 2D and 3D post-stack seismic inversion, ii) rapid convergence rates, iii) ability to seamlessly include hard constraints (i.e., well data) and perform uncertainty quantification, and iv) potential data compression and fast randomized access to portions of the inverted model. Synthetic and field data applications of IntraSeismic are presented to validate the effectiveness of the proposed method.
QR-Tag: Angular Measurement and Tracking with a QR-Design Marker
Oct 09, 2023



Directional information measurement has many applications in domains such as robotics, virtual and augmented reality, and industrial computer vision. Conventional methods either require pre-calibration or necessitate controlled environments. The state-of-the-art MoireTag approach exploits the Moire effect and QR-design to continuously track the angular shift precisely. However, it is still not a fully QR code design. To overcome the above challenges, we propose a novel snapshot method for discrete angular measurement and tracking with scannable QR-design patterns that are generated by binary structures printed on both sides of a glass plate. The QR codes, resulting from the parallax effect due to the geometry alignment between two layers, can be readily measured as angular information using a phone camera. The simulation results show that the proposed non-contact object tracking framework is computationally efficient with high accuracy.
Image Quality Is Not All You Want: Task-Driven Lens Design for Image Classification
May 26, 2023



In computer vision, it has long been taken for granted that high-quality images obtained through well-designed camera lenses would lead to superior results. However, we find that this common perception is not a "one-size-fits-all" solution for diverse computer vision tasks. We demonstrate that task-driven and deep-learned simple optics can actually deliver better visual task performance. The Task-Driven lens design approach, which relies solely on a well-trained network model for supervision, is proven to be capable of designing lenses from scratch. Experimental results demonstrate the designed image classification lens (``TaskLens'') exhibits higher accuracy compared to conventional imaging-driven lenses, even with fewer lens elements. Furthermore, we show that our TaskLens is compatible with various network models while maintaining enhanced classification accuracy. We propose that TaskLens holds significant potential, particularly when physical dimensions and cost are severely constrained.
Aberration-Aware Depth-from-Focus
Mar 08, 2023



Computer vision methods for depth estimation usually use simple camera models with idealized optics. For modern machine learning approaches, this creates an issue when attempting to train deep networks with simulated data, especially for focus-sensitive tasks like Depth-from-Focus. In this work, we investigate the domain gap caused by off-axis aberrations that will affect the decision of the best-focused frame in a focal stack. We then explore bridging this domain gap through aberration-aware training (AAT). Our approach involves a lightweight network that models lens aberrations at different positions and focus distances, which is then integrated into the conventional network training pipeline. We evaluate the generality of pretrained models on both synthetic and real-world data. Our experimental results demonstrate that the proposed AAT scheme can improve depth estimation accuracy without fine-tuning the model or modifying the network architecture.
Curriculum Learning for ab initio Deep Learned Refractive Optics
Feb 09, 2023Deep lens optimization has recently emerged as a new paradigm for designing computational imaging systems, however it has been limited to either simple optical systems consisting of a single DOE or metalens, or the fine-tuning of compound lenses from good initial designs. Here we present a deep lens design method based on curriculum learning, which is able to learn optical designs of compound lenses ab initio from randomly initialized surfaces, therefore overcoming the need for a good initial design. We demonstrate this approach with the fully-automatic design of an extended depth-of-field computational camera in a cellphone-style form factor, highly aspherical surfaces, and a short back focal length.
