 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeETT: Expanding the Long Context Understanding Capability of LLMs at Test-Time
Jul 08, 2025Transformer-based Language Models' computation and memory overhead increase quadratically as a function of sequence length. The quadratic cost poses challenges when employing LLMs for processing long sequences. In this work, we introduce \ourmodelacronym~(Extend at Test-Time), method for extending the context length of short context Transformer-based LLMs, with constant memory requirement and linear computation overhead. ETT enable the extension of the context length at test-time by efficient fine-tuning the model's parameters on the input context, chunked into overlapping small subsequences. We evaluate ETT on LongBench by extending the context length of GPT-Large and Phi-2 up to 32 times, increasing from 1k to 32k tokens. This results in up to a 30 percent improvement in the model's accuracy. We also study how context can be stored in LLM's weights effectively and efficiently. Through a detailed ablation study, we examine which Transformer modules are most beneficial to fine-tune at test-time. Interestingly, we find that fine-tuning the second layer of the FFNs is more effective than full fine-tuning, leading to a further improvement in the models' accuracy.
ChemBERTa-2: Towards Chemical Foundation Models
Sep 05, 2022
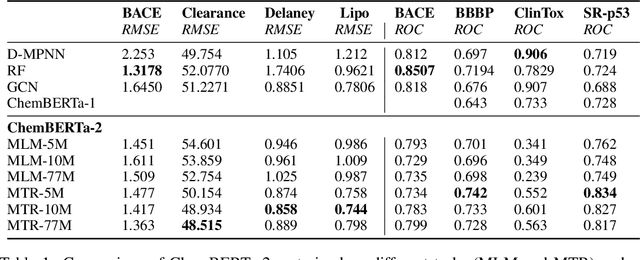
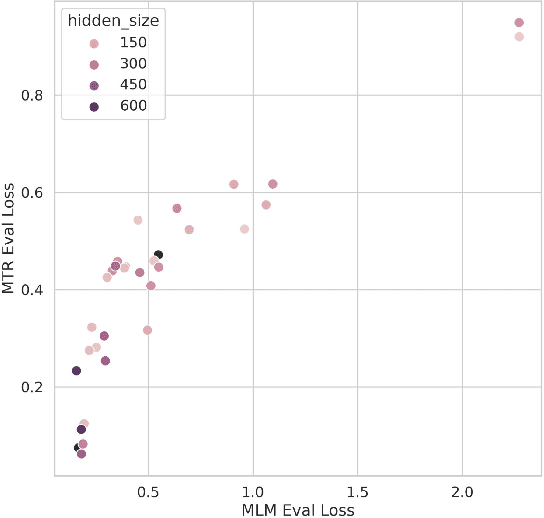
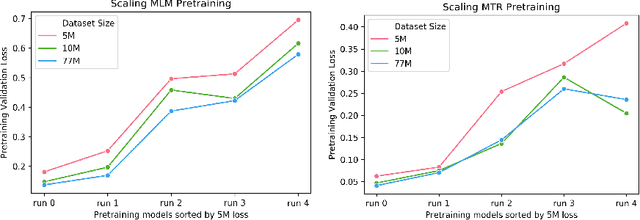
Large pretrained models such as GPT-3 have had tremendous impact on modern natural language processing by leveraging self-supervised learning to learn salient representations that can be used to readily finetune on a wide variety of downstream tasks. We investigate the possibility of transferring such advances to molecular machine learning by building a chemical foundation model, ChemBERTa-2, using the language of SMILES. While labeled data for molecular prediction tasks is typically scarce, libraries of SMILES strings are readily available. In this work, we build upon ChemBERTa by optimizing the pretraining process. We compare multi-task and self-supervised pretraining by varying hyperparameters and pretraining dataset size, up to 77M compounds from PubChem. To our knowledge, the 77M set constitutes one of the largest datasets used for molecular pretraining to date. We find that with these pretraining improvements, we are competitive with existing state-of-the-art architectures on the MoleculeNet benchmark suite. We analyze the degree to which improvements in pretraining translate to improvement on downstream tasks.