 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti Layer Neural Networks as Replacement for Pooling Operations
Jun 12, 2020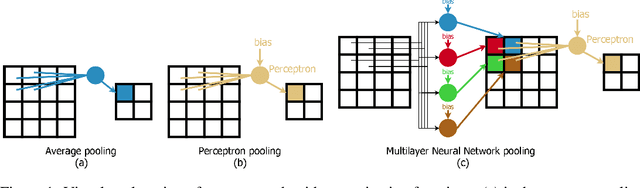
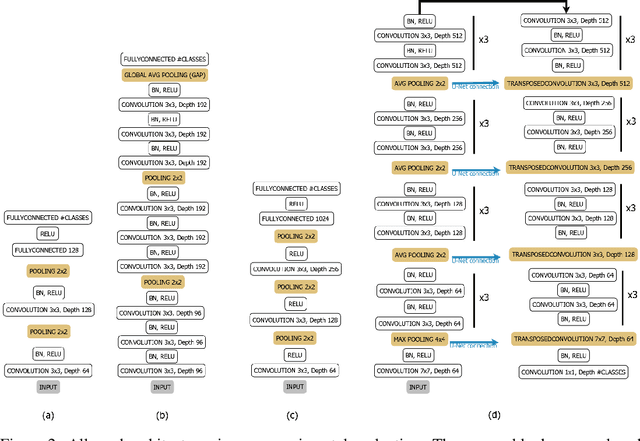
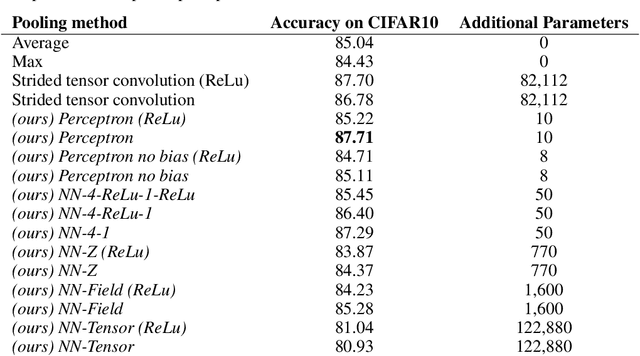

Pooling operations are a layer found in almost every modern neural network, which can be calculated at low cost and serves as a linear or nonlinear transfer function for data reduction. Many modern approaches have already dealt with replacing the common maximum value selection and mean value operations by others or even to provide a function that includes different functions which can be selected through changing parameters. Additional neural networks are used to estimate the parameters of these pooling functions. Therefore, these pooling layers need many additional parameters and increase the complexity of the whole model. In this work, we show that already one perceptron can be used very effectively as a pooling operation without increasing the complexity of the model. This kind of pooling allows to integrate multi-layer neural networks directly into a model as a pooling operation by restructuring the data and thus learning complex pooling operations. We compare our approach to tensor convolution with strides as a pooling operation and show that our approach is effective and reduces complexity. The restructuring of the data in combination with multiple perceptrons allows also to use our approach for upscaling, which is used for transposed convolutions in semantic segmentation.
