 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval for Extremely Long Queries and Documents with RPRS: a Highly Efficient and Effective Transformer-based Re-Ranker
Mar 02, 2023



Retrieval with extremely long queries and documents is a well-known and challenging task in information retrieval and is commonly known as Query-by-Document (QBD) retrieval. Specifically designed Transformer models that can handle long input sequences have not shown high effectiveness in QBD tasks in previous work. We propose a Re-Ranker based on the novel Proportional Relevance Score (RPRS) to compute the relevance score between a query and the top-k candidate documents. Our extensive evaluation shows RPRS obtains significantly better results than the state-of-the-art models on five different datasets. Furthermore, RPRS is highly efficient since all documents can be pre-processed, embedded, and indexed before query time which gives our re-ranker the advantage of having a complexity of O(N) where N is the total number of sentences in the query and candidate documents. Furthermore, our method solves the problem of the low-resource training in QBD retrieval tasks as it does not need large amounts of training data, and has only three parameters with a limited range that can be optimized with a grid search even if a small amount of labeled data is available. Our detailed analysis shows that RPRS benefits from covering the full length of candidate documents and queries.
Injecting the BM25 Score as Text Improves BERT-Based Re-rankers
Jan 23, 2023



In this paper we propose a novel approach for combining first-stage lexical retrieval models and Transformer-based re-rankers: we inject the relevance score of the lexical model as a token in the middle of the input of the cross-encoder re-ranker. It was shown in prior work that interpolation between the relevance score of lexical and BERT-based re-rankers may not consistently result in higher effectiveness. Our idea is motivated by the finding that BERT models can capture numeric information. We compare several representations of the BM25 score and inject them as text in the input of four different cross-encoders. We additionally analyze the effect for different query types, and investigate the effectiveness of our method for capturing exact matching relevance. Evaluation on the MSMARCO Passage collection and the TREC DL collections shows that the proposed method significantly improves over all cross-encoder re-rankers as well as the common interpolation methods. We show that the improvement is consistent for all query types. We also find an improvement in exact matching capabilities over both BM25 and the cross-encoders. Our findings indicate that cross-encoder re-rankers can efficiently be improved without additional computational burden and extra steps in the pipeline by explicitly adding the output of the first-stage ranker to the model input, and this effect is robust for different models and query types.
Breaking BERT: Understanding its Vulnerabilities for Biomedical Named Entity Recognition through Adversarial Attack
Oct 14, 2021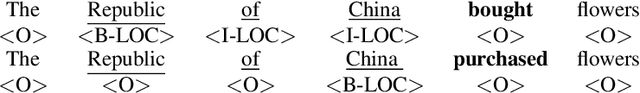
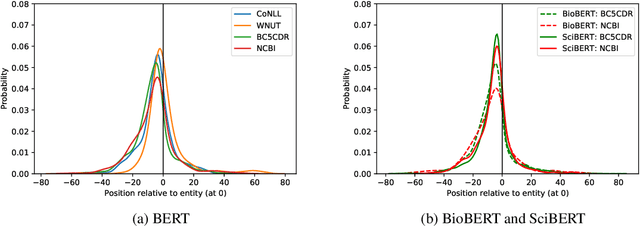
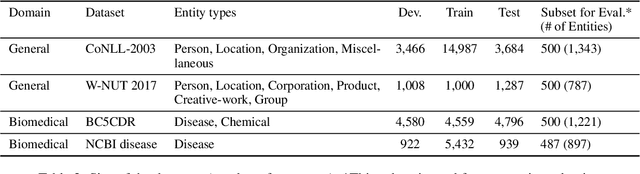
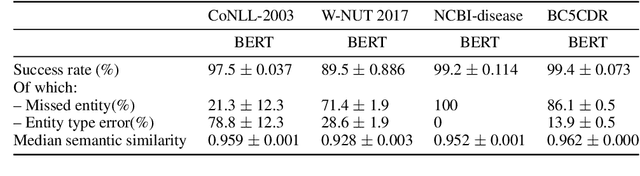
Biomedical named entity recognition (NER) is a key task in the extraction of information from biomedical literature and electronic health records. For this task, both generic and biomedical BERT models are widely used. Robustness of these models is vital for medical applications, such as automated medical decision making. In this paper we investigate the vulnerability of BERT models to variation in input data for NER through adversarial attack. Since adversarial attack methods for NER are sparse, we propose two black-box methods for NER based on existing methods for classification tasks. Experimental results show that the original as well as the biomedical BERT models are highly vulnerable to entity replacement: They can be fooled in 89.2 to 99.4% of the cases to mislabel previously correct entities. BERT models are also vulnerable to variation in the entity context with 20.2 to 45.0% of entities predicted completely wrong and another 29.3 to 53.3% of entities predicted wrong partially. Often a single change is sufficient to fool the model. BERT models seem most vulnerable to changes in the local context of entities. Of the biomedical BERT models, the vulnerability of BioBERT is comparable to the original BERT model whereas SciBERT is even more vulnerable. Our results chart the vulnerabilities of BERT models for biomedical NER and emphasize the importance of further research into uncovering and reducing these weaknesses.
