 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Neural Network Regularization
Feb 19, 2015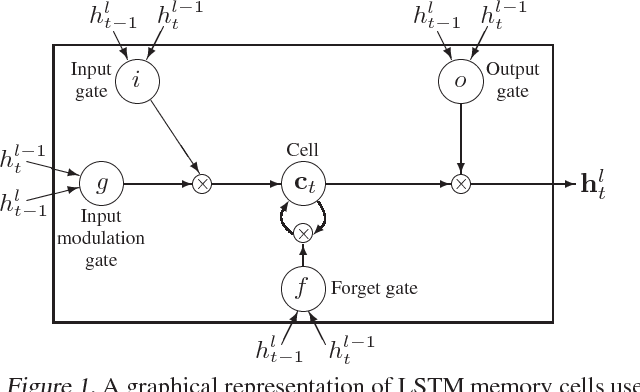
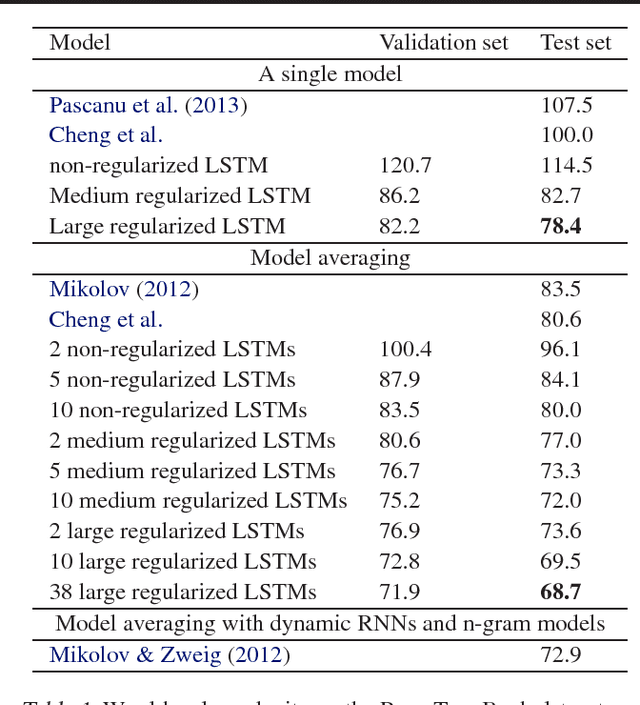
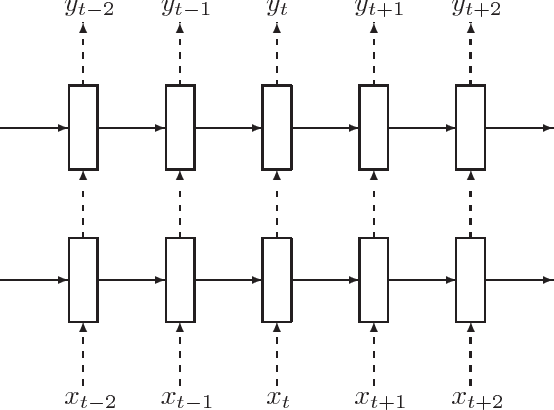
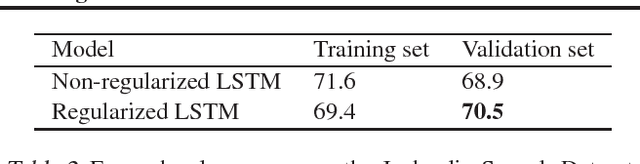
We present a simple regularization technique for Recurrent Neural Networks (RNNs) with Long Short-Term Memory (LSTM) units. Dropout, the most successful technique for regularizing neural networks, does not work well with RNNs and LSTMs. In this paper, we show how to correctly apply dropout to LSTMs, and show that it substantially reduces overfitting on a variety of tasks. These tasks include language modeling, speech recognition, image caption generation, and machine translation.
Learning to Discover Efficient Mathematical Identities
Nov 06, 2014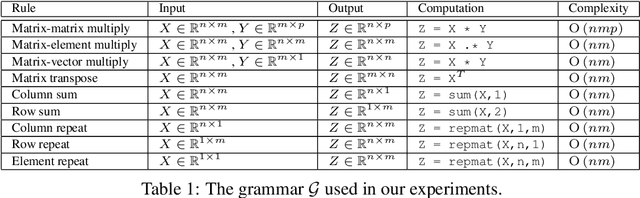