Differential Privacy for Eye Tracking with Temporal Correlations
Feb 20, 2020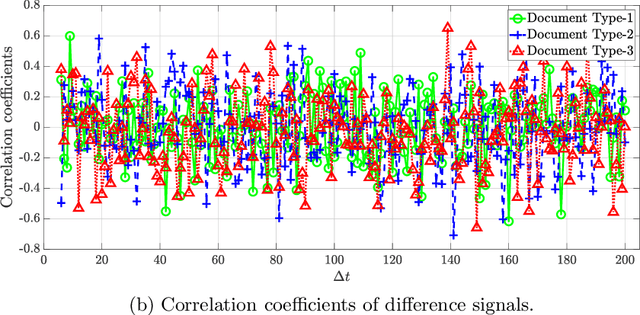
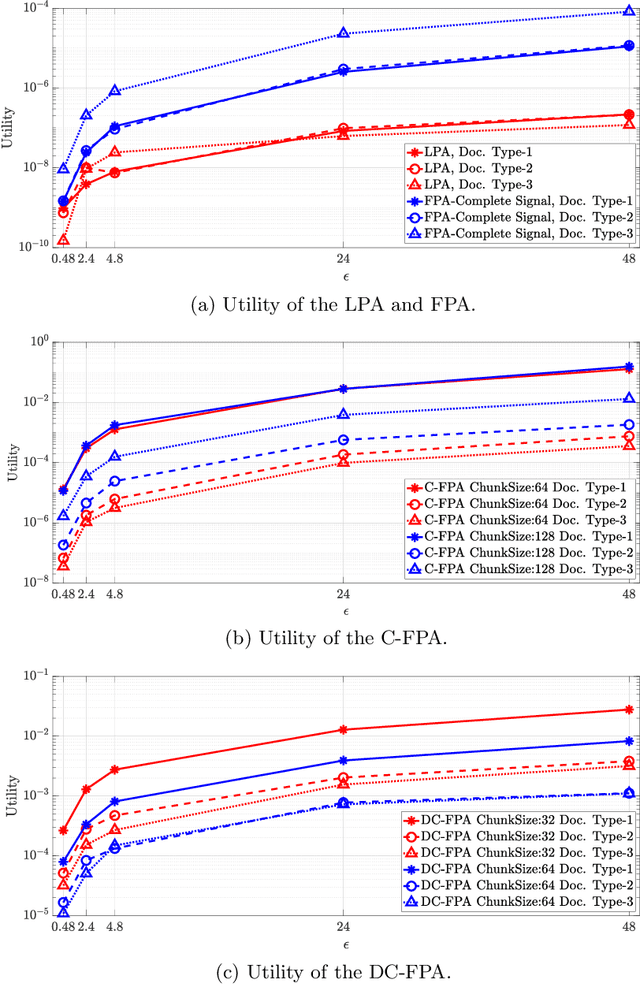
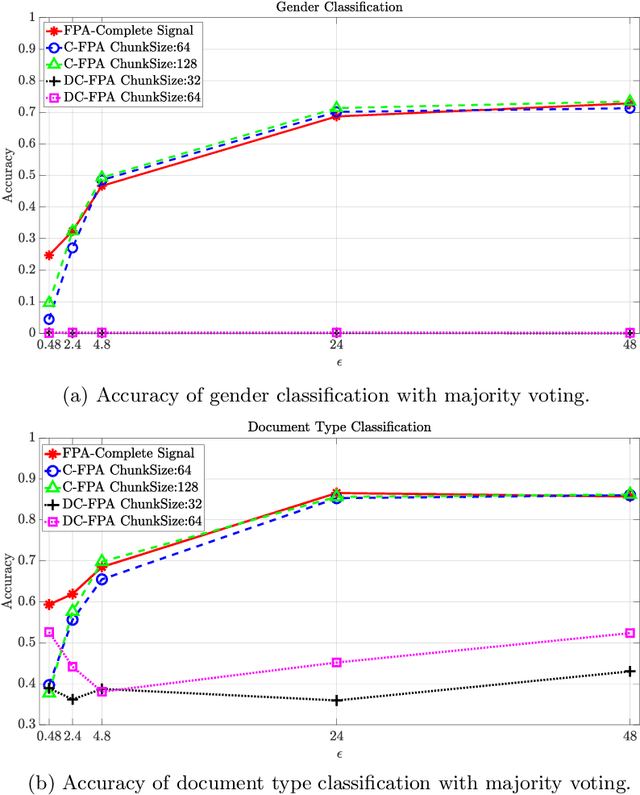
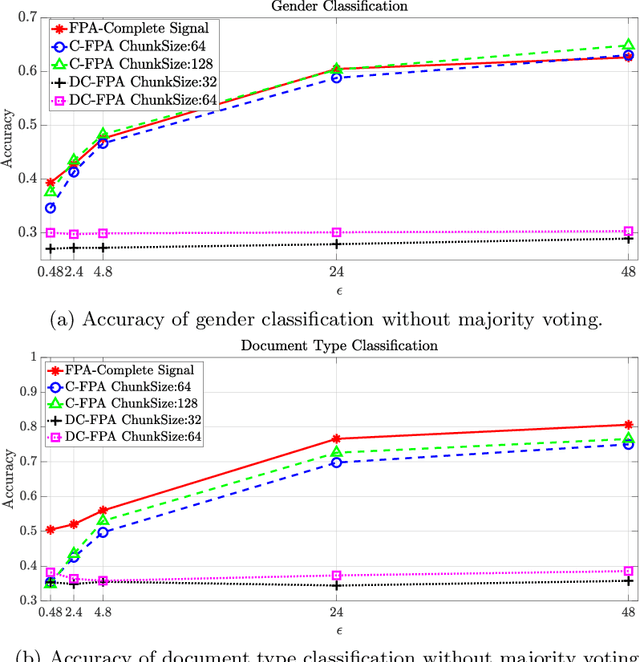
Head mounted displays bring eye tracking into daily use and this raises privacy concerns for users. Privacy-preservation techniques such as differential privacy mechanisms are recently applied to the eye tracking data obtained from such displays; however, standard differential privacy mechanisms are vulnerable to temporal correlations in the eye movement features. In this work, a transform coding based differential privacy mechanism is proposed for the first time in the eye tracking literature to further adapt it to statistics of eye movement feature data by comparing various low-complexity methods. Fourier Perturbation Algorithm, which is a differential privacy mechanism, is extended and a scaling mistake in its proof is corrected. Significant reductions in correlations in addition to query sensitivities are illustrated, which provide the best utility-privacy trade-off in the literature for the eye tracking dataset used. The differentially private eye movement data