 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Generative and Discriminative Learning: Few-Shot Relation Extraction via Two-Stage Knowledge-Guided Pre-training
May 18, 2025



Few-Shot Relation Extraction (FSRE) remains a challenging task due to the scarcity of annotated data and the limited generalization capabilities of existing models. Although large language models (LLMs) have demonstrated potential in FSRE through in-context learning (ICL), their general-purpose training objectives often result in suboptimal performance for task-specific relation extraction. To overcome these challenges, we propose TKRE (Two-Stage Knowledge-Guided Pre-training for Relation Extraction), a novel framework that synergistically integrates LLMs with traditional relation extraction models, bridging generative and discriminative learning paradigms. TKRE introduces two key innovations: (1) leveraging LLMs to generate explanation-driven knowledge and schema-constrained synthetic data, addressing the issue of data scarcity; and (2) a two-stage pre-training strategy combining Masked Span Language Modeling (MSLM) and Span-Level Contrastive Learning (SCL) to enhance relational reasoning and generalization. Together, these components enable TKRE to effectively tackle FSRE tasks. Comprehensive experiments on benchmark datasets demonstrate the efficacy of TKRE, achieving new state-of-the-art performance in FSRE and underscoring its potential for broader application in low-resource scenarios. \footnote{The code and data are released on https://github.com/UESTC-GQJ/TKRE.
Exploring Heterogeneous Information Networks via Pre-Training
Jul 07, 2020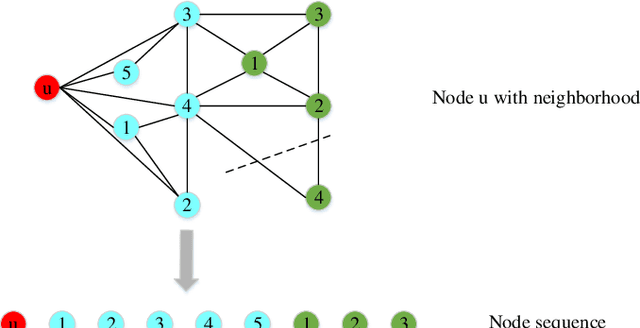
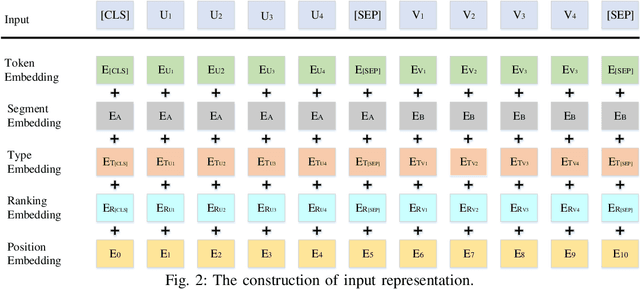
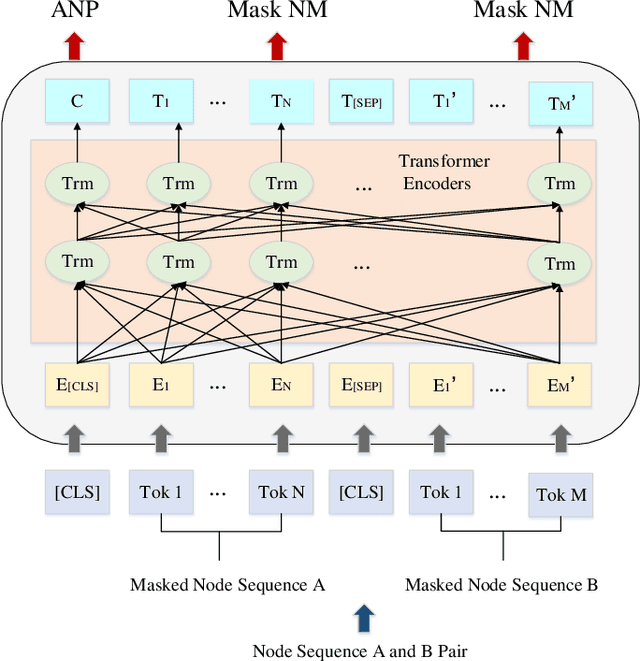
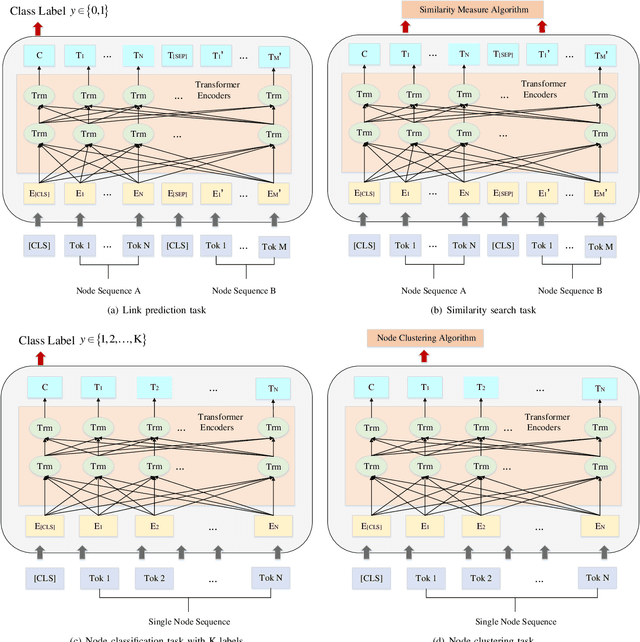
To explore heterogeneous information networks (HINs), network representation learning (NRL) is proposed, which represents a network in a low-dimension space. Recently, graph neural networks (GNNs) have drawn a lot of attention which are very expressive for mining a HIN, while they suffer from low efficiency issue. In this paper, we propose a pre-training and fine-tuning framework PF-HIN to capture the features of a HIN. Unlike traditional GNNs that have to train the whole model for each downstream task, PF-HIN only needs to fine-tune the model using the pre-trained parameters and minimal extra task-specific parameters, thus improving the model efficiency and effectiveness. Specifically, in pre-training phase, we first use a ranking-based BFS strategy to form the input node sequence. Then inspired by BERT, we adopt deep bi-directional transformer encoders to train the model, which is a variant of GNN aggregator that is more powerful than traditional deep neural networks like CNN and LSTM. The model is pre-trained based on two tasks, i.e., masked node modeling (MNM) and adjacent node prediction (ANP). Additionally, we leverage factorized embedding parameterization and cross-layer parameter sharing to reduce the parameters. In fine-tuning stage, we choose four benchmark downstream tasks, i.e., link prediction, similarity search, node classification and node clustering. We use node sequence pairs as input for link prediction and similarity search, and a single node sequence as input for node classification and clustering. The experimental results of the above tasks on four real-world datasets verify the advancement of PF-HIN, as it outperforms state-of-the-art alternatives consistently and significantly.