 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Sample Selection with Confidence Tracking: Identifying Correctly Labeled yet Hard-to-Learn Samples in Noisy Data
Apr 24, 2025We propose a novel sample selection method for image classification in the presence of noisy labels. Existing methods typically consider small-loss samples as correctly labeled. However, some correctly labeled samples are inherently difficult for the model to learn and can exhibit high loss similar to mislabeled samples in the early stages of training. Consequently, setting a threshold on per-sample loss to select correct labels results in a trade-off between precision and recall in sample selection: a lower threshold may miss many correctly labeled hard-to-learn samples (low recall), while a higher threshold may include many mislabeled samples (low precision). To address this issue, our goal is to accurately distinguish correctly labeled yet hard-to-learn samples from mislabeled ones, thus alleviating the trade-off dilemma. We achieve this by considering the trends in model prediction confidence rather than relying solely on loss values. Empirical observations show that only for correctly labeled samples, the model's prediction confidence for the annotated labels typically increases faster than for any other classes. Based on this insight, we propose tracking the confidence gaps between the annotated labels and other classes during training and evaluating their trends using the Mann-Kendall Test. A sample is considered potentially correctly labeled if all its confidence gaps tend to increase. Our method functions as a plug-and-play component that can be seamlessly integrated into existing sample selection techniques. Experiments on several standard benchmarks and real-world datasets demonstrate that our method enhances the performance of existing methods for learning with noisy labels.
Automatic Noisy Label Correction for Fine-Grained Entity Typing
May 10, 2022
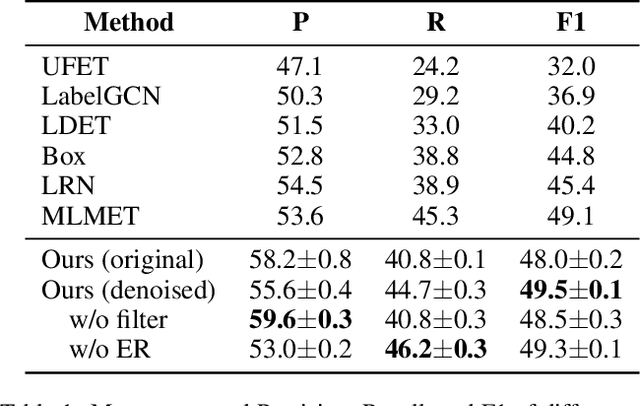
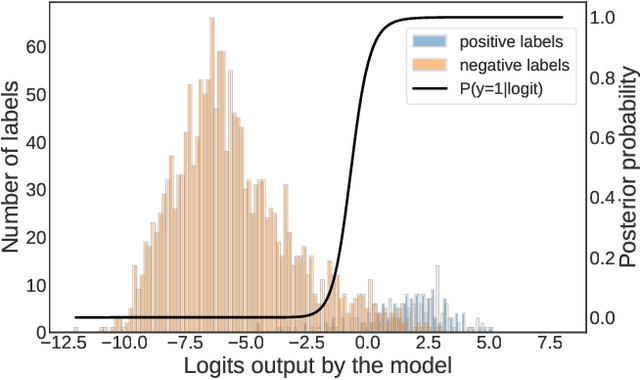
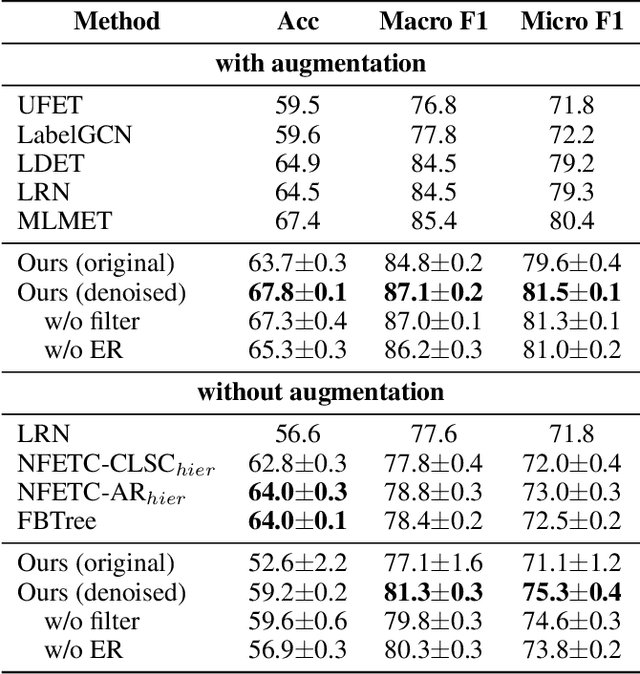
Fine-grained entity typing (FET) aims to assign proper semantic types to entity mentions according to their context, which is a fundamental task in various entity-leveraging applications. Current FET systems usually establish on large-scale weakly-supervised/distantly annotation data, which may contain abundant noise and thus severely hinder the performance of the FET task. Although previous studies have made great success in automatically identifying the noisy labels in FET, they usually rely on some auxiliary resources which may be unavailable in real-world applications (e.g. pre-defined hierarchical type structures, human-annotated subsets). In this paper, we propose a novel approach to automatically correct noisy labels for FET without external resources. Specifically, it first identifies the potentially noisy labels by estimating the posterior probability of a label being positive or negative according to the logits output by the model, and then relabel candidate noisy labels by training a robust model over the remaining clean labels. Experiments on two popular benchmarks prove the effectiveness of our method. Our source code can be obtained from https://github.com/CCIIPLab/DenoiseFET.