are evaluated also for classification accuracies for gender and document-type predictions to show that higher privacy is obtained without a reduction in the classification accuracies by using proposed methods.
Reinforcement learning for the manipulation of eye tracking data
Feb 17, 2020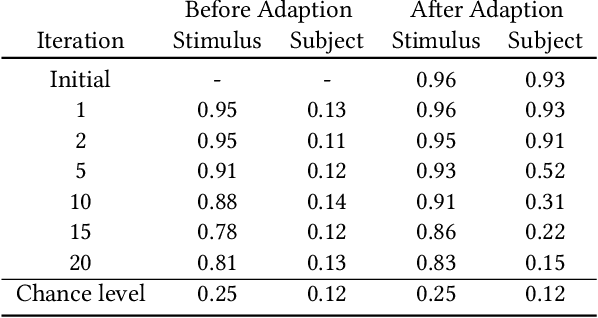
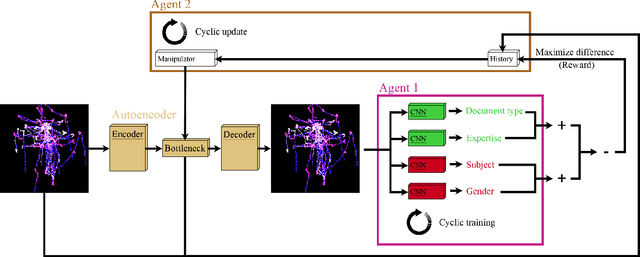
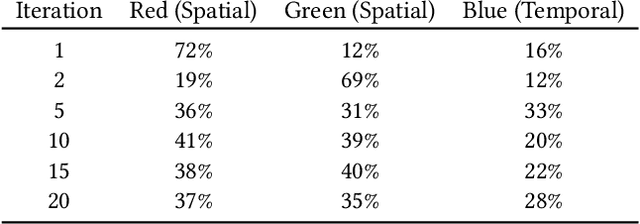

In this paper, we present an approach based on reinforcement learning for eye tracking data manipulation. It is based on two opposing agents, where one tries to classify the data correctly and the second agent looks for patterns in the data, which get manipulated to hide specific information. We show that our approach is successfully applicable to preserve the privacy of a subject. In addition, our approach allows to evaluate the importance of temporal, as well as spatial, information of eye tracking data for specific classification goals. In general, this approach can also be used for stimuli manipulation, making it interesting for gaze guidance. For this purpose, this work provides the theoretical basis, which is why we have also integrated a section on how to apply this method for gaze guidance.
