 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLibriheavy: a 50,000 hours ASR corpus with punctuation casing and context
Sep 15, 2023



In this paper, we introduce Libriheavy, a large-scale ASR corpus consisting of 50,000 hours of read English speech derived from LibriVox. To the best of our knowledge, Libriheavy is the largest freely-available corpus of speech with supervisions. Different from other open-sourced datasets that only provide normalized transcriptions, Libriheavy contains richer information such as punctuation, casing and text context, which brings more flexibility for system building. Specifically, we propose a general and efficient pipeline to locate, align and segment the audios in previously published Librilight to its corresponding texts. The same as Librilight, Libriheavy also has three training subsets small, medium, large of the sizes 500h, 5000h, 50000h respectively. We also extract the dev and test evaluation sets from the aligned audios and guarantee there is no overlapping speakers and books in training sets. Baseline systems are built on the popular CTC-Attention and transducer models. Additionally, we open-source our dataset creatation pipeline which can also be used to other audio alignment tasks.
A Surrogate Data Assimilation Model for the Estimation of Dynamical System in a Limited Area
Jul 14, 2023We propose a novel learning-based surrogate data assimilation (DA) model for efficient state estimation in a limited area. Our model employs a feedforward neural network for online computation, eliminating the need for integrating high-dimensional limited-area models. This approach offers significant computational advantages over traditional DA algorithms. Furthermore, our method avoids the requirement of lateral boundary conditions for the limited-area model in both online and offline computations. The design of our surrogate DA model is built upon a robust theoretical framework that leverages two fundamental concepts: observability and effective region. The concept of observability enables us to quantitatively determine the optimal amount of observation data necessary for accurate DA. Meanwhile, the concept of effective region substantially reduces the computational burden associated with computing observability and generating training data.
Delay-penalized CTC implemented based on Finite State Transducer
May 19, 2023



Connectionist Temporal Classification (CTC) suffers from the latency problem when applied to streaming models. We argue that in CTC lattice, the alignments that can access more future context are preferred during training, thereby leading to higher symbol delay. In this work we propose the delay-penalized CTC which is augmented with latency penalty regularization. We devise a flexible and efficient implementation based on the differentiable Finite State Transducer (FST). Specifically, by attaching a binary attribute to CTC topology, we can locate the frames that firstly emit non-blank tokens on the resulting CTC lattice, and add the frame offsets to the log-probabilities. Experimental results demonstrate the effectiveness of our proposed delay-penalized CTC, which is able to balance the delay-accuracy trade-off. Furthermore, combining the delay-penalized transducer enables the CTC model to achieve better performance and lower latency. Our work is open-sourced and publicly available https://github.com/k2-fsa/k2.
Blank-regularized CTC for Frame Skipping in Neural Transducer
May 19, 2023



Neural Transducer and connectionist temporal classification (CTC) are popular end-to-end automatic speech recognition systems. Due to their frame-synchronous design, blank symbols are introduced to address the length mismatch between acoustic frames and output tokens, which might bring redundant computation. Previous studies managed to accelerate the training and inference of neural Transducers by discarding frames based on the blank symbols predicted by a co-trained CTC. However, there is no guarantee that the co-trained CTC can maximize the ratio of blank symbols. This paper proposes two novel regularization methods to explicitly encourage more blanks by constraining the self-loop of non-blank symbols in the CTC. It is interesting to find that the frame reduction ratio of the neural Transducer can approach the theoretical boundary. Experiments on LibriSpeech corpus show that our proposed method accelerates the inference of neural Transducer by 4 times without sacrificing performance. Our work is open-sourced and publicly available https://github.com/k2-fsa/icefall.
