 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShape Inpainting using 3D Generative Adversarial Network and Recurrent Convolutional Networks
Nov 17, 2017

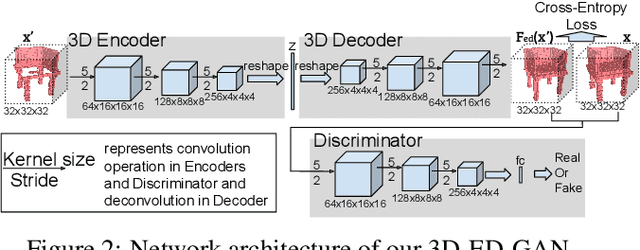
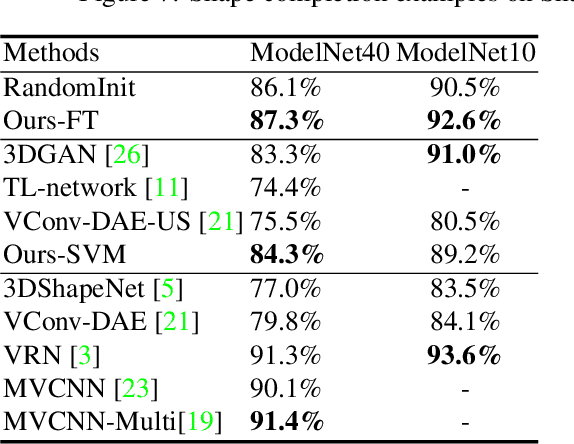
Recent advances in convolutional neural networks have shown promising results in 3D shape completion. But due to GPU memory limitations, these methods can only produce low-resolution outputs. To inpaint 3D models with semantic plausibility and contextual details, we introduce a hybrid framework that combines a 3D Encoder-Decoder Generative Adversarial Network (3D-ED-GAN) and a Long-term Recurrent Convolutional Network (LRCN). The 3D-ED-GAN is a 3D convolutional neural network trained with a generative adversarial paradigm to fill missing 3D data in low-resolution. LRCN adopts a recurrent neural network architecture to minimize GPU memory usage and incorporates an Encoder-Decoder pair into a Long Short-term Memory Network. By handling the 3D model as a sequence of 2D slices, LRCN transforms a coarse 3D shape into a more complete and higher resolution volume. While 3D-ED-GAN captures global contextual structure of the 3D shape, LRCN localizes the fine-grained details. Experimental results on both real-world and synthetic data show reconstructions from corrupted models result in complete and high-resolution 3D objects.
Scene Labeling using Gated Recurrent Units with Explicit Long Range Conditioning
Mar 28, 2017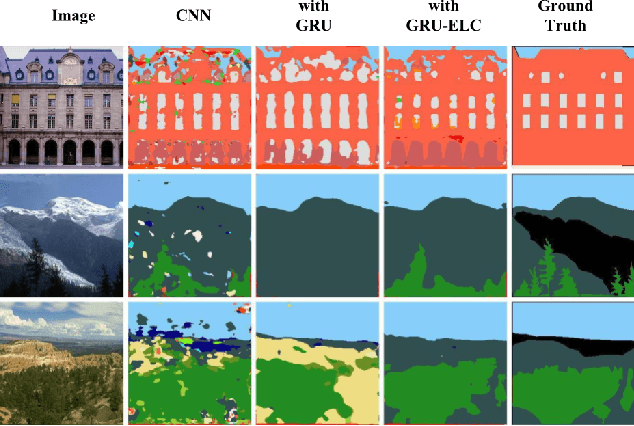
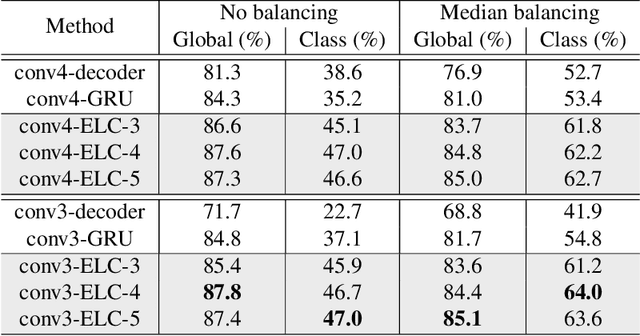
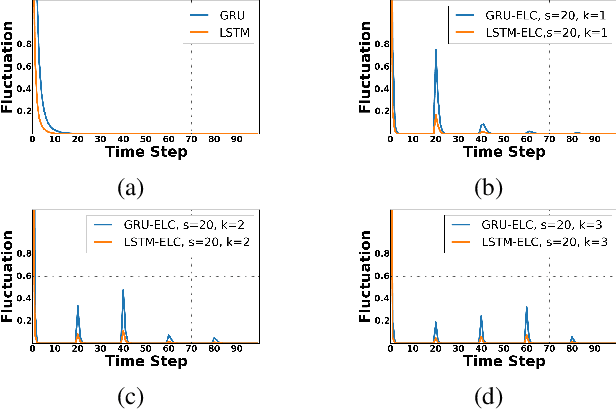
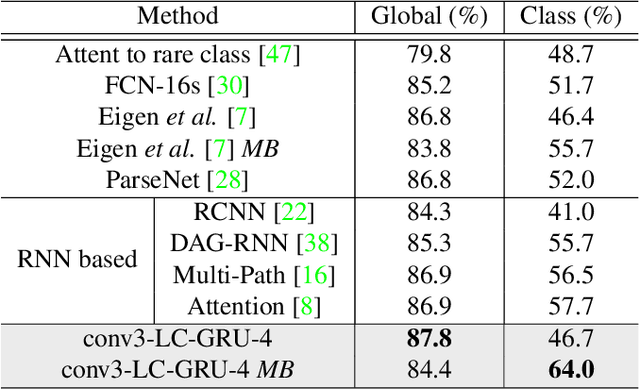
Recurrent neural network (RNN), as a powerful contextual dependency modeling framework, has been widely applied to scene labeling problems. However, this work shows that directly applying traditional RNN architectures, which unfolds a 2D lattice grid into a sequence, is not sufficient to model structure dependencies in images due to the "impact