Fully Convolutional Neural Networks for Raw Eye Tracking Data Segmentation, Generation, and Reconstruction
Feb 17, 2020
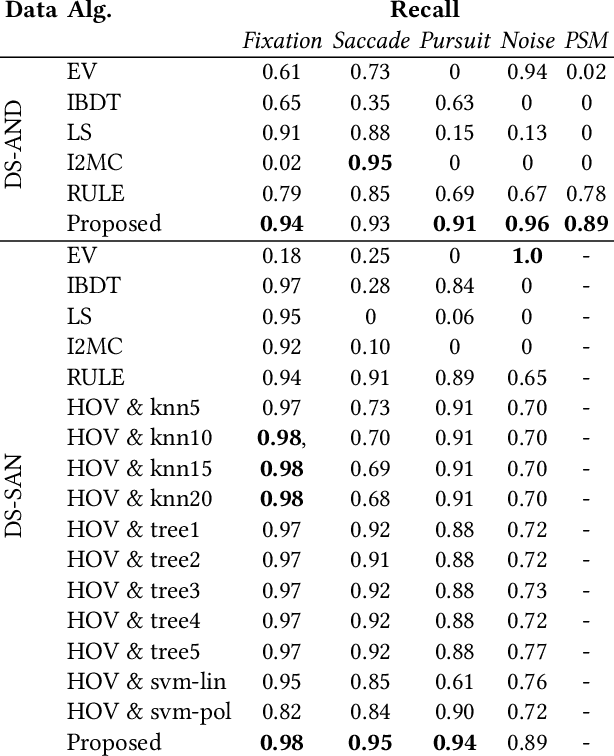
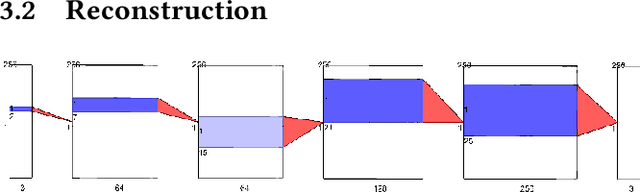
In this paper, we use fully convolutional neural networks for the semantic segmentation of eye tracking data. We also use these networks for reconstruction, and in conjunction with a variational auto-encoder to generate eye movement data. The first improvement of our approach is that no input window is necessary, due to the use of fully convolutional networks and therefore any input size can be processed directly. The second improvement is that the used and generated data is raw eye tracking data (position X, Y and time) without preprocessing. This is achieved by pre-initializing the filters in the first layer and by building the input tensor along the z axis. We evaluated our approach on three publicly available datasets and compare the results to the state of the art.
Training decision trees as replacement for convolution layers
Jun 05, 2019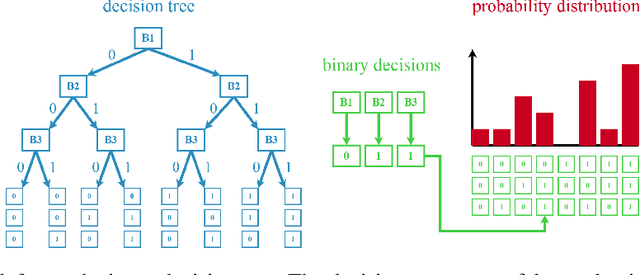

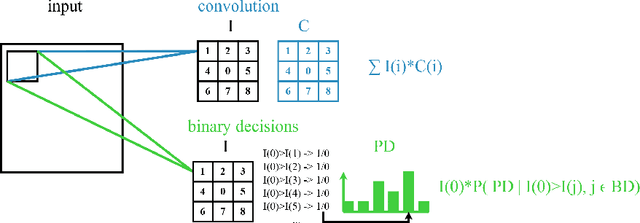

We present an alternative layer to convolution layers in convolutional neural networks (CNNs). Our approach reduces the complexity of convolutions by replacing it with binary decisions. Those binary decisions are used as indexes to conditional probability distributions where each probability represents a leaf in a decision tree. This means that only the indices to the probabilities need to be determined once, thus reducing the complexity of convolutions by the depth of the output tensor. Index computation is performed by simple binary decisions that require fewer CPU cycles compared to