Predicting Multi-Codebook Vector Quantization Indexes for Knowledge Distillation
Oct 31, 2022



Knowledge distillation(KD) is a common approach to improve model performance in automatic speech recognition (ASR), where a student model is trained to imitate the output behaviour of a teacher model. However, traditional KD methods suffer from teacher label storage issue, especially when the training corpora are large. Although on-the-fly teacher label generation tackles this issue, the training speed is significantly slower as the teacher model has to be evaluated every batch. In this paper, we reformulate the generation of teacher label as a codec problem. We propose a novel Multi-codebook Vector Quantization (MVQ) approach that compresses teacher embeddings to codebook indexes (CI). Based on this, a KD training framework (MVQ-KD) is proposed where a student model predicts the CI generated from the embeddings of a self-supervised pre-trained teacher model. Experiments on the LibriSpeech clean-100 hour show that MVQ-KD framework achieves comparable performance as traditional KD methods (l1, l2), while requiring 256 times less storage. When the full LibriSpeech dataset is used, MVQ-KD framework results in 13.8% and 8.2% relative word error rate reductions (WERRs) for non -streaming transducer on test-clean and test-other and 4.0% and 4.9% for streaming transducer. The implementation of this work is already released as a part of the open-source project icefall.
Fast and parallel decoding for transducer
Oct 31, 2022The transducer architecture is becoming increasingly popular in the field of speech recognition, because it is naturally streaming as well as high in accuracy. One of the drawbacks of transducer is that it is difficult to decode in a fast and parallel way due to an unconstrained number of symbols that can be emitted per time step. In this work, we introduce a constrained version of transducer loss to learn strictly monotonic alignments between the sequences; we also improve the standard greedy search and beam search algorithms by limiting the number of symbols that can be emitted per time step in transducer decoding, making it more efficient to decode in parallel with batches. Furthermore, we propose an finite state automaton-based (FSA) parallel beam search algorithm that can run with graphs on GPU efficiently. The experiment results show that we achieve slight word error rate (WER) improvement as well as significant speedup in decoding. Our work is open-sourced and publicly available\footnote{https://github.com/k2-fsa/icefall}.
Delay-penalized transducer for low-latency streaming ASR
Oct 31, 2022In streaming automatic speech recognition (ASR), it is desirable to reduce latency as much as possible while having minimum impact on recognition accuracy. Although a few existing methods are able to achieve this goal, they are difficult to implement due to their dependency on external alignments. In this paper, we propose a simple way to penalize symbol delay in transducer model, so that we can balance the trade-off between symbol delay and accuracy for streaming models without external alignments. Specifically, our method adds a small constant times (T/2 - t), where T is the number of frames and t is the current frame, to all the non-blank log-probabilities (after normalization) that are fed into the two dimensional transducer recursion. For both streaming Conformer models and unidirectional long short-term memory (LSTM) models, experimental results show that it can significantly reduce the symbol delay with an acceptable performance degradation. Our method achieves similar delay-accuracy trade-off to the previously published FastEmit, but we believe our method is preferable because it has a better justification: it is equivalent to penalizing the average symbol delay. Our work is open-sourced and publicly available (https://github.com/k2-fsa/k2).
Pruned RNN-T for fast, memory-efficient ASR training
Jun 23, 2022

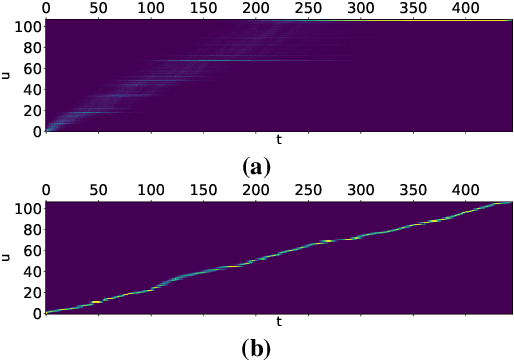
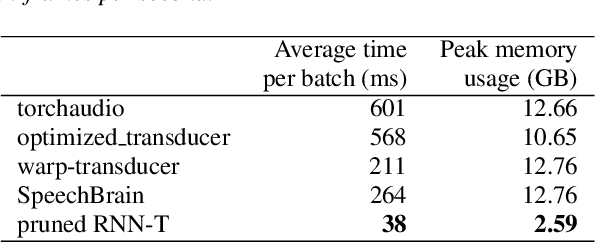
The RNN-Transducer (RNN-T) framework for speech recognition has been growing in popularity, particularly for deployed real-time ASR systems, because it combines high accuracy with naturally streaming recognition. One of the drawbacks of RNN-T is that its loss function is relatively slow to compute, and can use a lot of memory. Excessive GPU memory usage can make it impractical to use RNN-T loss in cases where the vocabulary size is large: for example, for Chinese character-based ASR. We introduce a method for faster and more memory-efficient RNN-T loss computation. We first obtain pruning bounds for the RNN-T recursion using a simple joiner network that is linear in the encoder and decoder embeddings; we can evaluate this without using much memory. We then use those pruning bounds to evaluate the full, non-linear joiner network.
