 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePokeNet: Learning Kinematic Models of Articulated Objects from Human Observations
Feb 02, 2026Articulation modeling enables robots to learn joint parameters of articulated objects for effective manipulation which can then be used downstream for skill learning or planning. Existing approaches often rely on prior knowledge about the objects, such as the number or type of joints. Some of these approaches also fail to recover occluded joints that are only revealed during interaction. Others require large numbers of multi-view images for every object, which is impractical in real-world settings. Furthermore, prior works neglect the order of manipulations, which is essential for many multi-DoF objects where one joint must be operated before another, such as a dishwasher. We introduce PokeNet, an end-to-end framework that estimates articulation models from a single human demonstration without prior object knowledge. Given a sequence of point cloud observations of a human manipulating an unknown object, PokeNet predicts joint parameters, infers manipulation order, and tracks joint states over time. PokeNet outperforms existing state-of-the-art methods, improving joint axis and state estimation accuracy by an average of over 27% across diverse objects, including novel and unseen categories. We demonstrate these gains in both simulation and real-world environments.
Learning Sequential Kinematic Models from Demonstrations for Multi-Jointed Articulated Objects
May 09, 2025As robots become more generalized and deployed in diverse environments, they must interact with complex objects, many with multiple independent joints or degrees of freedom (DoF) requiring precise control. A common strategy is object modeling, where compact state-space models are learned from real-world observations and paired with classical planning. However, existing methods often rely on prior knowledge or focus on single-DoF objects, limiting their applicability. They also fail to handle occluded joints and ignore the manipulation sequences needed to access them. We address this by learning object models from human demonstrations. We introduce Object Kinematic Sequence Machines (OKSMs), a novel representation capturing both kinematic constraints and manipulation order for multi-DoF objects. To estimate these models from point cloud data, we present Pokenet, a deep neural network trained on human demonstrations. We validate our approach on 8,000 simulated and 1,600 real-world annotated samples. Pokenet improves joint axis and state estimation by over 20 percent on real-world data compared to prior methods. Finally, we demonstrate OKSMs on a Sawyer robot using inverse kinematics-based planning to manipulate multi-DoF objects.
Continual Skill and Task Learning via Dialogue
Sep 05, 2024



Continual and interactive robot learning is a challenging problem as the robot is present with human users who expect the robot to learn novel skills to solve novel tasks perpetually with sample efficiency. In this work we present a framework for robots to query and learn visuo-motor robot skills and task relevant information via natural language dialog interactions with human users. Previous approaches either focus on improving the performance of instruction following agents, or passively learn novel skills or concepts. Instead, we used dialog combined with a language-skill grounding embedding to query or confirm skills and/or tasks requested by a user. To achieve this goal, we developed and integrated three different components for our agent. Firstly, we propose a novel visual-motor control policy ACT with Low Rank Adaptation (ACT-LoRA), which enables the existing SoTA ACT model to perform few-shot continual learning. Secondly, we develop an alignment model that projects demonstrations across skill embodiments into a shared embedding allowing us to know when to ask questions and/or demonstrations from users. Finally, we integrated an existing LLM to interact with a human user to perform grounded interactive continual skill learning to solve a task. Our ACT-LoRA model learns novel fine-tuned skills with a 100% accuracy when trained with only five demonstrations for a novel skill while still maintaining a 74.75% accuracy on pre-trained skills in the RLBench dataset where other models fall significantly short. We also performed a human-subjects study with 8 subjects to demonstrate the continual learning capabilities of our combined framework. We achieve a success rate of 75% in the task of sandwich making with the real robot learning from participant data demonstrating that robots can learn novel skills or task knowledge from dialogue with non-expert users using our approach.
An Improved Strategy for Blood Glucose Control Using Multi-Step Deep Reinforcement Learning
Mar 15, 2024Blood Glucose (BG) control involves keeping an individual's BG within a healthy range through extracorporeal insulin injections is an important task for people with type 1 diabetes. However,traditional patient self-management is cumbersome and risky. Recent research has been devoted to exploring individualized and automated BG control approaches, among which Deep Reinforcement Learning (DRL) shows potential as an emerging approach. In this paper, we use an exponential decay model of drug concentration to convert the formalization of the BG control problem, which takes into account the delay and prolongedness of drug effects, from a PAE-POMDP (Prolonged Action Effect-Partially Observable Markov Decision Process) to a MDP, and we propose a novel multi-step DRL-based algorithm to solve the problem. The Prioritized Experience Replay (PER) sampling method is also used in it. Compared to single-step bootstrapped updates, multi-step learning is more efficient and reduces the influence from biasing targets. Our proposed method converges faster and achieves higher cumulative rewards compared to the benchmark in the same training environment, and improves the time-in-range (TIR), the percentage of time the patient's BG is within the target range, in the evaluation phase. Our work validates the effectiveness of multi-step reinforcement learning in BG control, which may help to explore the optimal glycemic control measure and improve the survival of diabetic patients.