conventionally used multiplications. In addition, we show how convolutions can be replaced by binary decisions. These binary decisions form indices in the conditional probability distributions and we show how they are used to replace 2D weight matrices as well as 3D weight tensors. These new layers can be trained like convolution layers in CNNs based on the backpropagation algorithm, for which we provide a formalization. Our results on multiple publicly available data sets show that our approach outperforms conventional CNNs. Beyond the formalized reduction of complexity and the improved qualitative performance, we show empirically a significant runtime improvement compared to convolution layers. DOWNLOAD EXAMPLES: https://drive.google.com/open?id=1gqLD5N--tqVNCixenXiptcaR5hAP5IYJ
Validation loss for landmark detection
Jan 30, 2019


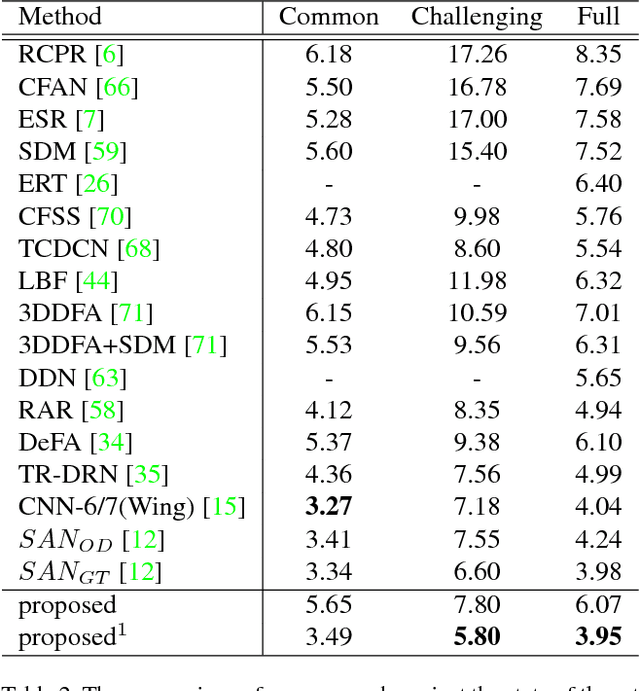
We present a new loss function for the validation of image landmarks detected via Convolutional Neural Networks (CNNs). The network learns to estimate how accurate its landmark estimation is. This loss function is applicable to all regression-based location estimations and allows exclusion of unreliable landmarks from further processing. In addition, we formulate a novel batch balancing approach which weights the importance of samples based on their produced loss. This is done by computing a probability distribution mapping on an interval from which samples can be selected using a uniform random selection scheme. We conducted several experiments on the 300W facial landmark data. In the first experiment, the influence of our batch balancing approach is evaluated by comparing it against uniform sampling. Afterwards, we compare two networks