CRISPnet: Color Rendition ISP Net
Mar 22, 2022
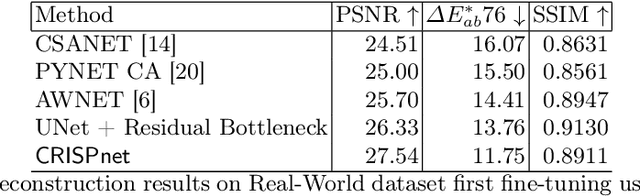
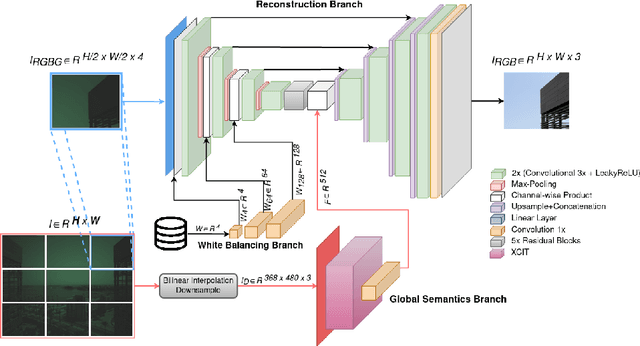
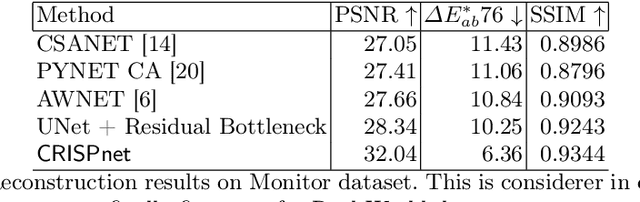
Image signal processors (ISPs) are historically grown legacy software systems for reconstructing color images from noisy raw sensor measurements. They are usually composited of many heuristic blocks for denoising, demosaicking, and color restoration. Color reproduction in this context is of particular importance, since the raw colors are often severely distorted, and each smart phone manufacturer has developed their own characteristic heuristics for improving the color rendition, for example of skin tones and other visually important colors. In recent years there has been strong interest in replacing the historically grown ISP systems with deep learned pipelines. Much progress has been made in approximating legacy ISPs with such learned models. However, so far the focus of these efforts has been on reproducing the structural features of the images, with less attention paid to color rendition. Here we present CRISPnet, the first learned ISP model to specifically target color rendition accuracy relative to a complex, legacy smart phone ISP. We achieve this by utilizing both image metadata (like a legacy ISP would), as well as by learning simple global semantics based on image classification -- similar to what a legacy ISP does to determine the scene type. We also contribute a new ISP image dataset consisting of both high dynamic range monitor data, as well as real-world data, both captured with an actual cell phone ISP pipeline under a variety of lighting conditions, exposure times, and gain settings.
Neural Adaptive SCEne Tracing
Mar 16, 2022
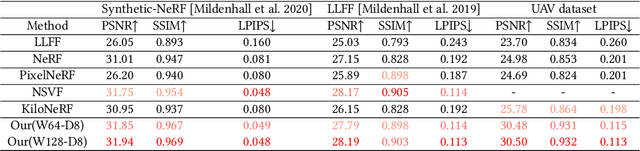
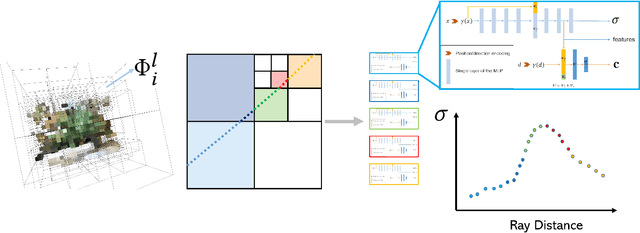
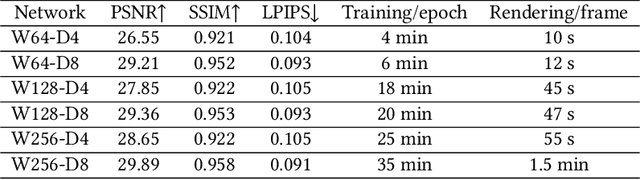
Neural rendering with implicit neural networks has recently emerged as an attractive proposition for scene reconstruction, achieving excellent quality albeit at high computational cost. While the most recent generation of such methods has made progress on the rendering (inference) times, very little progress has been made on improving the reconstruction (training) times. In this work, we present Neural Adaptive Scene Tracing (NAScenT), the first neural rendering method based on directly training a hybrid explicit-implicit neural representation. NAScenT uses a hierarchical octree representation with one neural network per leaf node and combines this representation with a two-stage sampling process that concentrates ray samples where they matter most near object surfaces. As a result, NAScenT is capable of reconstructing challenging scenes including both large, sparsely populated volumes like UAV captured outdoor environments, as well as small scenes with high geometric complexity. NAScenT outperforms existing neural rendering approaches in terms of both quality and training time.
