 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Error-Correcting Effects of Stochasticity in Discrete Diffusion
May 26, 2026Discrete diffusion models achieve strong performance in text and image generation, but their inference remains slow and must inherently balance sampling efficiency and sample quality. In this work, we present a systematic study of how the \emph{degree of stochasticity} in Markov transitions governs the sampling tradeoff. We show that highly deterministic transitions converge rapidly but suffer from error accumulation, while more stochastic transitions converge more slowly yet can achieve higher final sample quality. Using an information-theoretic analysis, we identify the underlying mechanism as an error-correcting effect induced by \emph{redundant transitions} that symmetrically exchange mass between states, and show that these transitions can provably contract sampling errors. Motivated by this analysis, we propose \emph{Discrete Churn and Restart Sampling} (DCRS), a novel inference algorithm that injects controlled stochasticity by alternating between forward and reverse diffusion processes. Experiments on synthetic datasets and large-scale benchmarks show that DCRS improves the speed-quality tradeoff in the low number of function evaluations regime. On image datasets, DCRS achieves up to a $10\times$ reduction in sampling steps compared to standard samplers while maintaining competitive sample quality, whereas on language benchmarks, we observe more nuanced behavior depending on the corruption process and sampling procedure.
Construction of extra-large scale screening tools for risks of severe mental illnesses using real world healthcare data
Dec 20, 2022Importance: The prevalence of severe mental illnesses (SMIs) in the United States is approximately 3% of the whole population. The ability to conduct risk screening of SMIs at large scale could inform early prevention and treatment. Objective: A scalable machine learning based tool was developed to conduct population-level risk screening for SMIs, including schizophrenia, schizoaffective disorders, psychosis, and bipolar disorders,using 1) healthcare insurance claims and 2) electronic health records (EHRs). Design, setting and participants: Data from beneficiaries from a nationwide commercial healthcare insurer with 77.4 million members and data from patients from EHRs from eight academic hospitals based in the U.S. were used. First, the predictive models were constructed and tested using data in case-control cohorts from insurance claims or EHR data. Second, performance of the predictive models across data sources were analyzed. Third, as an illustrative application, the models were further trained to predict risks of SMIs among 18-year old young adults and individuals with substance associated conditions. Main outcomes and measures: Machine learning-based predictive models for SMIs in the general population were built based on insurance claims and EHR.
Approaching Small Molecule Prioritization as a Cross-Modal Information Retrieval Task through Coordinated Representation Learning
Nov 22, 2019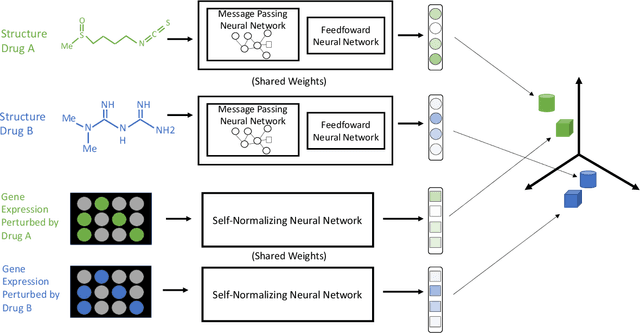
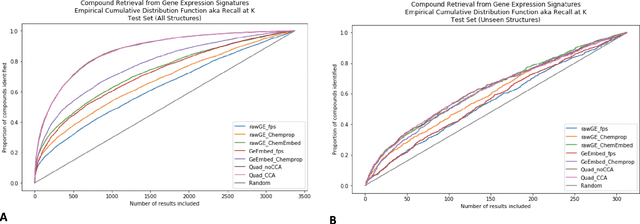
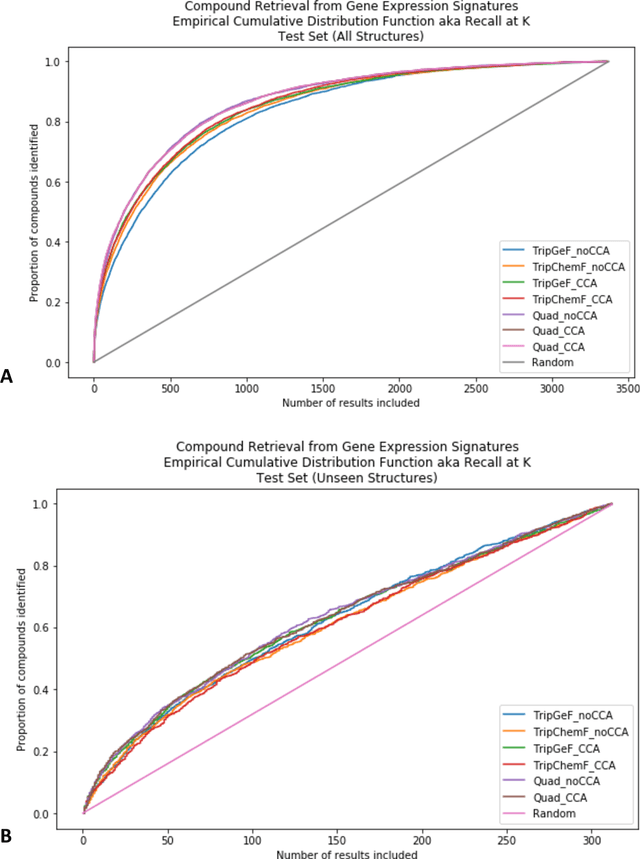
Modeling the relationship between chemical structure and molecular activity is a key task in drug development and precision medicine. In this paper, we utilize a novel deep learning architecture to jointly train coordinated embeddings of chemical structures and transcriptional signatures. We do so by training neural networks in a coordinated manner such that learned chemical representations correlate most highly with the encodings of the transcriptional patterns they induce. We then test this approach by using held-out gene expression signatures as queries into embedding space to recover their corresponding compounds. We evaluate these embeddings' utility for small molecule prioritization on this new benchmark task. Our method outperforms a series of baselines, successfully generalizing to unseen transcriptional experiments, but still struggles to generalize to entirely unseen chemical structures.
Privacy-Preserving Distributed Deep Learning for Clinical Data
Dec 04, 2018Deep learning with medical data often requires larger samples sizes than are available at single providers. While data sharing among institutions is desirable to train more accurate and sophisticated models, it can lead to severe privacy concerns due the sensitive nature of the data. This problem has motivated a number of studies on distributed training of neural networks that do not require direct sharing of the training data. However, simple distributed training does not offer provable privacy guarantees to satisfy technical safe standards and may reveal information about the underlying patients. We present a method to train neural networks for clinical data in a distributed fashion under differential privacy. We demonstrate these methods on two datasets that include information from multiple independent sites, the eICU collaborative Research Database and The Cancer Genome Atlas.