Context-aware Entity Typing in Knowledge Graphs
Sep 16, 2021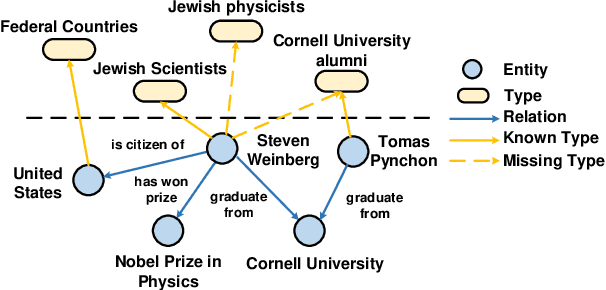
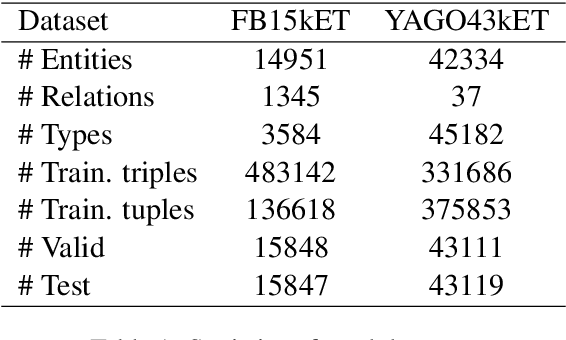
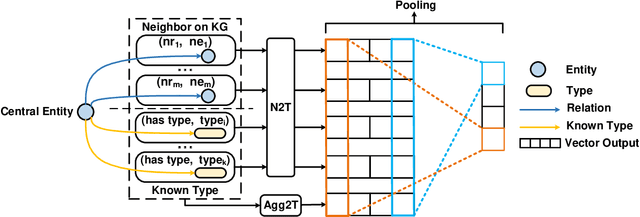
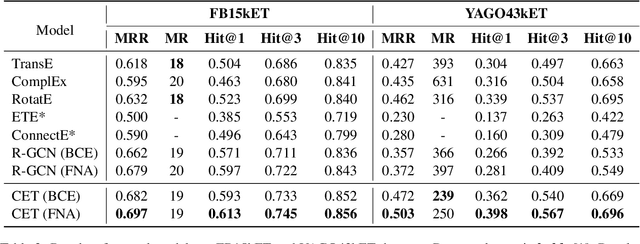
Knowledge graph entity typing aims to infer entities' missing types in knowledge graphs which is an important but under-explored issue. This paper proposes a novel method for this task by utilizing entities' contextual information. Specifically, we design two inference mechanisms: i) N2T: independently use each neighbor of an entity to infer its type; ii) Agg2T: aggregate the neighbors of an entity to infer its type. Those mechanisms will produce multiple inference results, and an exponentially weighted pooling method is used to generate the final inference result. Furthermore, we propose a novel loss function to alleviate the false-negative problem during training. Experiments on two real-world KGs demonstrate the effectiveness of our method. The source code and data of this paper can be obtained from https://github.com/CCIIPLab/CET.