vanishing" problem. First, we give an empirical analysis about the "impact vanishing" problem. Then, a new RNN unit named Recurrent Neural Network with explicit long range conditioning (RNN-ELC) is designed to alleviate this problem. A novel neural network architecture is built for scene labeling tasks where one of the variants of the new RNN unit, Gated Recurrent Unit with Explicit Long-range Conditioning (GRU-ELC), is used to model multi scale contextual dependencies in images. We validate the use of GRU-ELC units with state-of-the-art performance on three standard scene labeling datasets. Comprehensive experiments demonstrate that the new GRU-ELC unit benefits scene labeling problem a lot as it can encode longer contextual dependencies in images more effectively than traditional RNN units.
A diffusion and clustering-based approach for finding coherent motions and understanding crowd scenes
Feb 16, 2016
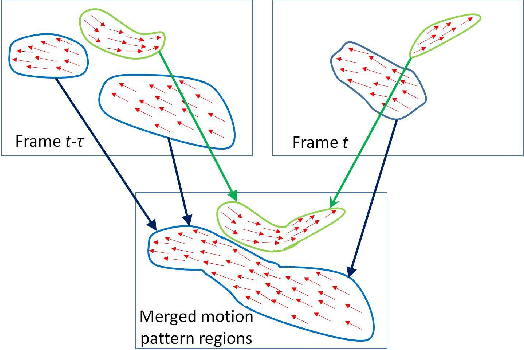
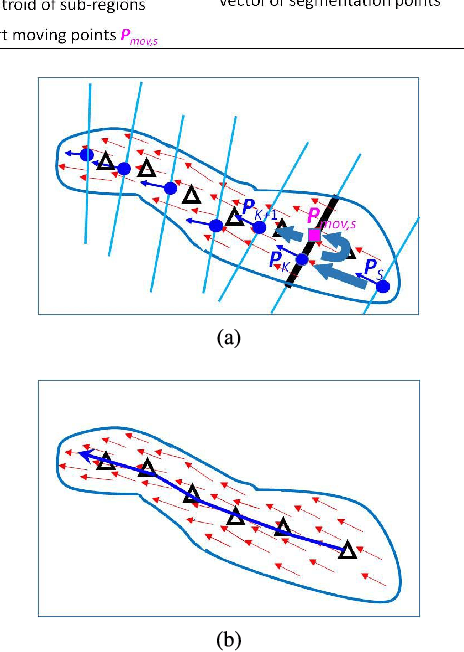

This paper addresses the problem of detecting coherent motions in crowd scenes and presents its two applications in crowd scene understanding: semantic region detection and recurrent activity mining. It processes input motion fields (e.g., optical flow fields) and produces a coherent motion filed, named as thermal energy field. The thermal energy field is able to capture both motion correlation among particles and the motion trends of individual particles which are helpful to discover coherency among them. We further introduce a two-step clustering process to construct stable semantic regions from the extracted time-varying coherent motions. These semantic regions can be used to recognize pre-defined activities in crowd scenes. Finally, we introduce a cluster-and-merge process which automatically discovers recurrent activities in crowd scenes by clustering and merging the extracted coherent motions. Experiments on various videos demonstrate the effectiveness of our approach.