 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Embedding of Semantic Similarity in Control Policies via Entangled Bisimulation
Jan 28, 2022



Learning generalizeable policies from visual input in the presence of visual distractions is a challenging problem in reinforcement learning. Recently, there has been renewed interest in bisimulation metrics as a tool to address this issue; these metrics can be used to learn representations that are, in principle, invariant to irrelevant distractions by measuring behavioural similarity between states. An accurate, unbiased, and scalable estimation of these metrics has proved elusive in continuous state and action scenarios. We propose entangled bisimulation, a bisimulation metric that allows the specification of the distance function between states, and can be estimated without bias in continuous state and action spaces. We show how entangled bisimulation can meaningfully improve over previous methods on the Distracting Control Suite (DCS), even when added on top of data augmentation techniques.
Robust Robotic Control from Pixels using Contrastive Recurrent State-Space Models
Dec 02, 2021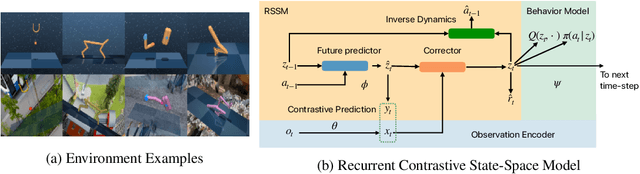
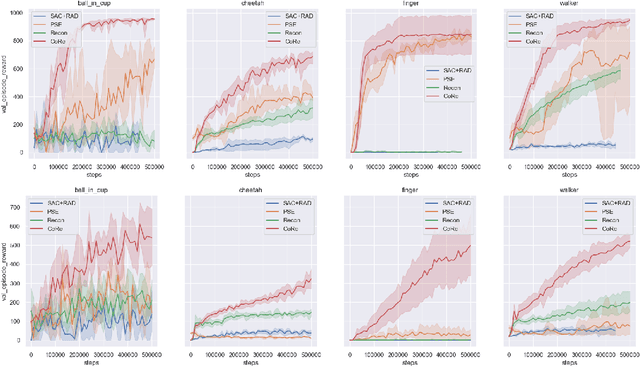
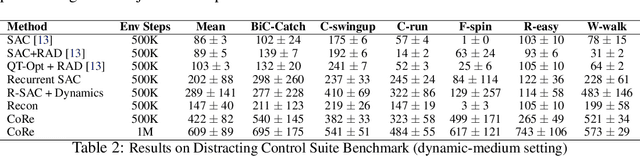
Modeling the world can benefit robot learning by providing a rich training signal for shaping an agent's latent state space. However, learning world models in unconstrained environments over high-dimensional observation spaces such as images is challenging. One source of difficulty is the presence of irrelevant but hard-to-model background distractions, and unimportant visual details of task-relevant entities. We address this issue by learning a recurrent latent dynamics model which contrastively predicts the next observation. This simple model leads to surprisingly robust robotic control even with simultaneous camera, background, and color distractions. We outperform alternatives such as bisimulation methods which impose state-similarity measures derived from divergence in future reward or future optimal actions. We obtain state-of-the-art results on the Distracting Control Suite, a challenging benchmark for pixel-based robotic control.
