 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating MRI Uncertainty Estimation with Mask-based Bayesian Neural Network
Jul 07, 2024Accurate and reliable Magnetic Resonance Imaging (MRI) analysis is particularly important for adaptive radiotherapy, a recent medical advance capable of improving cancer diagnosis and treatment. Recent studies have shown that IVIM-NET, a deep neural network (DNN), can achieve high accuracy in MRI analysis, indicating the potential of deep learning to enhance diagnostic capabilities in healthcare. However, IVIM-NET does not provide calibrated uncertainty information needed for reliable and trustworthy predictions in healthcare. Moreover, the expensive computation and memory demands of IVIM-NET reduce hardware performance, hindering widespread adoption in realistic scenarios. To address these challenges, this paper proposes an algorithm-hardware co-optimization flow for high-performance and reliable MRI analysis. At the algorithm level, a transformation design flow is introduced to convert IVIM-NET to a mask-based Bayesian Neural Network (BayesNN), facilitating reliable and efficient uncertainty estimation. At the hardware level, we propose an FPGA-based accelerator with several hardware optimizations, such as mask-zero skipping and operation reordering. Experimental results demonstrate that our co-design approach can satisfy the uncertainty requirements of MRI analysis, while achieving 7.5 times and 32.5 times speedup on an Xilinx VU13P FPGA compared to GPU and CPU implementations with reduced power consumption.
Exploring FPGA designs for MX and beyond
Jul 01, 2024



A number of companies recently worked together to release the new Open Compute Project MX standard for low-precision computation, aimed at efficient neural network implementation. In this paper, we describe and evaluate the first open-source FPGA implementation of the arithmetic defined in the standard. Our designs fully support all the standard's concrete formats for conversion into and out of MX formats and for the standard-defined arithmetic operations, as well as arbitrary fixed-point and floating-point formats. Certain elements of the standard are left as implementation-defined, and we present the first concrete FPGA-inspired choices for these elements, which we outline in the paper. Our library of optimized hardware components is available open source, and can be used to build larger systems. For this purpose, we also describe and release an open-source Pytorch library for quantization into the new standard, integrated with the Brevitas library so that the community can develop novel neural network designs quantized with MX formats in mind. We demonstrate the usability and efficacy of our libraries via the implementation of example neural networks such as ResNet-18 on the ImageNet ILSVRC12 dataset. Our testing shows that MX is very effective for formats such as INT5 or FP6 which are not natively supported on GPUs. This gives FPGAs an advantage as they have the flexibility to implement a custom datapath and take advantage of the smaller area footprints offered by these formats.
Enhancing Dropout-based Bayesian Neural Networks with Multi-Exit on FPGA
Jun 24, 2024Reliable uncertainty estimation plays a crucial role in various safety-critical applications such as medical diagnosis and autonomous driving. In recent years, Bayesian neural networks (BayesNNs) have gained substantial research and industrial interests due to their capability to make accurate predictions with reliable uncertainty estimation. However, the algorithmic complexity and the resulting hardware performance of BayesNNs hinder their adoption in real-life applications. To bridge this gap, this paper proposes an algorithm and hardware co-design framework that can generate field-programmable gate array (FPGA)-based accelerators for efficient BayesNNs. At the algorithm level, we propose novel multi-exit dropout-based BayesNNs with reduced computational and memory overheads while achieving high accuracy and quality of uncertainty estimation. At the hardware level, this paper introduces a transformation framework that can generate FPGA-based accelerators for the proposed efficient multi-exit BayesNNs. Several optimization techniques such as the mix of spatial and temporal mappings are introduced to reduce resource consumption and improve the overall hardware performance. Comprehensive experiments demonstrate that our approach can achieve higher energy efficiency compared to CPU, GPU, and other state-of-the-art hardware implementations. To support the future development of this research, we have open-sourced our code at: https://github.com/os-hxfan/MCME_FPGA_Acc.git
Hardware-Aware Neural Dropout Search for Reliable Uncertainty Prediction on FPGA
Jun 23, 2024



The increasing deployment of artificial intelligence (AI) for critical decision-making amplifies the necessity for trustworthy AI, where uncertainty estimation plays a pivotal role in ensuring trustworthiness. Dropout-based Bayesian Neural Networks (BayesNNs) are prominent in this field, offering reliable uncertainty estimates. Despite their effectiveness, existing dropout-based BayesNNs typically employ a uniform dropout design across different layers, leading to suboptimal performance. Moreover, as diverse applications require tailored dropout strategies for optimal performance, manually optimizing dropout configurations for various applications is both error-prone and labor-intensive. To address these challenges, this paper proposes a novel neural dropout search framework that automatically optimizes both the dropout-based BayesNNs and their hardware implementations on FPGA. We leverage one-shot supernet training with an evolutionary algorithm for efficient dropout optimization. A layer-wise dropout search space is introduced to enable the automatic design of dropout-based BayesNNs with heterogeneous dropout configurations. Extensive experiments demonstrate that our proposed framework can effectively find design configurations on the Pareto frontier. Compared to manually-designed dropout-based BayesNNs on GPU, our search approach produces FPGA designs that can achieve up to 33X higher energy efficiency. Compared to state-of-the-art FPGA designs of BayesNN, the solutions from our approach can achieve higher algorithmic performance and energy efficiency.