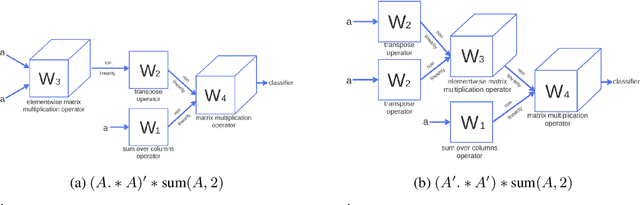
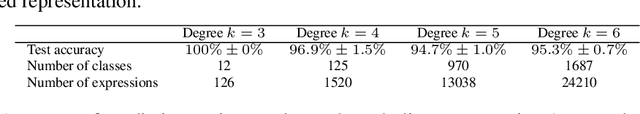
In this paper we explore how machine learning techniques can be applied to the discovery of efficient mathematical identities. We introduce an attribute grammar framework for representing symbolic expressions. Given a set of grammar rules we build trees that combine different rules, looking for branches which yield compositions that are analytically equivalent to a target expression, but of lower computational complexity. However, as the size of the trees grows exponentially with the complexity of the target expression, brute force search is impractical for all but the simplest of expressions. Consequently, we introduce two novel learning approaches that are able to learn from simpler expressions to guide the tree search. The first of these is a simple n-gram model, the other being a recursive neural-network. We show how these approaches enable us to derive complex identities, beyond reach of brute-force search, or human derivation.
Exploiting Linear Structure Within Convolutional Networks for Efficient Evaluation
Jun 09, 2014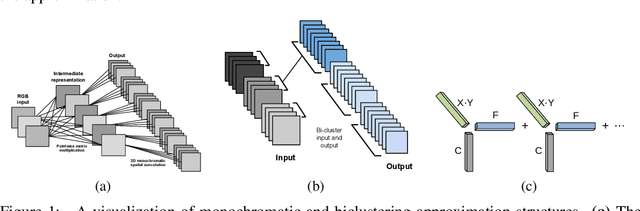

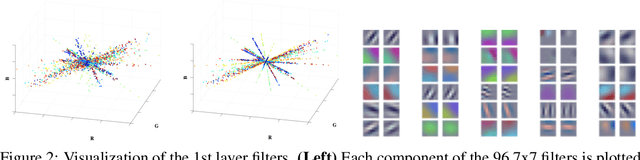
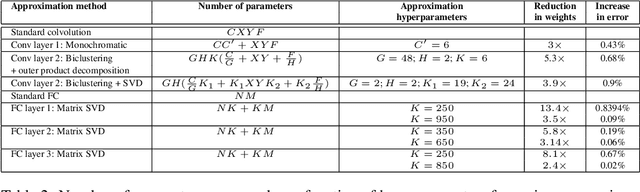
We present techniques for speeding up the test-time evaluation of large convolutional networks, designed for object recognition tasks. These models deliver impressive accuracy but each image evaluation requires millions of floating point operations, making their deployment on smartphones and Internet-scale clusters problematic. The computation is dominated by the convolution operations in the lower layers of the model. We exploit the linear structure present within the convolutional filters to derive approximations that significantly reduce the required computation. Using large state-of-the-art models, we demonstrate we demonstrate speedups of convolutional layers on both CPU and GPU by a factor of 2x, while keeping the accuracy within 1% of the original model.
Spectral Networks and Locally Connected Networks on Graphs
May 21, 2014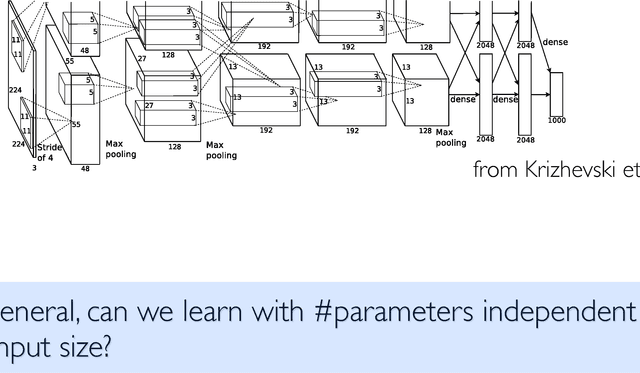