Regularized Training of Nearest Neighbor Language Models
Sep 16, 2021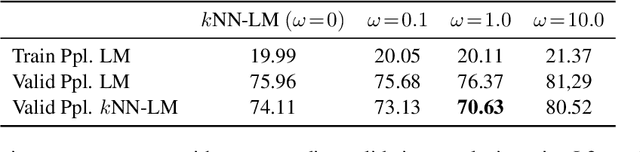
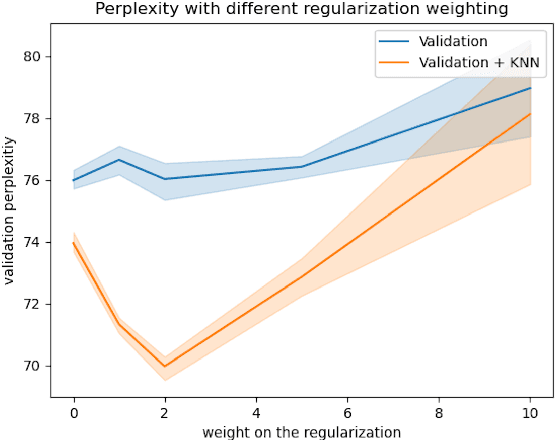

Including memory banks in a natural language processing architecture increases model capacity by equipping it with additional data at inference time. In this paper, we build upon $k$NN-LM \citep{khandelwal20generalization}, which uses a pre-trained language model together with an exhaustive $k$NN search through the training data (memory bank) to achieve state-of-the-art results. We investigate whether we can improve the $k$NN-LM performance by instead training a LM with the knowledge that we will be using a $k$NN post-hoc. We achieved significant improvement using our method on language modeling tasks on \texttt{WIKI-2} and \texttt{WIKI-103}. The main phenomenon that we encounter is that adding a simple L2 regularization on the activations (not weights) of the model, a transformer, improves the post-hoc $k$NN classification performance. We explore some possible reasons for this improvement. In particular, we find that the added L2 regularization seems to improve the performance for high-frequency words without deteriorating the performance for low frequency ones.
An Attention Free Transformer
May 28, 2021

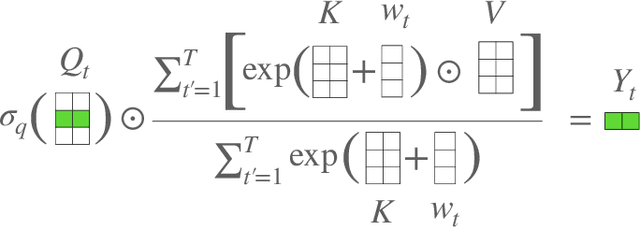
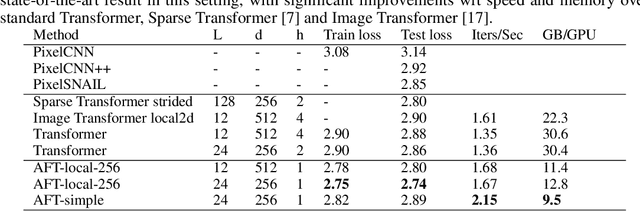
We introduce Attention Free Transformer (AFT), an efficient variant of Transformers that eliminates the need for dot product self attention. In an AFT layer, the key and value are first combined with a set of learned position biases, the result of which is multiplied with the query in an element-wise fashion. This new operation has a memory complexity linear w.r.t. both the context size and the dimension of features, making it compatible to both large input and model sizes. We also introduce AFT-local and AFT-conv, two model variants that take advantage of the idea of locality and spatial weight sharing while maintaining global connectivity. We conduct extensive experiments on two autoregressive modeling tasks (CIFAR10 and Enwik8) as well as an image recognition task (ImageNet-1K classification). We show that AFT demonstrates competitive performance on all the benchmarks, while providing excellent efficiency at the same time.
On the generalization of learning-based 3D reconstruction
Jun 27, 2020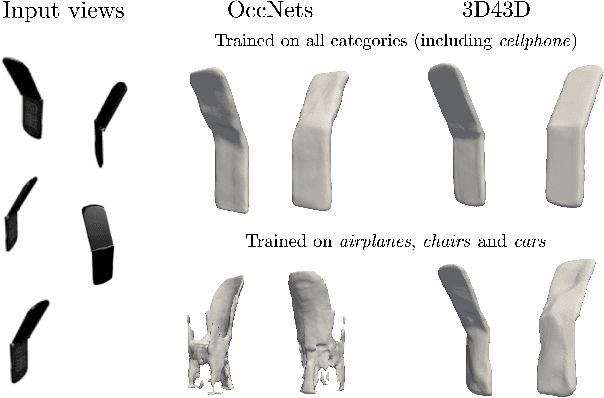


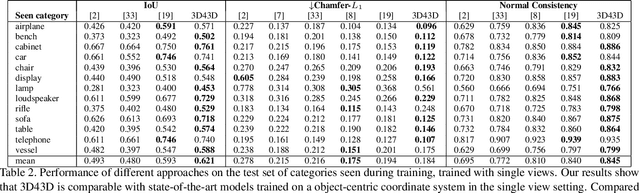
State-of-the-art learning-based monocular 3D reconstruction methods learn priors over object categories on the training set, and as a result struggle to achieve reasonable generalization to object categories unseen during training. In this paper we study the inductive biases encoded in the model architecture that impact the generalization of learning-based 3D reconstruction methods. We find that 3 inductive biases impact performance: the spatial extent of the encoder, the use of the underlying geometry of the scene to describe point features, and the mechanism to aggregate information from multiple views. Additionally, we propose mechanisms to enforce those inductive biases: a point representation that is aware of camera position, and a variance cost to aggregate information across views. Our model achieves state-of-the-art results on the standard ShapeNet 3D reconstruction benchmark in various settings.