Hardware-Aware Parallel Prompt Decoding for Memory-Efficient Acceleration of LLM Inference
May 28, 2024



The auto-regressive decoding of Large Language Models (LLMs) results in significant overheads in their hardware performance. While recent research has investigated various speculative decoding techniques for multi-token generation, these efforts have primarily focused on improving processing speed such as throughput. Crucially, they often neglect other metrics essential for real-life deployments, such as memory consumption and training cost. To overcome these limitations, we propose a novel parallel prompt decoding that requires only $0.0002$% trainable parameters, enabling efficient training on a single A100-40GB GPU in just 16 hours. Inspired by the human natural language generation process, $PPD$ approximates outputs generated at future timesteps in parallel by using multiple prompt tokens. This approach partially recovers the missing conditional dependency information necessary for multi-token generation, resulting in up to a 28% higher acceptance rate for long-range predictions. Furthermore, we present a hardware-aware dynamic sparse tree technique that adaptively optimizes this decoding scheme to fully leverage the computational capacities on different GPUs. Through extensive experiments across LLMs ranging from MobileLlama to Vicuna-13B on a wide range of benchmarks, our approach demonstrates up to 2.49$\times$ speedup and maintains a minimal runtime memory overhead of just $0.0004$%. More importantly, our parallel prompt decoding can serve as an orthogonal optimization for synergistic integration with existing speculative decoding, showing up to $1.22\times$ further speed improvement. Our code is available at https://github.com/hmarkc/parallel-prompt-decoding.
Sets are all you need: Ultrafast jet classification on FPGAs for HL-LHC
Feb 02, 2024



We study various machine learning based algorithms for performing accurate jet flavor classification on field-programmable gate arrays and demonstrate how latency and resource consumption scale with the input size and choice of algorithm. These architectures provide an initial design for models that could be used for tagging at the CERN LHC during its high-luminosity phase. The high-luminosity upgrade will lead to a five-fold increase in its instantaneous luminosity for proton-proton collisions and, in turn, higher data volume and complexity, such as the availability of jet constituents. Through quantization-aware training and efficient hardware implementations, we show that O(100) ns inference of complex architectures such as deep sets and interaction networks is feasible at a low computational resource cost.
When Monte-Carlo Dropout Meets Multi-Exit: Optimizing Bayesian Neural Networks on FPGA
Aug 13, 2023Bayesian Neural Networks (BayesNNs) have demonstrated their capability of providing calibrated prediction for safety-critical applications such as medical imaging and autonomous driving. However, the high algorithmic complexity and the poor hardware performance of BayesNNs hinder their deployment in real-life applications. To bridge this gap, this paper proposes a novel multi-exit Monte-Carlo Dropout (MCD)-based BayesNN that achieves well-calibrated predictions with low algorithmic complexity. To further reduce the barrier to adopting BayesNNs, we propose a transformation framework that can generate FPGA-based accelerators for multi-exit MCD-based BayesNNs. Several novel optimization techniques are introduced to improve hardware performance. Our experiments demonstrate that our auto-generated accelerator achieves higher energy efficiency than CPU, GPU, and other state-of-the-art hardware implementations.
MetaML: Automating Customizable Cross-Stage Design-Flow for Deep Learning Acceleration
Jun 14, 2023This paper introduces a novel optimization framework for deep neural network (DNN) hardware accelerators, enabling the rapid development of customized and automated design flows. More specifically, our approach aims to automate the selection and configuration of low-level optimization techniques, encompassing DNN and FPGA low-level optimizations. We introduce novel optimization and transformation tasks for building design-flow architectures, which are highly customizable and flexible, thereby enhancing the performance and efficiency of DNN accelerators. Our results demonstrate considerable reductions of up to 92\% in DSP usage and 89\% in LUT usage for two networks, while maintaining accuracy and eliminating the need for human effort or domain expertise. In comparison to state-of-the-art approaches, our design achieves higher accuracy and utilizes three times fewer DSP resources, underscoring the advantages of our proposed framework.