Interactive Visual Task Learning for Robots
Dec 20, 2023



We present a framework for robots to learn novel visual concepts and tasks via in-situ linguistic interactions with human users. Previous approaches have either used large pre-trained visual models to infer novel objects zero-shot, or added novel concepts along with their attributes and representations to a concept hierarchy. We extend the approaches that focus on learning visual concept hierarchies by enabling them to learn novel concepts and solve unseen robotics tasks with them. To enable a visual concept learner to solve robotics tasks one-shot, we developed two distinct techniques. Firstly, we propose a novel approach, Hi-Viscont(HIerarchical VISual CONcept learner for Task), which augments information of a novel concept to its parent nodes within a concept hierarchy. This information propagation allows all concepts in a hierarchy to update as novel concepts are taught in a continual learning setting. Secondly, we represent a visual task as a scene graph with language annotations, allowing us to create novel permutations of a demonstrated task zero-shot in-situ. We present two sets of results. Firstly, we compare Hi-Viscont with the baseline model (FALCON) on visual question answering(VQA) in three domains. While being comparable to the baseline model on leaf level concepts, Hi-Viscont achieves an improvement of over 9% on non-leaf concepts on average. We compare our model's performance against the baseline FALCON model. Our framework achieves 33% improvements in success rate metric, and 19% improvements in the object level accuracy compared to the baseline model. With both of these results we demonstrate the ability of our model to learn tasks and concepts in a continual learning setting on the robot.
An Empirical Study on Finding Spans
Oct 14, 2022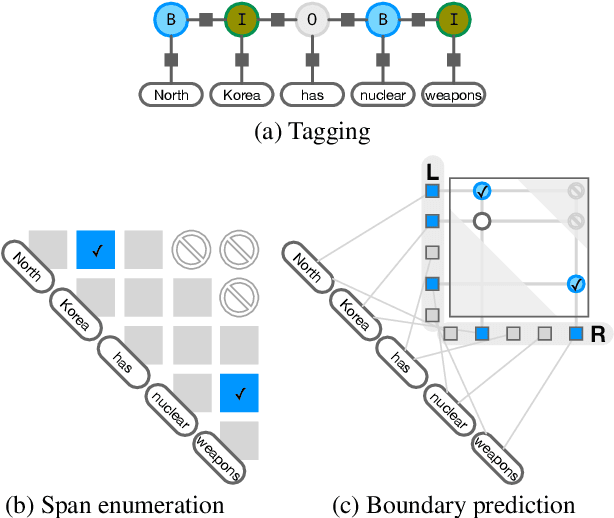
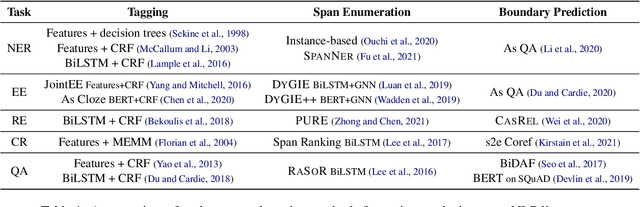
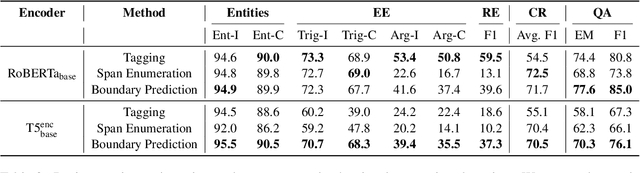
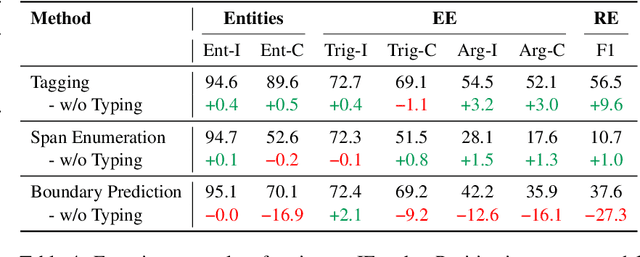
We present an empirical study on methods for span finding, the selection of consecutive tokens in text for some downstream tasks. We focus on approaches that can be employed in training end-to-end information extraction systems, and find there is no definitive solution without considering task properties, and provide our observations to help with future design choices: 1) a tagging approach often yields higher precision while span enumeration and boundary prediction provide higher recall; 2) span type information can benefit a boundary prediction approach; 3) additional contextualization does not help span finding in most cases.