TRECVID 2020: A comprehensive campaign for evaluating video retrieval tasks across multiple application domains
Apr 27, 2021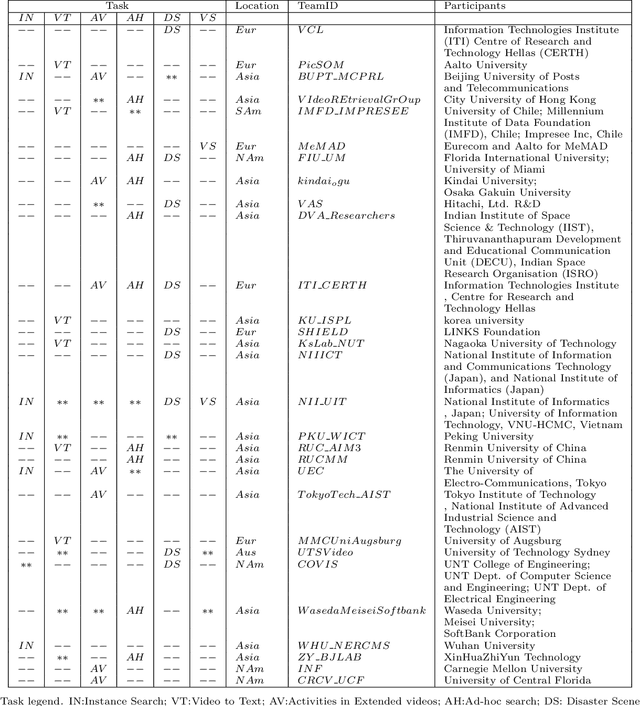

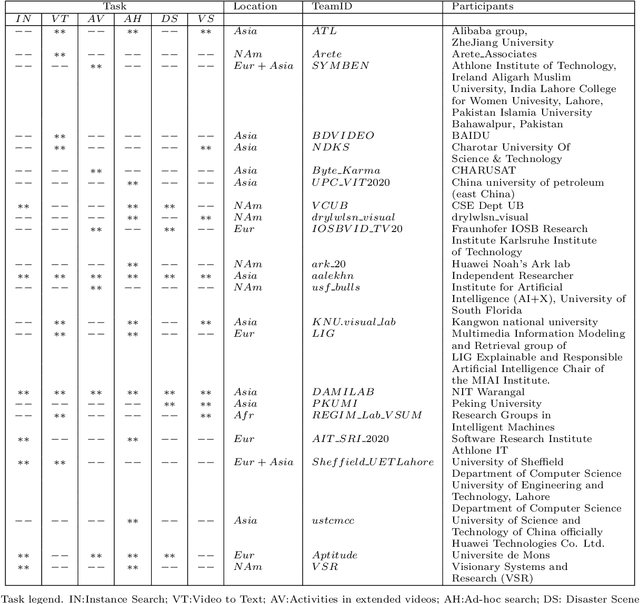
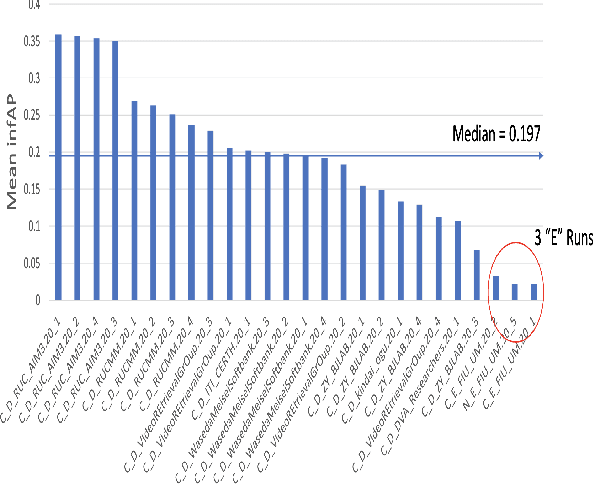
The TREC Video Retrieval Evaluation (TRECVID) is a TREC-style video analysis and retrieval evaluation with the goal of promoting progress in research and development of content-based exploitation and retrieval of information from digital video via open, metrics-based evaluation. Over the last twenty years this effort has yielded a better understanding of how systems can effectively accomplish such processing and how one can reliably benchmark their performance. TRECVID has been funded by NIST (National Institute of Standards and Technology) and other US government agencies. In addition, many organizations and individuals worldwide contribute significant time and effort. TRECVID 2020 represented a continuation of four tasks and the addition of two new tasks. In total, 29 teams from various research organizations worldwide completed one or more of the following six tasks: 1. Ad-hoc Video Search (AVS), 2. Instance Search (INS), 3. Disaster Scene Description and Indexing (DSDI), 4. Video to Text Description (VTT), 5. Activities in Extended Video (ActEV), 6. Video Summarization (VSUM). This paper is an introduction to the evaluation framework, tasks, data, and measures used in the evaluation campaign.