LL-GNN: Low Latency Graph Neural Networks on FPGAs for Particle Detectors
Oct 11, 2022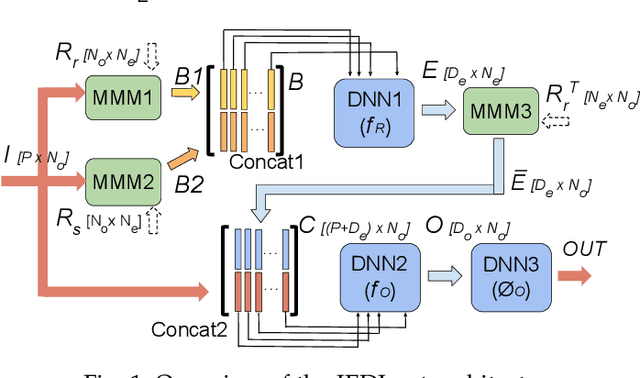
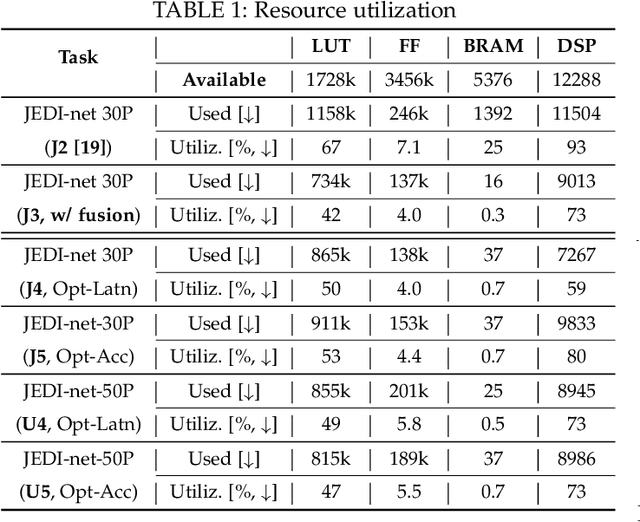
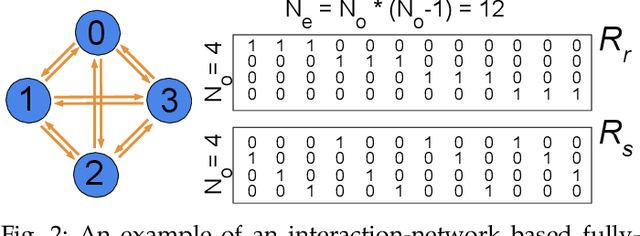
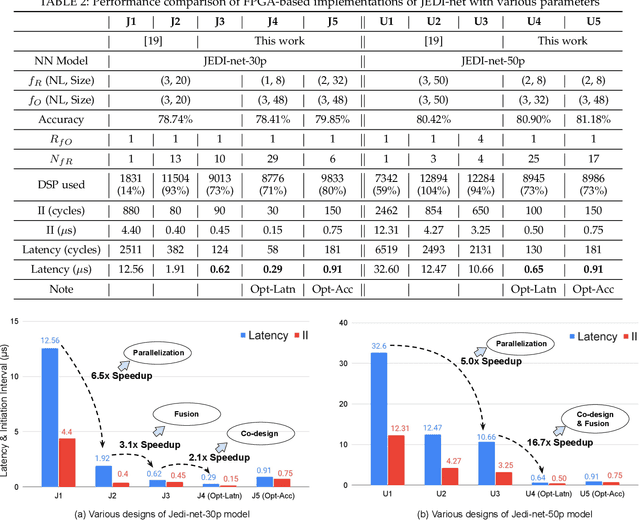
This work proposes a novel reconfigurable architecture for low latency Graph Neural Network (GNN) design specifically for particle detectors. Adopting FPGA-based GNNs for particle detectors is challenging since it requires sub-microsecond latency to deploy the networks for online event selection in the Level-1 triggers for the CERN Large Hadron Collider experiments. This paper proposes a custom code transformation with strength reduction for the matrix multiplication operations in the interaction-network based GNNs with fully connected graphs, which avoids the costly multiplication. It exploits sparsity patterns as well as binary adjacency matrices, and avoids irregular memory access, leading to a reduction in latency and improvement in hardware efficiency. In addition, we introduce an outer-product based matrix multiplication approach which is enhanced by the strength reduction for low latency design. Also, a fusion step is introduced to further reduce the design latency. Furthermore, an GNN-specific algorithm-hardware co-design approach is presented which not only finds a design with a much better latency but also finds a high accuracy design under a given latency constraint. Finally, a customizable template for this low latency GNN hardware architecture has been designed and open-sourced, which enables the generation of low-latency FPGA designs with efficient resource utilization using a high-level synthesis tool. Evaluation results show that our FPGA implementation is up to 24 times faster and consumes up to 45 times less power than a GPU implementation. Compared to our previous FPGA implementations, this work achieves 6.51 to 16.7 times lower latency. Moreover, the latency of our FPGA design is sufficiently low to enable deployment of GNNs in a sub-microsecond, real-time collider trigger system, enabling it to benefit from improved accuracy.