Iterative Document-level Information Extraction via Imitation Learning
Oct 12, 2022
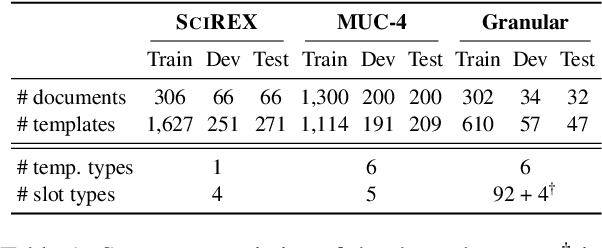

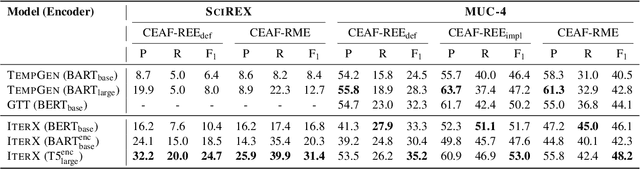
We present a novel iterative extraction (IterX) model for extracting complex relations, or templates, i.e., N-tuples representing a mapping from named slots to spans of text contained within a document. Documents may support zero or more instances of a template of any particular type, leading to the tasks of identifying the templates in a document, and extracting each template's slot values. Our imitation learning approach relieves the need to use predefined template orders to train an extractor and leads to state-of-the-art results on two established benchmarks -- 4-ary relation extraction on SciREX and template extraction on MUC-4 -- as well as a strong baseline on the new BETTER Granular task.
Link Prediction via Graph Attention Network
Oct 29, 2019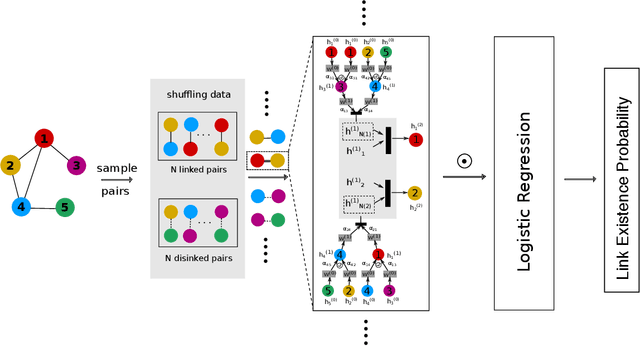
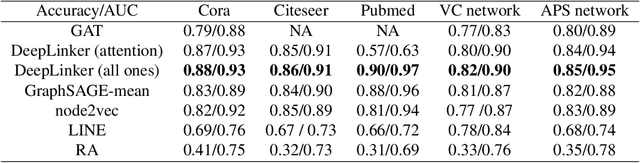
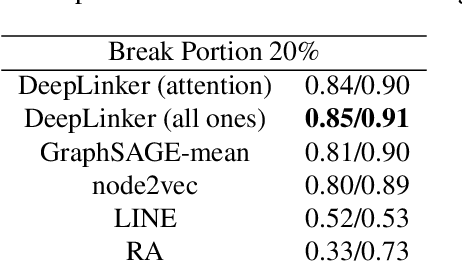

Link prediction aims to infer missing links or predicting the future ones based on currently observed partial networks, it is a fundamental problem in network science with tremendous real-world applications. However, conventional link prediction approaches neither have high prediction accuracy nor being capable of revealing the hidden information behind links. To address this problem, we generalize the latest techniques in deep learning on graphs and present a new link prediction model - DeepLinker. Instead of learning node representation with the node label information, DeepLinker uses the links as supervised information. Experiments on five graphs show that DeepLinker can not only achieve the state-of-the-art link prediction accuracy, but also acquire the efficient node representations and node centrality ranking as the byproducts. Although the representations are obtained without any supervised node label information, they still perform well on node ranking and node classification tasks.