 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Human-to-Humanoid Motion Imitation Using Control Barrier Functions
Apr 13, 2026Ensuring operational safety is critical for human-to-humanoid motion imitation. This paper presents a vision-based framework that enables a humanoid robot to imitate human movements while avoiding collisions. Human skeletal keypoints are captured by a single camera and converted into joint angles for motion retargeting. Safety is enforced through a Control Barrier Function (CBF) layer formulated as a Quadratic Program (QP), which filters imitation commands to prevent both self-collisions and human-robot collisions. Simulation results validate the effectiveness of the proposed framework for real-time collision-aware motion imitation.
Cost-Matching Model Predictive Control for Efficient Reinforcement Learning in Humanoid Locomotion
Mar 30, 2026In this paper, we propose a cost-matching approach for optimal humanoid locomotion within a Model Predictive Control (MPC)-based Reinforcement Learning (RL) framework. A parameterized MPC formulation with centroidal dynamics is trained to approximate the action-value function obtained from high-fidelity closed-loop data. Specifically, the MPC cost-to-go is evaluated along recorded state-action trajectories, and the parameters are updated to minimize the discrepancy between MPC-predicted values and measured returns. This formulation enables efficient gradient-based learning while avoiding the computational burden of repeatedly solving the MPC problem during training. The proposed method is validated in simulation using a commercial humanoid platform. Results demonstrate improved locomotion performance and robustness to model mismatch and external disturbances compared with manually tuned baselines.
Investigation of the effectiveness of applying ChatGPT in Dialogic Teaching Using Electroencephalography
Apr 08, 2024



In recent years, the rapid development of artificial intelligence technology, especially the emergence of large language models (LLMs) such as ChatGPT, has presented significant prospects for application in the field of education. LLMs possess the capability to interpret knowledge, answer questions, and consider context, thus providing support for dialogic teaching to students. Therefore, an examination of the capacity of LLMs to effectively fulfill instructional roles, thereby facilitating student learning akin to human educators within dialogic teaching scenarios, is an exceptionally valuable research topic. This research recruited 34 undergraduate students as participants, who were randomly divided into two groups. The experimental group engaged in dialogic teaching using ChatGPT, while the control group interacted with human teachers. Both groups learned the histogram equalization unit in the information-related course "Digital Image Processing". The research findings show comparable scores between the two groups on the retention test. However, students who engaged in dialogue with ChatGPT exhibited lower performance on the transfer test. Electroencephalography data revealed that students who interacted with ChatGPT exhibited higher levels of cognitive activity, suggesting that ChatGPT could help students establish a knowledge foundation and stimulate cognitive activity. However, its strengths on promoting students. knowledge application and creativity were insignificant. Based upon the research findings, it is evident that ChatGPT cannot fully excel in fulfilling teaching tasks in the dialogue teaching in information related courses. Combining ChatGPT with traditional human teachers might be a more ideal approach. The synergistic use of both can provide students with more comprehensive learning support, thus contributing to enhancing the quality of teaching.
Quasi-Newton Iteration in Deterministic Policy Gradient
Mar 25, 2022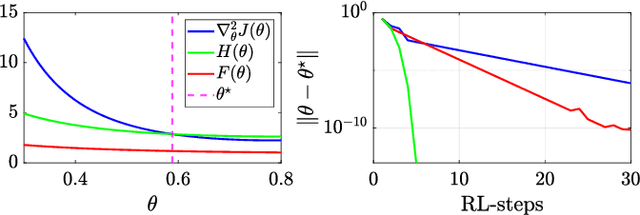
This paper presents a model-free approximation for the Hessian of the performance of deterministic policies to use in the context of Reinforcement Learning based on Quasi-Newton steps in the policy parameters. We show that the approximate Hessian converges to the exact Hessian at the optimal policy, and allows for a superlinear convergence in the learning, provided that the policy parametrization is rich. The natural policy gradient method can be interpreted as a particular case of the proposed method. We analytically verify the formulation in a simple linear case and compare the convergence of the proposed method with the natural policy gradient in a nonlinear example.