Set Distribution Networks: a Generative Model for Sets of Images
Jun 18, 2020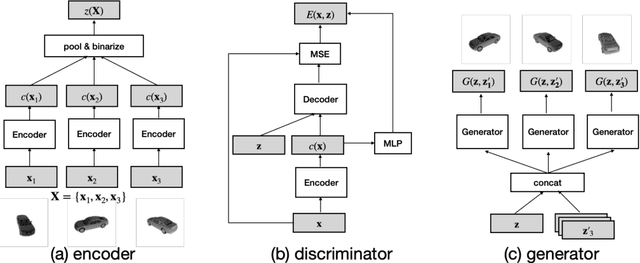
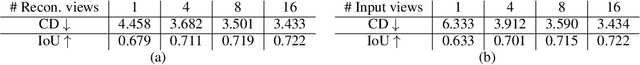


Images with shared characteristics naturally form sets. For example, in a face verification benchmark, images of the same identity form sets. For generative models, the standard way of dealing with sets is to represent each as a one hot vector, and learn a conditional generative model $p(\mathbf{x}|\mathbf{y})$. This representation assumes that the number of sets is limited and known, such that the distribution over sets reduces to a simple multinomial distribution. In contrast, we study a more generic problem where the number of sets is large and unknown. We introduce Set Distribution Networks (SDNs), a novel framework that learns to autoencode and freely generate sets. We achieve this by jointly learning a set encoder, set discriminator, set generator, and set prior. We show that SDNs are able to reconstruct image sets that preserve salient attributes of the inputs in our benchmark datasets, and are also able to generate novel objects/identities. We examine the sets generated by SDN with a pre-trained 3D reconstruction network and a face verification network, respectively, as a novel way to evaluate the quality of generated sets of images.
Adversarial Fisher Vectors for Unsupervised Representation Learning
Oct 29, 2019
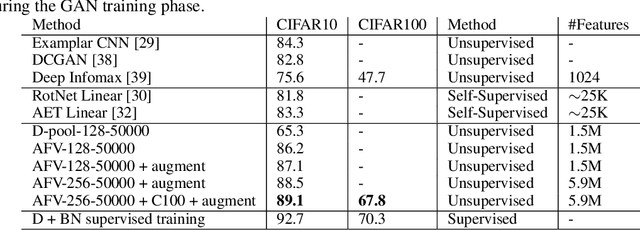
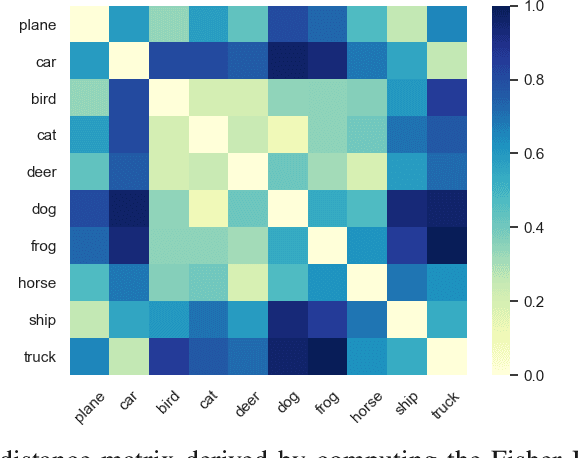
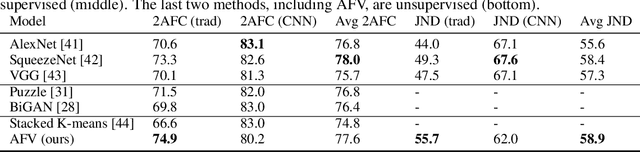
We examine Generative Adversarial Networks (GANs) through the lens of deep Energy Based Models (EBMs), with the goal of exploiting the density model that follows from this formulation. In contrast to a traditional view where the discriminator learns a constant function when reaching convergence, here we show that it can provide useful information for downstream tasks, e.g., feature extraction for classification. To be