Convolutional Neural Networks are extremely efficient architectures in image and audio recognition tasks, thanks to their ability to exploit the local translational invariance of signal classes over their domain. In this paper we consider possible generalizations of CNNs to signals defined on more general domains without the action of a translation group. In particular, we propose two constructions, one based upon a hierarchical clustering of the domain, and another based on the spectrum of the graph Laplacian. We show through experiments that for low-dimensional graphs it is possible to learn convolutional layers with a number of parameters independent of the input size, resulting in efficient deep architectures.
Intriguing properties of neural networks
Feb 19, 2014

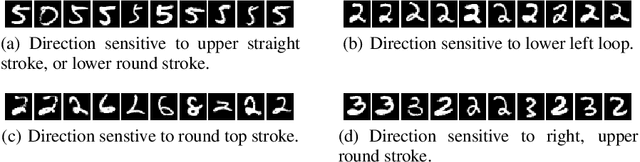
Deep neural networks are highly expressive models that have recently achieved state of the art performance on speech and visual recognition tasks. While their expressiveness is the reason they succeed, it also causes them to learn uninterpretable solutions that could have counter-intuitive properties. In this paper we report two such properties. First, we find that there is no distinction between individual high level units and random linear combinations of high level units, according to various methods of unit analysis. It suggests that it is the space, rather than the individual units, that contains of the semantic information in the high layers of neural networks. Second, we find that deep neural networks learn input-output mappings that are fairly discontinuous to a significant extend. We can cause the network to misclassify an image by applying a certain imperceptible perturbation, which is found by maximizing the network's prediction error. In addition, the specific nature of these perturbations is not a random artifact of learning: the same perturbation can cause a different network, that was trained on a different subset of the dataset, to misclassify the same input.
B-tests: Low Variance Kernel Two-Sample Tests
Feb 10, 2014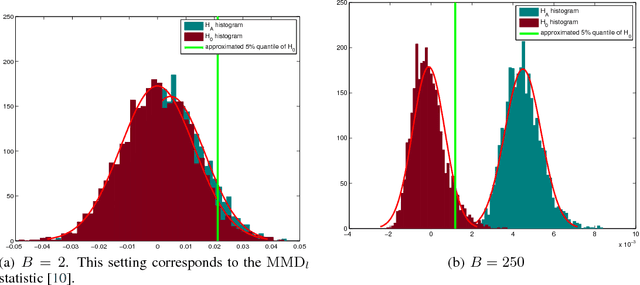

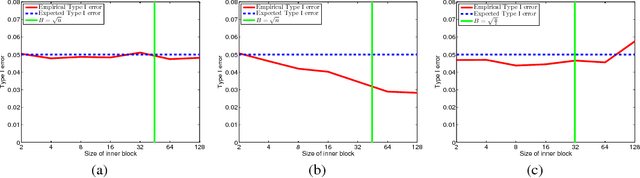

A family of maximum mean discrepancy (MMD) kernel two-sample tests is introduced. Members of the test family are called Block-tests or B-tests, since the test statistic is an average over MMDs computed on subsets of the samples. The choice of block size allows control over the tradeoff between test power and computation time. In this respect, the $B$-test family combines favorable properties of previously proposed MMD two-sample tests: B-tests are more powerful than a linear time test where blocks are just pairs of samples, yet they are more computationally efficient than a quadratic time test where a single large block incorporating all the samples is used to compute a U-statistic. A further important advantage of the B-tests is their asymptotically Normal null distribution: this is by contrast with the U-statistic, which is degenerate under the null hypothesis, and for which estimates of the null distribution are computationally demanding. Recent results on kernel selection for hypothesis testing transfer seamlessly to the B-tests, yielding a means to optimize test power via kernel choice.