with the state of the art and demonstrate the usage and practical importance of our landmark validation signal. The effectiveness of our validation signal is further confirmed by a correlation analysis over all landmarks. Finally, we show a study on head pose estimation of truck drivers on German highways and compare our network to a commercial multi-camera system.
Eye movement simulation and detector creation to reduce laborious parameter adjustments
Mar 28, 2018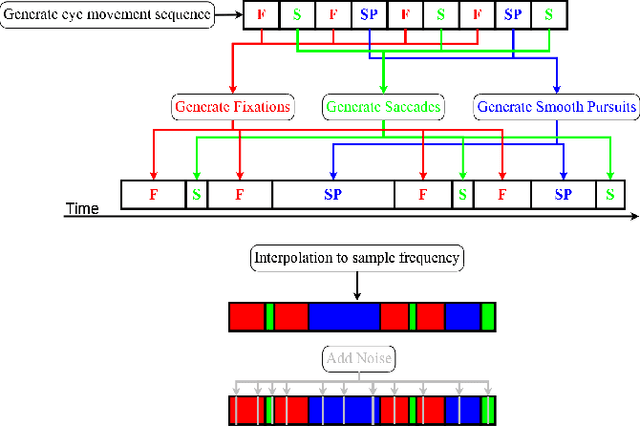
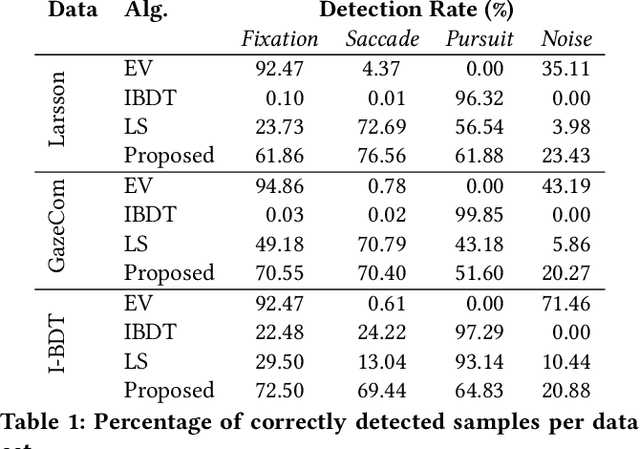
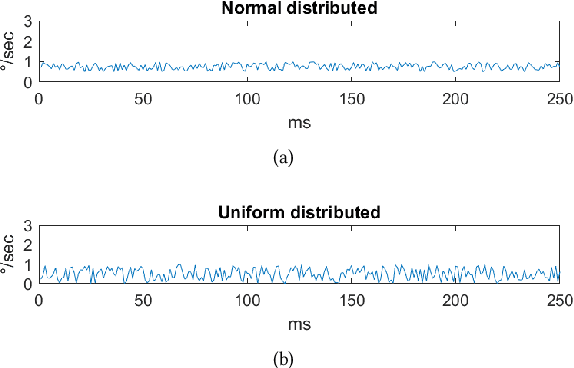
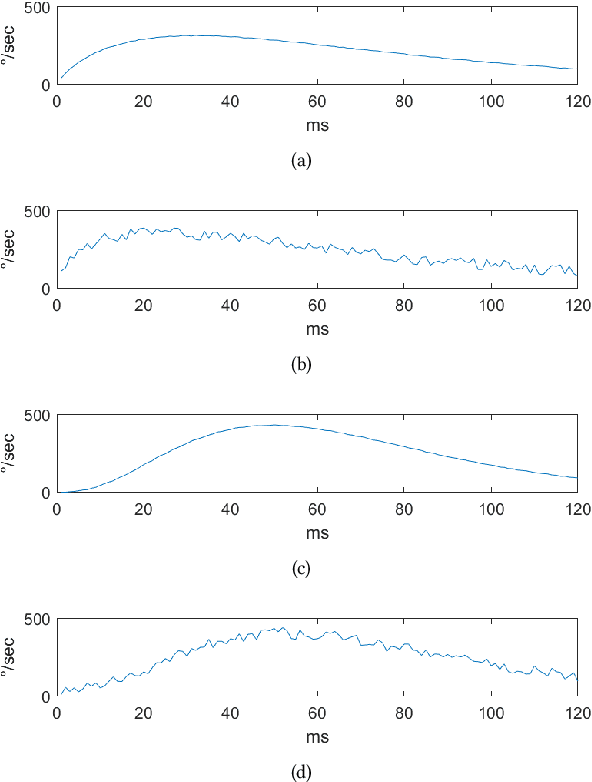
Eye movements hold information about human perception, intention and cognitive state. Various algorithms have been proposed to identify and distinguish eye movements, particularly fixations, saccades, and smooth pursuits. A major drawback of existing algorithms is that they rely on accurate and constant sampling rates, impeding straightforward adaptation to new movements such as micro saccades. We propose a novel eye movement simulator that i) probabilistically simulates saccade movements as gamma distributions considering different peak velocities and ii) models smooth pursuit onsets with the sigmoid function. This simulator is combined with a machine learning approach to create detectors for general and specific velocity profiles. Additionally, our approach is capable of using any sampling rate, even with fluctuations. The machine learning approach consists of different binary patterns combined using conditional distributions. The simulation is evaluated against publicly available real data using a squared error, and the detectors are evaluated against state-of-the-art algorithms.