concrete, in the EBM formulation, the discriminator learns an unnormalized density function (i.e., the negative energy term) that characterizes the data manifold. We propose to evaluate both the generator and the discriminator by deriving corresponding Fisher Score and Fisher Information from the EBM. We show that by assuming that the generated examples form an estimate of the learned density, both the Fisher Information and the normalized Fisher Vectors are easy to compute. We also show that we are able to derive a distance metric between examples and between sets of examples. We conduct experiments showing that the GAN-induced Fisher Vectors demonstrate competitive performance as unsupervised feature extractors for classification and perceptual similarity tasks. Code is available at \url{https://github.com/apple/ml-afv}.
Addressing the Loss-Metric Mismatch with Adaptive Loss Alignment
May 15, 2019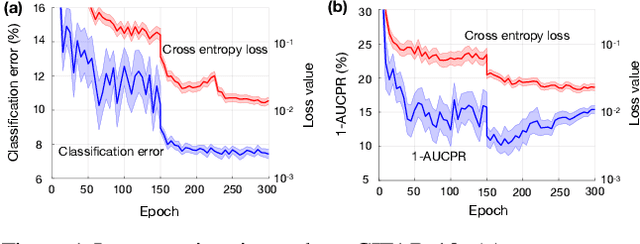
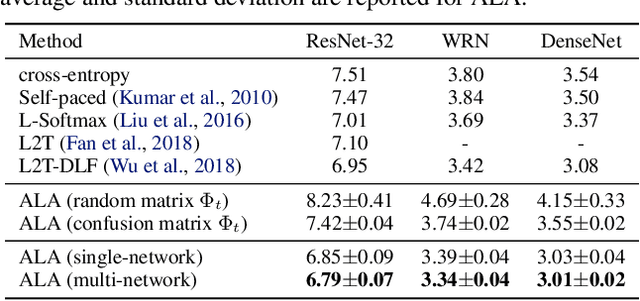
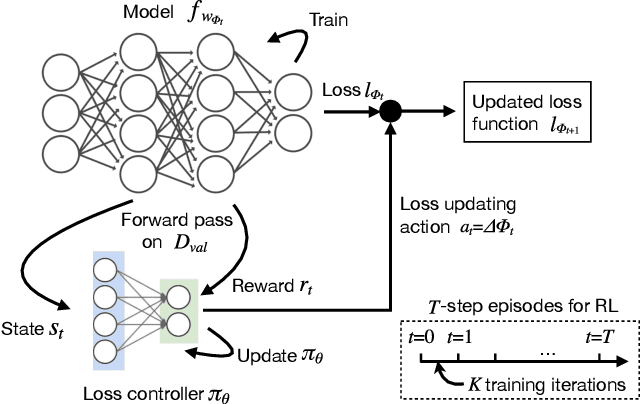

In most machine learning training paradigms a fixed, often handcrafted, loss function is assumed to be a good proxy for an underlying evaluation metric. In this work we assess this assumption by meta-learning an adaptive loss function to directly optimize the evaluation metric. We propose a sample efficient reinforcement learning approach for adapting the loss dynamically during training. We empirically show how this formulation improves performance by simultaneously optimizing the evaluation metric and smoothing the loss landscape. We verify our method in metric learning and classification scenarios, showing considerable improvements over the state-of-the-art on a diverse set of tasks. Importantly, our method is applicable to a wide range of loss functions and evaluation metrics. Furthermore, the learned policies are transferable across tasks and data, demonstrating the versatility of the method.