MPC-based Reinforcement Learning for Economic Problems with Application to Battery Storage
Apr 06, 2021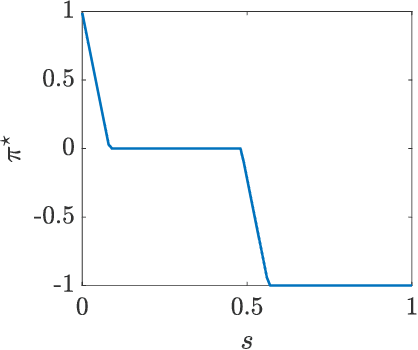
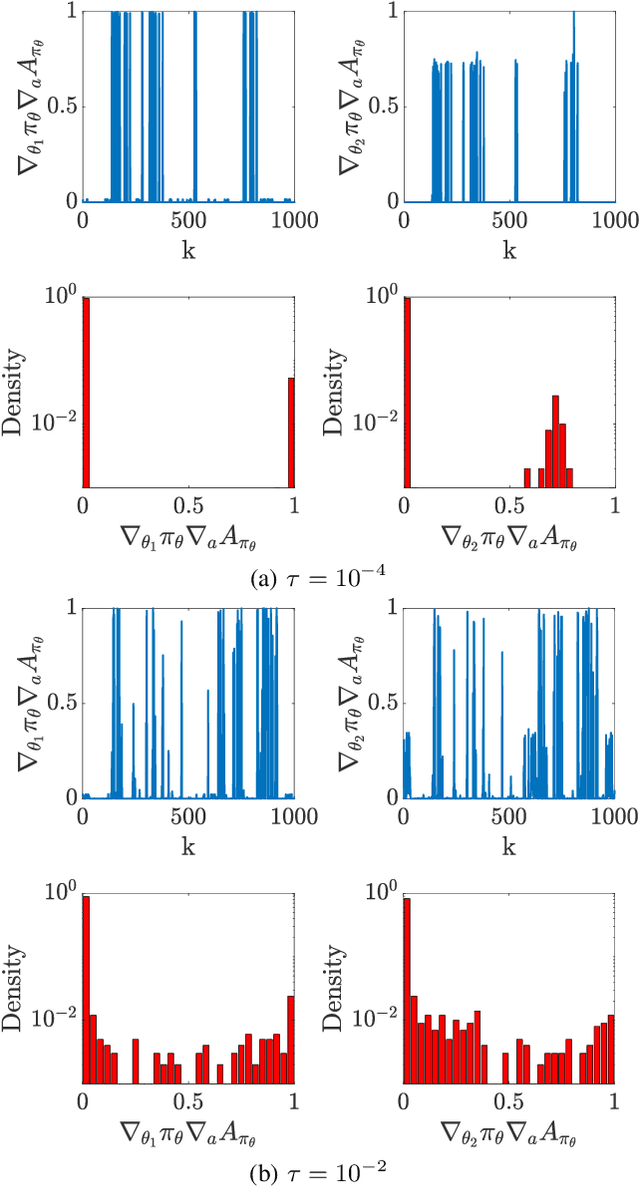
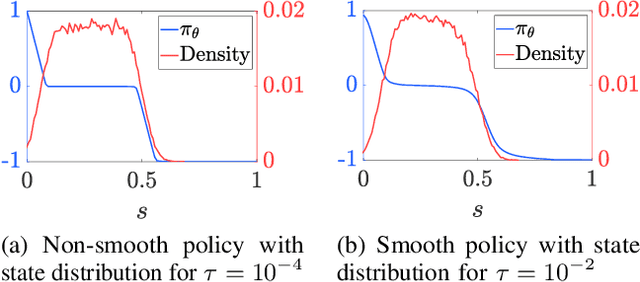
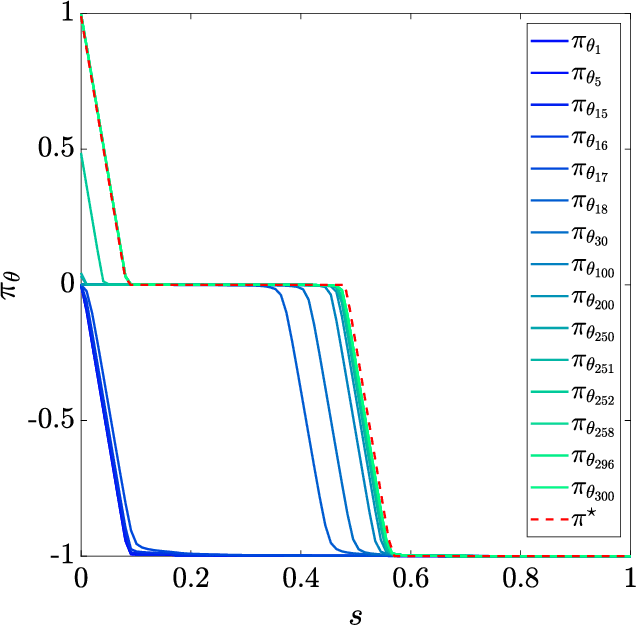
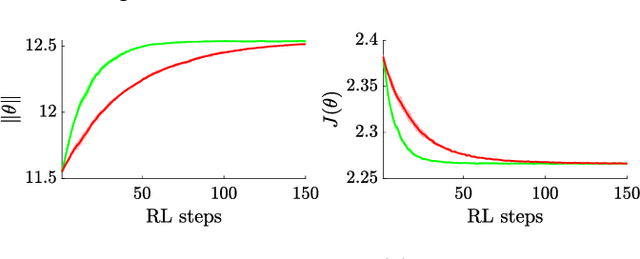
In this paper, we are interested in optimal control problems with purely economic costs, which often yield optimal policies having a (nearly) bang-bang structure. We focus on policy approximations based on Model Predictive Control (MPC) and the use of the deterministic policy gradient method to optimize the MPC closed-loop performance in the presence of unmodelled stochasticity or model error. When the policy has a (nearly) bang-bang structure, we observe that the policy gradient method can struggle to produce meaningful steps in the policy parameters. To tackle this issue, we propose a homotopy strategy based on the interior-point method, providing a relaxation of the policy during the learning. We investigate a specific well-known battery storage problem, and show that the proposed method delivers a homogeneous and faster learning than a classical policy gradient approach.