Neural Network Optimal Feedback Control with Guaranteed Local Stability
May 01, 2022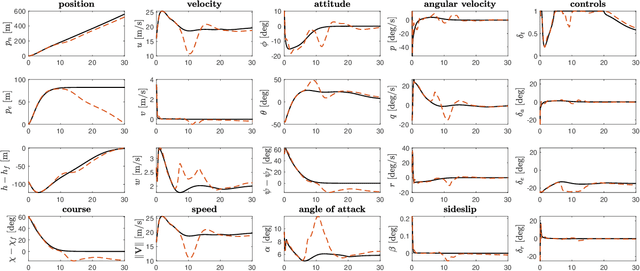
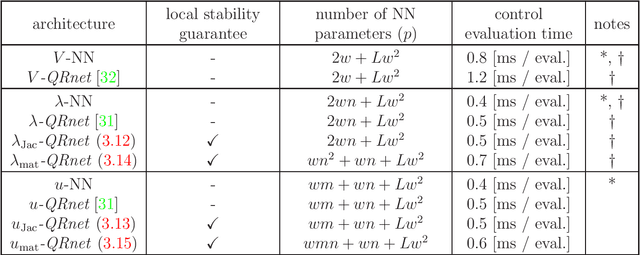
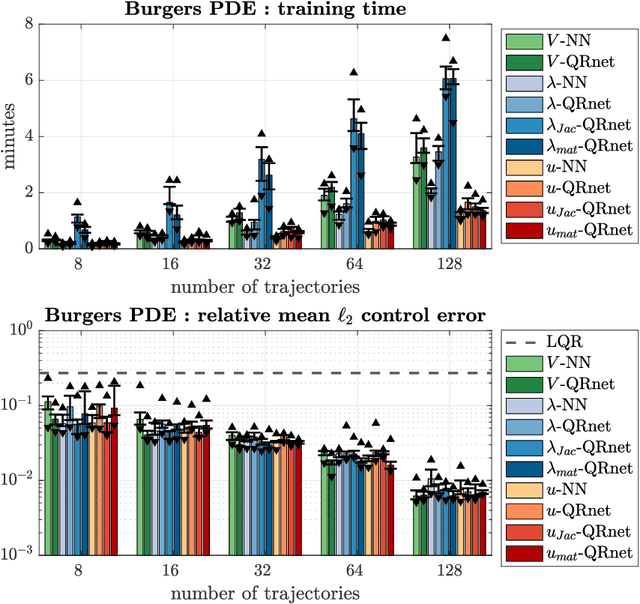
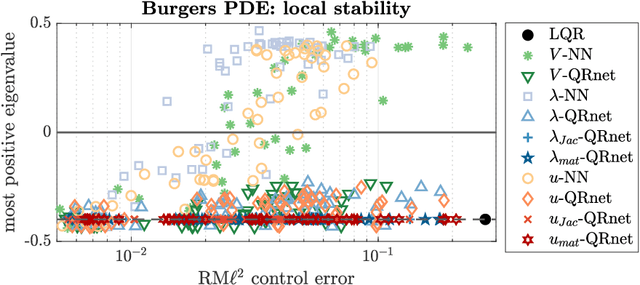
Recent research shows that deep learning can be an effective tool for designing optimal feedback controllers for high-dimensional nonlinear dynamic systems. But the behavior of these neural network (NN) controllers is still not well understood. In particular, some NNs with high test accuracy can fail to even locally stabilize the dynamic system. To address this challenge we propose several novel NN architectures, which we show guarantee local stability while retaining the semi-global approximation capacity to learn the optimal feedback policy. The proposed architectures are compared against standard NN feedback controllers through numerical simulations of two high-dimensional nonlinear optimal control problems (OCPs): stabilization of an unstable Burgers-type partial differential equation (PDE), and altitude and course tracking for a six degree-of-freedom (6DoF) unmanned aerial vehicle (UAV). The simulations demonstrate that standard NNs can fail to stabilize the dynamics even when trained well, while the proposed architectures are always at least locally stable. Moreover, the proposed controllers are found to be near-optimal in testing.
