 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval-Augmented Multimodal Model for Fake News Detection
Apr 20, 2026In recent years, multimodal multidomain fake news detection has garnered increasing attention. Nevertheless, this direction presents two significant challenges: (1) Failure to Capture Cross-Instance Narrative Consistency: existing models usually evaluate each news in isolation, fail to capture cross-instance narrative consistency, and thus struggle to address the spread of cluster based fake news driven by social media; (2) Lack of Domain Specific Knowledge for Reasoning: conventional models, which rely solely on knowledge encoded in their parameters during training, struggle to generalize to new or data-scarce domains (e.g., emerging events or niche topics). To tackle these challenges, we introduce Retrieval-Augmented Multimodal Model for Fake News Detection (RAMM). First, RAMM employs a Multimodal Large Language Model (MLLM) as its backbone to capture cross-modal semantic information from news samples. Second, RAMM incorporates an Abstract Narrative Alignment Module. This component adaptively extracts abstract narrative consistency from diverse instances across distinct domains, aggregates relevant knowledge, and thereby enables the modeling of high-level narrative information. Finally, RAMM introduces a Semantic Representation Alignment Module, which aligns the model's decision-making paradigm with that of humans - specifically, it shifts the model's reasoning process from direct inference on multimodal features to an instance-based analogical reasoning process. Extensive experimental results on three public datasets validate the efficacy of our proposed approach. Our code is available at the following link: https://github.com/li-yiheng/RAMM
Multi-Modal Multi-Behavior Sequential Recommendation with Conditional Diffusion-Based Feature Denoising
Aug 07, 2025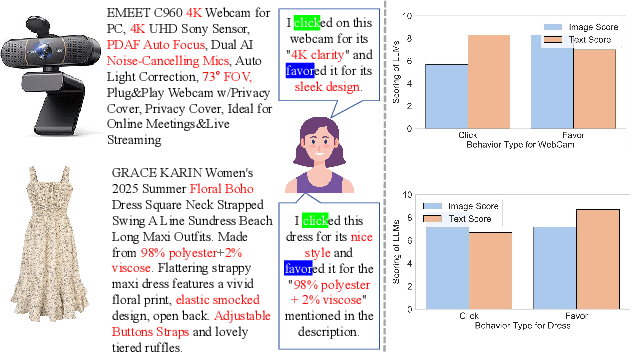

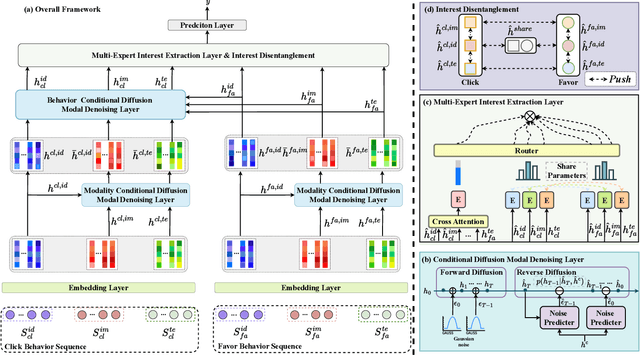
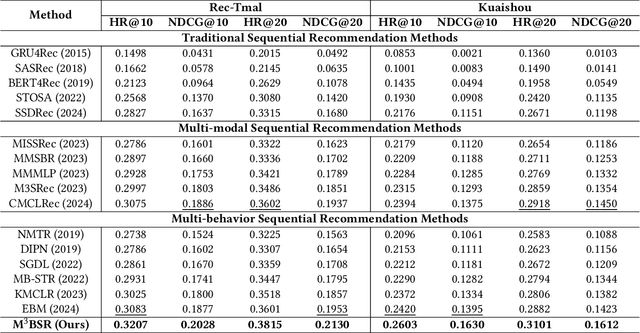
The sequential recommendation system utilizes historical user interactions to predict preferences. Effectively integrating diverse user behavior patterns with rich multimodal information of items to enhance the accuracy of sequential recommendations is an emerging and challenging research direction. This paper focuses on the problem of multi-modal multi-behavior sequential recommendation, aiming to address the following challenges: (1) the lack of effective characterization of modal preferences across different behaviors, as user attention to different item modalities varies depending on the behavior; (2) the difficulty of effectively mitigating implicit noise in user behavior, such as unintended actions like accidental clicks; (3) the inability to handle modality noise in multi-modal representations, which further impacts the accurate modeling of user preferences. To tackle these issues, we propose a novel Multi-Modal Multi-Behavior Sequential Recommendation model (M$^3$BSR). This model first removes noise in multi-modal representations using a Conditional Diffusion Modality Denoising Layer. Subsequently, it utilizes deep behavioral information to guide the denoising of shallow behavioral data, thereby alleviating the impact of noise in implicit feedback through Conditional Diffusion Behavior Denoising. Finally, by introducing a Multi-Expert Interest Extraction Layer, M$^3$BSR explicitly models the common and specific interests across behaviors and modalities to enhance recommendation performance. Experimental results indicate that M$^3$BSR significantly outperforms existing state-of-the-art methods on benchmark datasets.
* SIGIR 2025