PuRe: Robust pupil detection for real-time pervasive eye tracking
Dec 24, 2017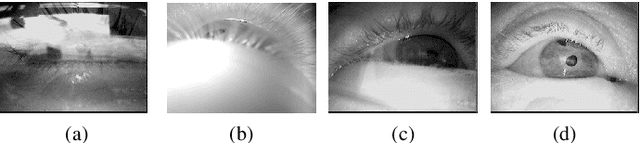

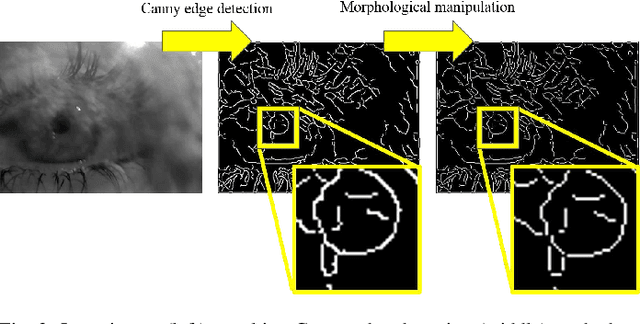
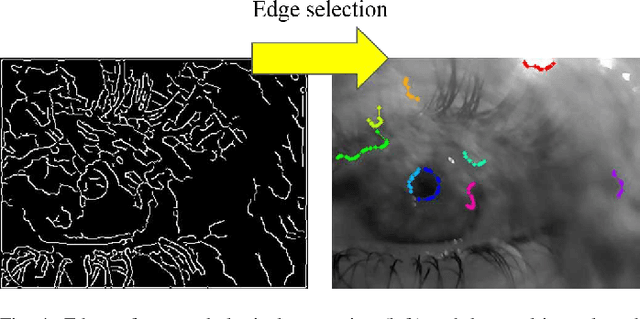
Real-time, accurate, and robust pupil detection is an essential prerequisite to enable pervasive eye-tracking and its applications -- e.g., gaze-based human computer interaction, health monitoring, foveated rendering, and advanced driver assistance. However, automated pupil detection has proved to be an intricate task in real-world scenarios due to a large mixture of challenges such as quickly changing illumination and occlusions. In this paper, we introduce the Pupil Reconstructor PuRe, a method for pupil detection in pervasive scenarios based on a novel edge segment selection and conditional segment combination schemes; the method also includes a confidence measure for the detected pupil. The proposed method was evaluated on over 316,000 images acquired with four distinct head-mounted eye tracking devices. Results show a pupil detection rate improvement of over 10 percentage points w.r.t. state-of-the-art algorithms in the two most challenging data sets (6.46 for all data sets), further pushing the envelope for pupil detection. Moreover, we advance the evaluation protocol of pupil detection algorithms by also considering eye images in which pupils are not present. In this aspect, PuRe improved precision and specificity w.r.t. state-of-the-art algorithms by 25.05 and 10.94 percentage points, respectively, demonstrating the meaningfulness of PuRe's confidence measure. PuRe operates in real-time for modern eye trackers (at 120 fps).
Fast camera focus estimation for gaze-based focus control
Nov 09, 2017


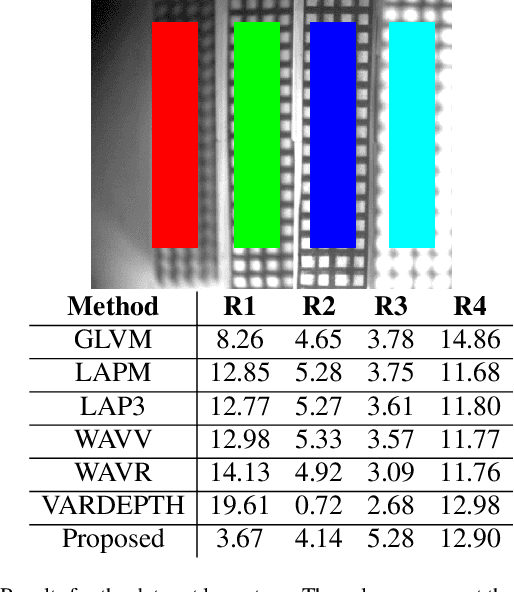
Many cameras implement auto-focus functionality. However, they typically require the user to manually identify the location to be focused on. While such an approach works for temporally-sparse autofocusing functionality (e.g., photo shooting), it presents extreme usability problems when the focus must be quickly switched between multiple areas (and depths) of interest - e.g., in a gaze-based autofocus approach. This work introduces a novel, real-time auto-focus approach based on eye-tracking, which enables the user to shift the camera focus plane swiftly based solely on the gaze information. Moreover, the proposed approach builds a graph representation of the image to estimate depth plane surfaces and runs in real time (requiring ~20ms on a single i5 core), thus allowing for the depth map estimation to be performed dynamically. We evaluated our algorithm for gaze-based depth estimation against state-of-the-art approaches based on eight new data sets with flat, skewed, and round surfaces, as well as publicly available datasets.