NeAT: Neural Adaptive Tomography
Feb 04, 2022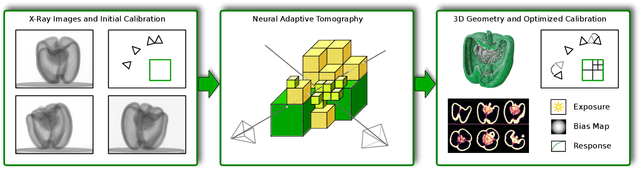
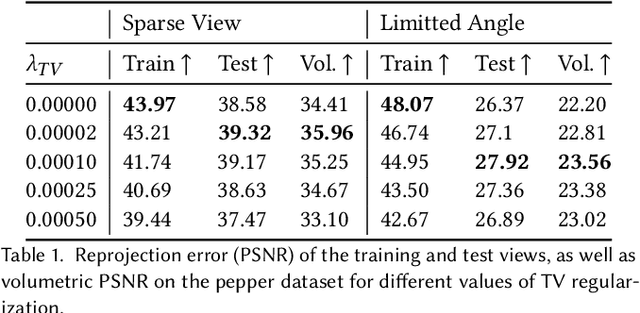

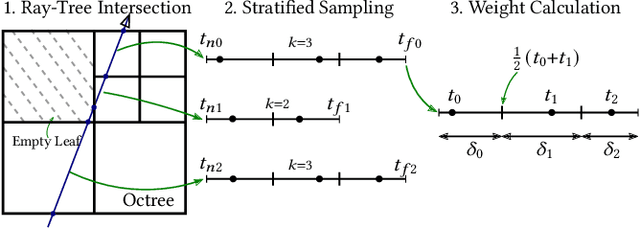
In this paper, we present Neural Adaptive Tomography (NeAT), the first adaptive, hierarchical neural rendering pipeline for multi-view inverse rendering. Through a combination of neural features with an adaptive explicit representation, we achieve reconstruction times far superior to existing neural inverse rendering methods. The adaptive explicit representation improves efficiency by facilitating empty space culling and concentrating samples in complex regions, while the neural features act as a neural regularizer for the 3D reconstruction. The NeAT framework is designed specifically for the tomographic setting, which consists only of semi-transparent volumetric scenes instead of opaque objects. In this setting, NeAT outperforms the quality of existing optimization-based tomography solvers while being substantially faster.
Snapshot HDR Video Construction Using Coded Mask
Dec 05, 2021
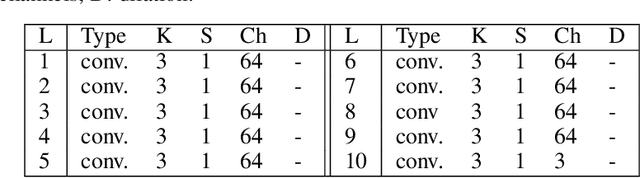
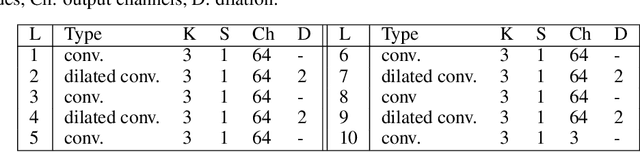
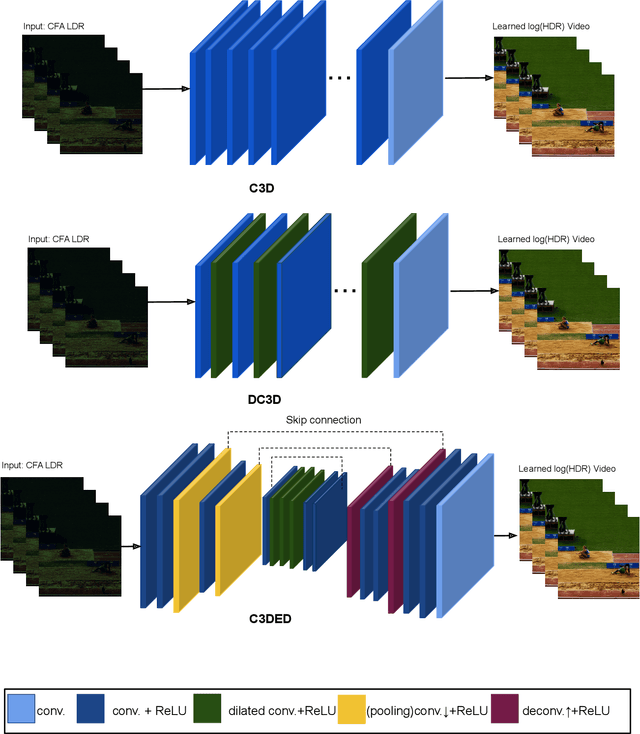
This paper study the reconstruction of High Dynamic Range (HDR) video from snapshot-coded LDR video. Constructing an HDR video requires restoring the HDR values for each frame and maintaining the consistency between successive frames. HDR image acquisition from single image capture, also known as snapshot HDR imaging, can be achieved in several ways. For example, the reconfigurable snapshot HDR camera is realized by introducing an optical element into the optical stack of the camera; by placing a coded mask at a small standoff distance in front of the sensor. High-quality HDR image can be recovered from the captured