TRECVID 2019: An Evaluation Campaign to Benchmark Video Activity Detection, Video Captioning and Matching, and Video Search & Retrieval
Sep 21, 2020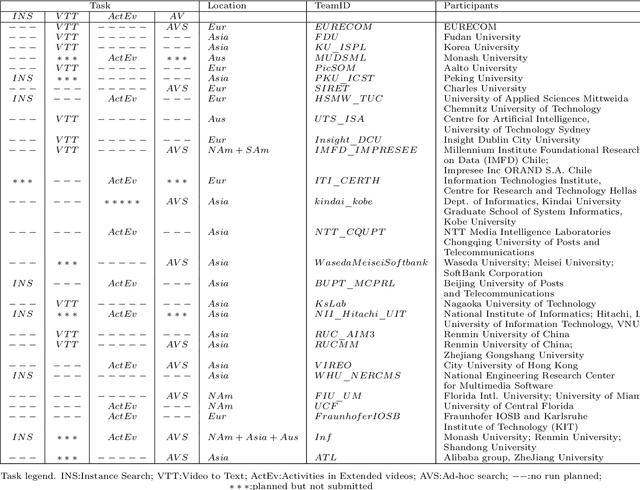
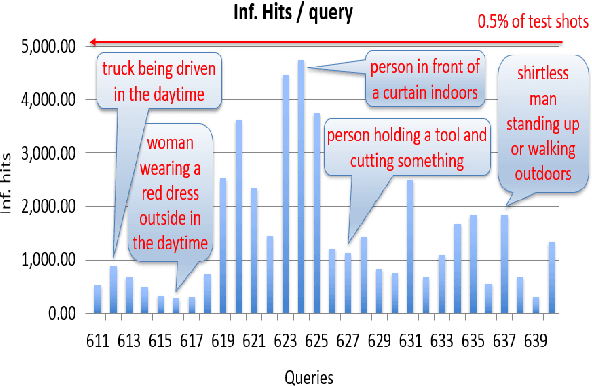
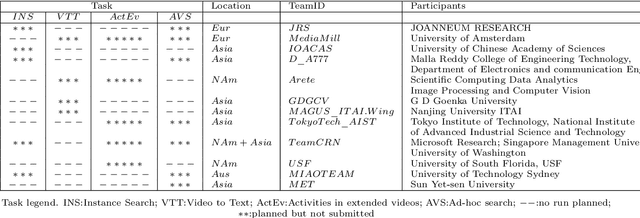
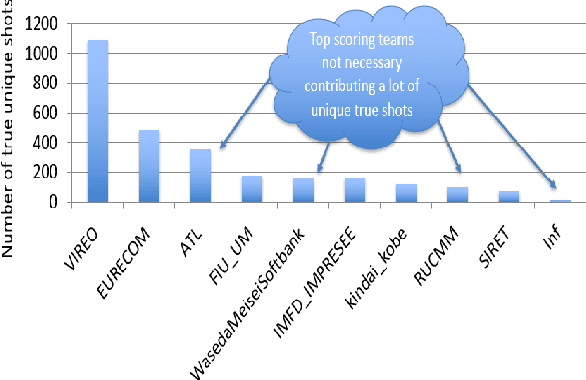
The TREC Video Retrieval Evaluation (TRECVID) 2019 was a TREC-style video analysis and retrieval evaluation, the goal of which remains to promote progress in research and development of content-based exploitation and retrieval of information from digital video via open, metrics-based evaluation. Over the last nineteen years this effort has yielded a better understanding of how systems can effectively accomplish such processing and how one can reliably benchmark their performance. TRECVID has been funded by NIST (National Institute of Standards and Technology) and other US government agencies. In addition, many organizations and individuals worldwide contribute significant time and effort. TRECVID 2019 represented a continuation of four tasks from TRECVID 2018. In total, 27 teams from various research organizations worldwide completed one or more of the following four tasks: 1. Ad-hoc Video Search (AVS) 2. Instance Search (INS) 3. Activities in Extended Video (ActEV) 4. Video to Text Description (VTT) This paper is an introduction to the evaluation framework, tasks, data, and measures used in the workshop.
Embedding Web-based Statistical Translation Models in Cross-Language Information Retrieval
Dec 03, 2003Although more and more language pairs are covered by machine translation services, there are still many pairs that lack translation resources. Cross-language information retrieval (CLIR) is an application which needs translation functionality of a relatively low level of sophistication since current models for information retrieval (IR) are still based on a bag-of-words. The Web provides a vast resource for the automatic construction of parallel corpora which can be used to train statistical translation models automatically. The resulting translation models can be embedded in several ways in a retrieval model. In this paper, we will investigate the problem of automatically mining parallel texts from the Web and different ways of integrating the translation models within the retrieval process. Our experiments on standard test collections for CLIR show that the Web-based translation models can surpass commercial MT systems in CLIR tasks. These results open the perspective of constructing a fully automatic query translation device for CLIR at a very low cost.
* 37 pages