Adaptable Butterfly Accelerator for Attention-based NNs via Hardware and Algorithm Co-design
Sep 20, 2022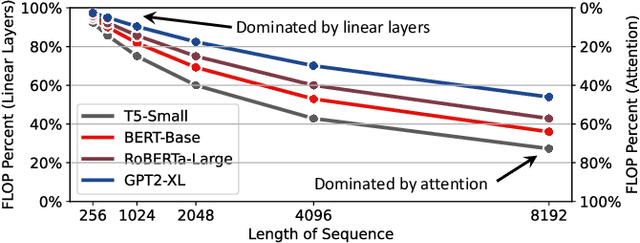
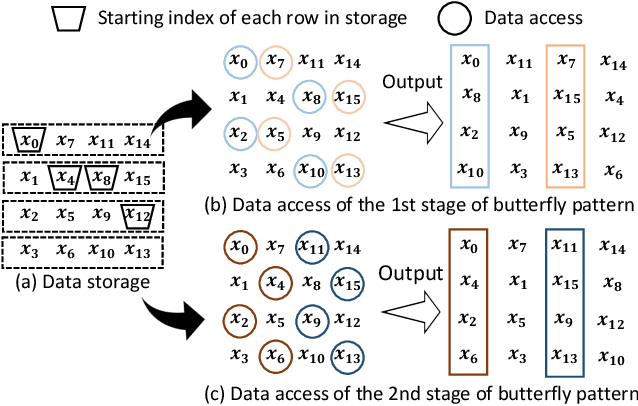
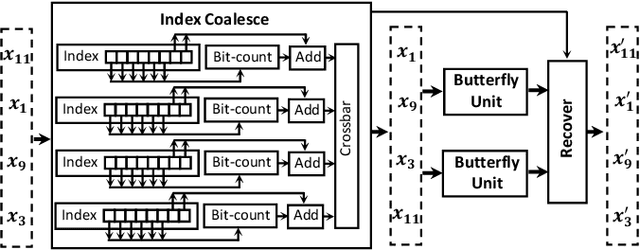
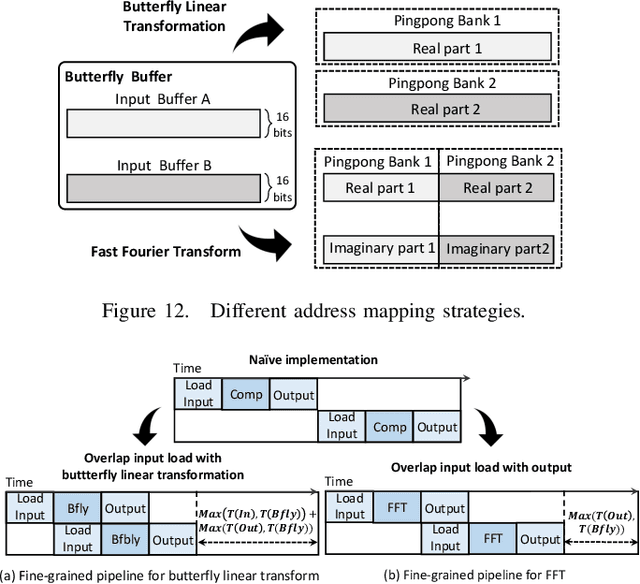
Attention-based neural networks have become pervasive in many AI tasks. Despite their excellent algorithmic performance, the use of the attention mechanism and feed-forward network (FFN) demands excessive computational and memory resources, which often compromises their hardware performance. Although various sparse variants have been introduced, most approaches only focus on mitigating the quadratic scaling of attention on the algorithm level, without explicitly considering the efficiency of mapping their methods on real hardware designs. Furthermore, most efforts only focus on either the attention mechanism or the FFNs but without jointly optimizing both parts, causing most of the current designs to lack scalability when dealing with different input lengths. This paper systematically considers the sparsity patterns in different variants from a hardware perspective. On the algorithmic level, we propose FABNet, a hardware-friendly variant that adopts a unified butterfly sparsity pattern to approximate both the attention mechanism and the FFNs. On the hardware level, a novel adaptable butterfly accelerator is proposed that can be configured at runtime via dedicated hardware control to accelerate different butterfly layers using a single unified hardware engine. On the Long-Range-Arena dataset, FABNet achieves the same accuracy as the vanilla Transformer while reducing the amount of computation by 10 to 66 times and the number of parameters 2 to 22 times. By jointly optimizing the algorithm and hardware, our FPGA-based butterfly accelerator achieves 14.2 to 23.2 times speedup over state-of-the-art accelerators normalized to the same computational budget. Compared with optimized CPU and GPU designs on Raspberry Pi 4 and Jetson Nano, our system is up to 273.8 and 15.1 times faster under the same power budget.