PupilNet v2.0: Convolutional Neural Networks for CPU based real time Robust Pupil Detection
Oct 30, 2017
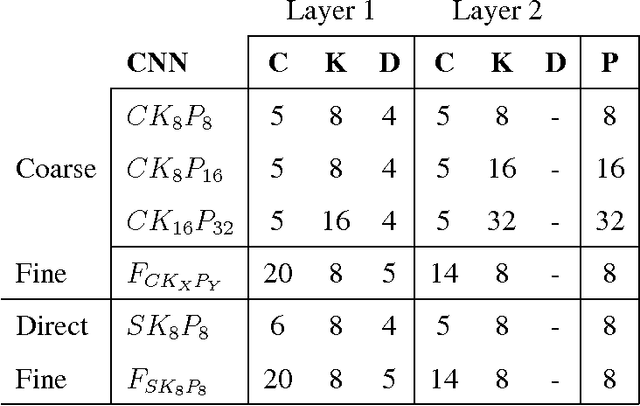
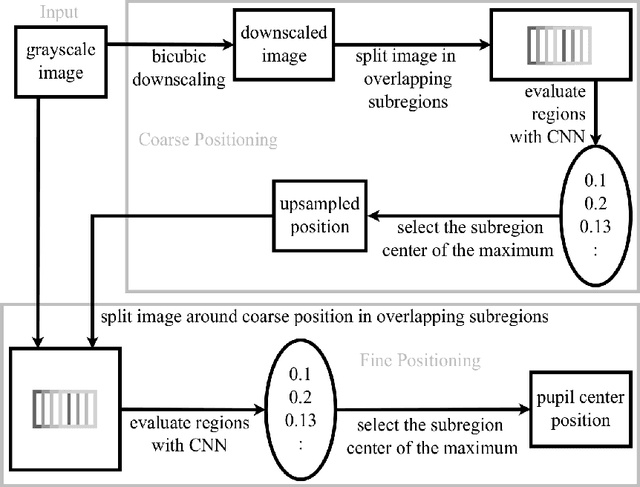
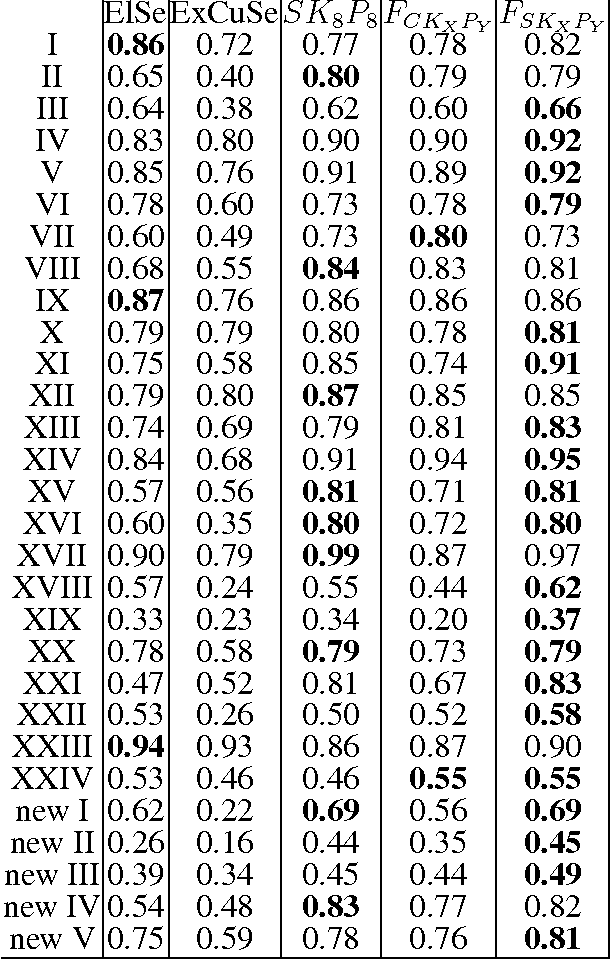
Real-time, accurate, and robust pupil detection is an essential prerequisite for pervasive video-based eye-tracking. However, automated pupil detection in realworld scenarios has proven to be an intricate challenge due to fast illumination changes, pupil occlusion, non-centered and off-axis eye recording, as well as physiological eye characteristics. In this paper, we approach this challenge through: I) a convolutional neural network (CNN) running in real time on a single core, II) a novel computational intensive two stage CNN for accuracy improvement, and III) a fast propability distribution based refinement method as a practical alternative to II. We evaluate the proposed approaches against the state-of-the-art pupil detection algorithms, improving the detection rate up to ~9% percent points on average over all data sets (~7% on one CPU core 7ms). This evaluation was performed on over 135,000 images: 94,000 images from the literature, and 41,000 new hand-labeled and challenging images contributed by this work (v1.0).