Towards A Critical Evaluation of Robustness for Deep Learning Backdoor Countermeasures
Apr 13, 2022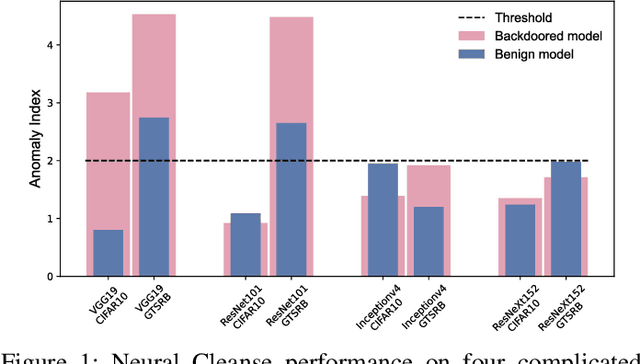
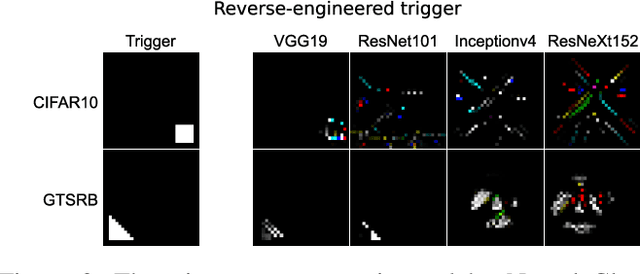
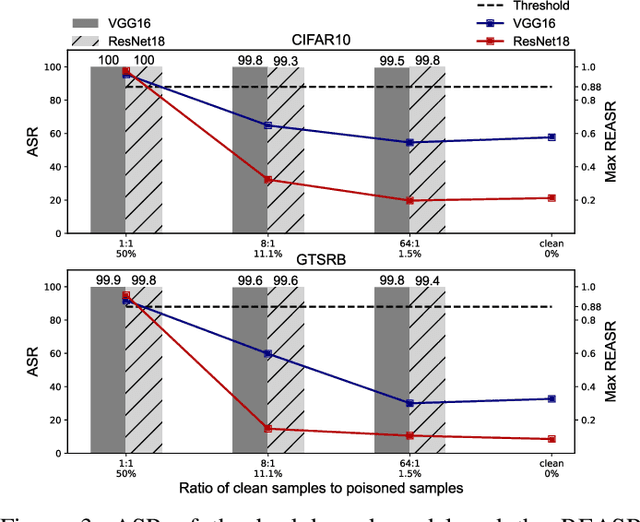

Since Deep Learning (DL) backdoor attacks have been revealed as one of the most insidious adversarial attacks, a number of countermeasures have been developed with certain assumptions defined in their respective threat models. However, the robustness of these countermeasures is inadvertently ignored, which can introduce severe consequences, e.g., a countermeasure can be misused and result in a false implication of backdoor detection. For the first time, we critically examine the robustness of existing backdoor countermeasures with an initial focus on three influential model-inspection ones that are Neural Cleanse (S&P'19), ABS (CCS'19), and MNTD (S&P'21). Although the three countermeasures claim that they work well under their respective threat models, they have inherent unexplored non-robust cases depending on factors such as given tasks, model architectures, datasets, and defense hyper-parameter, which are \textit{not even rooted from delicate adaptive attacks}. We demonstrate how to trivially bypass them aligned with their respective threat models by simply varying aforementioned factors. Particularly, for each defense, formal proofs or empirical studies are used to reveal its two non-robust cases where it is not as robust as it claims or expects, especially the recent MNTD. This work highlights the necessity of thoroughly evaluating the robustness of backdoor countermeasures to avoid their misleading security implications in unknown non-robust cases.