coded image using deep learning methods. This study utilizes 3D-CNNs to perform a joint demosaicking, denoising, and HDR video reconstruction from coded LDR video. We enforce more temporally consistent HDR video reconstruction by introducing a temporal loss function that considers the short-term and long-term consistency. The obtained results are promising and could lead to affordable HDR video capture using conventional cameras.
ISP-Agnostic Image Reconstruction for Under-Display Cameras
Nov 02, 2021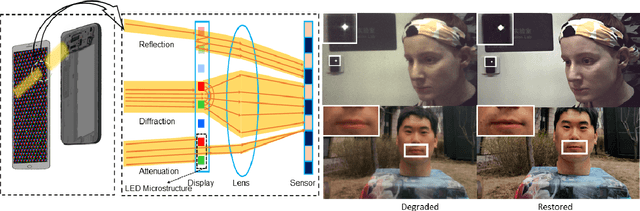

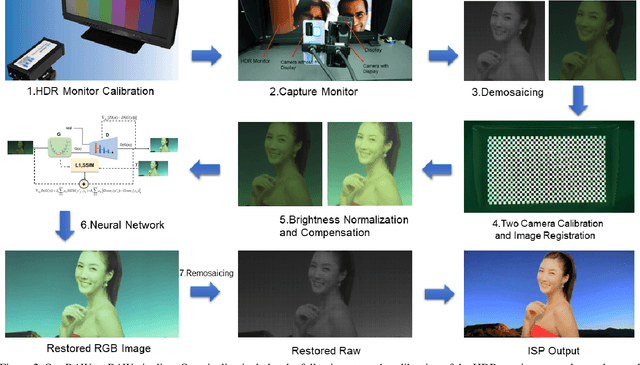
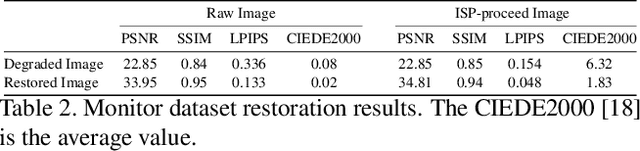
Under-display cameras have been proposed in recent years as a way to reduce the form factor of mobile devices while maximizing the screen area. Unfortunately, placing the camera behind the screen results in significant image distortions, including loss of contrast, blur, noise, color shift, scattering artifacts, and reduced light sensitivity. In this paper, we propose an image-restoration pipeline that is ISP-agnostic, i.e. it can be combined with any legacy ISP to produce a final image that matches the appearance of regular cameras using the same ISP. This is achieved with a deep learning approach that performs a RAW-to-RAW image restoration. To obtain large quantities of real under-display camera training data with sufficient contrast and scene diversity, we furthermore develop a data capture method utilizing an HDR monitor, as well as a data augmentation method to generate suitable HDR content. The monitor data is supplemented with real-world data that has less scene diversity but allows us to achieve fine detail recovery without being limited by the monitor resolution. Together, this approach successfully restores color and contrast as well as image detail.