 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCGU-ILALab at FoodBench-QA 2026: Comparing Traditional and LLM-based Approaches for Recipe Nutrient Estimation
Apr 28, 2026Accurate nutrient estimation from unstructured recipe text is an important yet challenging problem in dietary monitoring, due to ambiguous ingredient terminology and highly variable quantity expressions. We systematically evaluate models spanning a wide range of representational capacity, from lexical matching methods (TF-IDF with Ridge Regression), to deep semantic encoders (DeBERTa-v3), to generative reasoning with large language models (LLMs). Under the strict tolerance criteria defined by EU Regulation 1169/2011, our empirical results reveal a clear trade-off between predictive accuracy and computational efficiency. The TF-IDF baseline achieves moderate nutrient estimation performance with near-instantaneous inference, whereas the DeBERTa-v3 encoder performs poorly under task-specific data scarcity. In contrast, few-shot LLM inference (e.g., Gemini 2.5 Flash) and a hybrid LLM refinement pipeline (TF-IDF combined with Gemini 2.5 Flash) deliver the highest validation accuracy across all nutrient categories. These improvements likely arise from the ability of LLMs to leverage pre-trained world knowledge to resolve ambiguous terminology and normalize non-standard units, which remain difficult for purely lexical approaches. However, these gains come at the cost of substantially higher inference latency, highlighting a practical deployment trade-off between real-time efficiency and nutritional precision in dietary monitoring systems.
Knowledge Distillation with Feature Maps for Image Classification
Dec 03, 2018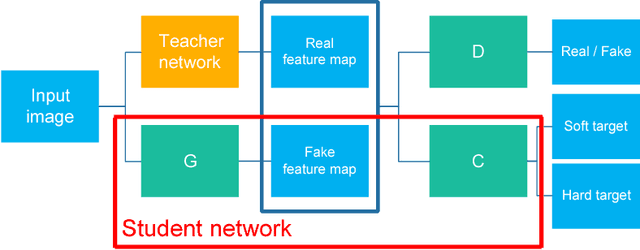
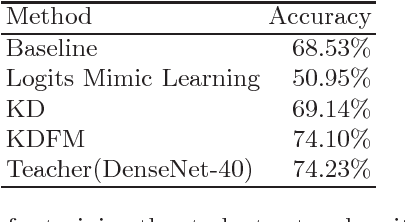

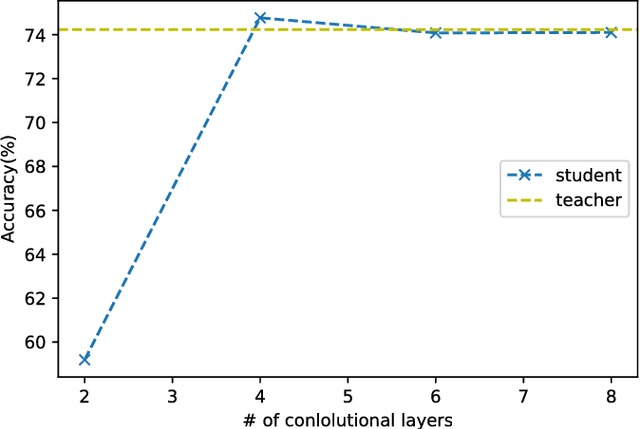
The model reduction problem that eases the computation costs and latency of complex deep learning architectures has received an increasing number of investigations owing to its importance in model deployment. One promising method is knowledge distillation (KD), which creates a fast-to-execute student model to mimic a large teacher network. In this paper, we propose a method, called KDFM (Knowledge Distillation with Feature Maps), which improves the effectiveness of KD by learning the feature maps from the teacher network. Two major techniques used in KDFM are shared classifier and generative adversarial network. Experimental results show that KDFM can use a four layers CNN to mimic DenseNet-40 and use MobileNet to mimic DenseNet-100. Both student networks have less than 1\% accuracy loss comparing to their teacher models for CIFAR-100 datasets. The student networks are 2-6 times faster than their teacher models for inference, and the model size of MobileNet is less than half of DenseNet-100's.