 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Burden Data Augmentation for Dysarthric ASR via Zero-Shot Voice Cloning
Jun 18, 2026Automatic speech recognition remains unreliable for dysarthric speech due to data scarcity and high inter-speaker variability. While synthetic data can address these gaps, traditional methods often require extensive speaker-specific data, reintroducing the collection bottleneck. We investigate zero-shot voice cloning as a low-burden augmentation strategy, using Higgs Audio V2 to clone speakers in the TORGO dataset. We fine-tune (FT) Whisper-medium on cloned, real, and hybrid data and evaluate on held-out real speech. Compared to the zero-shot (31.62%), Clone FT achieved a competitive 26.00% WER, nearly matching the 24.44% and 25.12% seen with Real and Hybrid FT, respectively. Notably, Clone and Hybrid FT outperform Real FT for moderate-severe speakers. Clone FT achieves the best results (11.45% relative) in cross-corpus evaluation on the SAP-1102. These results suggest that zero-shot cloning provides scalable training data that circumvents the costly data collection bottleneck.
Class-Incremental Learning for Honey Botanical Origin Classification with Hyperspectral Images: A Study with Continual Backpropagation
Jun 12, 2025Honey is an important commodity in the global market. Honey types of different botanical origins provide diversified flavors and health benefits, thus having different market values. Developing accurate and effective botanical origin-distinguishing techniques is crucial to protect consumers' interests. However, it is impractical to collect all the varieties of honey products at once to train a model for botanical origin differentiation. Therefore, researchers developed class-incremental learning (CIL) techniques to address this challenge. This study examined and compared multiple CIL algorithms on a real-world honey hyperspectral imaging dataset. A novel technique is also proposed to improve the performance of class-incremental learning algorithms by combining with a continual backpropagation (CB) algorithm. The CB method addresses the issue of loss-of-plasticity by reinitializing a proportion of less-used hidden neurons to inject variability into neural networks. Experiments showed that CB improved the performance of most CIL methods by 1-7\%.
Transformers Meet Hyperspectral Imaging: A Comprehensive Study of Models, Challenges and Open Problems
Jun 10, 2025Transformers have become the architecture of choice for learning long-range dependencies, yet their adoption in hyperspectral imaging (HSI) is still emerging. We reviewed more than 300 papers published up to 2025 and present the first end-to-end survey dedicated to Transformer-based HSI classification. The study categorizes every stage of a typical pipeline-pre-processing, patch or pixel tokenization, positional encoding, spatial-spectral feature extraction, multi-head self-attention variants, skip connections, and loss design-and contrasts alternative design choices with the unique spatial-spectral properties of HSI. We map the field's progress against persistent obstacles: scarce labeled data, extreme spectral dimensionality, computational overhead, and limited model explainability. Finally, we outline a research agenda prioritizing valuable public data sets, lightweight on-edge models, illumination and sensor shifts robustness, and intrinsically interpretable attention mechanisms. Our goal is to guide researchers in selecting, combining, or extending Transformer components that are truly fit for purpose for next-generation HSI applications.
Robust Cross-Etiology and Speaker-Independent Dysarthric Speech Recognition
Jan 25, 2025



In this paper, we present a speaker-independent dysarthric speech recognition system, with a focus on evaluating the recently released Speech Accessibility Project (SAP-1005) dataset, which includes speech data from individuals with Parkinson's disease (PD). Despite the growing body of research in dysarthric speech recognition, many existing systems are speaker-dependent and adaptive, limiting their generalizability across different speakers and etiologies. Our primary objective is to develop a robust speaker-independent model capable of accurately recognizing dysarthric speech, irrespective of the speaker. Additionally, as a secondary objective, we aim to test the cross-etiology performance of our model by evaluating it on the TORGO dataset, which contains speech samples from individuals with cerebral palsy (CP) and amyotrophic lateral sclerosis (ALS). By leveraging the Whisper model, our speaker-independent system achieved a CER of 6.99% and a WER of 10.71% on the SAP-1005 dataset. Further, in cross-etiology settings, we achieved a CER of 25.08% and a WER of 39.56% on the TORGO dataset. These results highlight the potential of our approach to generalize across unseen speakers and different etiologies of dysarthria.
Mono-Forward: Backpropagation-Free Algorithm for Efficient Neural Network Training Harnessing Local Errors
Jan 16, 2025



Backpropagation is the standard method for achieving state-of-the-art accuracy in neural network training, but it often imposes high memory costs and lacks biological plausibility. In this paper, we introduce the Mono-Forward algorithm, a purely local layerwise learning method inspired by Hinton's Forward-Forward framework. Unlike backpropagation, Mono-Forward optimizes each layer solely with locally available information, eliminating the reliance on global error signals. We evaluated Mono-Forward on multi-layer perceptrons and convolutional neural networks across multiple benchmarks, including MNIST, Fashion-MNIST, CIFAR-10, and CIFAR-100. The test results show that Mono-Forward consistently matches or surpasses the accuracy of backpropagation across all tasks, with significantly reduced and more even memory usage, better parallelizability, and a comparable convergence rate.
On filter design in deep convolutional neural network
Oct 29, 2024



The deep convolutional neural network (DCNN) in computer vision has given promising results. It is widely applied in many areas, from medicine, agriculture, self-driving car, biometric system, and almost all computer vision-based applications. Filters or weights are the critical elements responsible for learning in DCNN. Backpropagation has been the primary learning algorithm for DCNN and provides promising results, but the size and numbers of the filters remain hyper-parameters. Various studies have been done in the last decade on semi-supervised, self-supervised, and unsupervised methods and their properties. The effects of filter initialization, size-shape selection, and the number of filters on learning and optimization have not been investigated in a separate publication to collate all the options. Such attributes are often treated as hyper-parameters and lack mathematical understanding. Computer vision algorithms have many limitations in real-life applications, and understanding the learning process is essential to have some significant improvement. To the best of our knowledge, no separate investigation has been published discussing the filters; this is our primary motivation. This study focuses on arguments for choosing specific physical parameters of filters, initialization, and learning technic over scattered methods. The promising unsupervised approaches have been evaluated. Additionally, the limitations, current challenges, and future scope have been discussed in this paper.
An Efficient Framework for Automated Screening of Clinically Significant Macular Edema
Jan 20, 2020
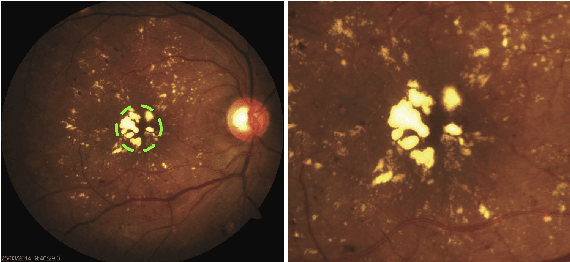
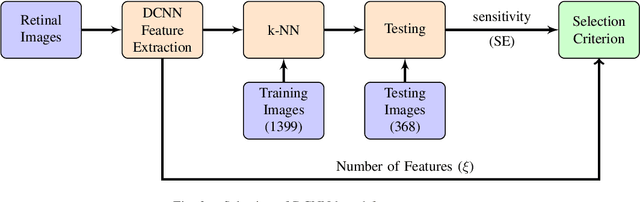
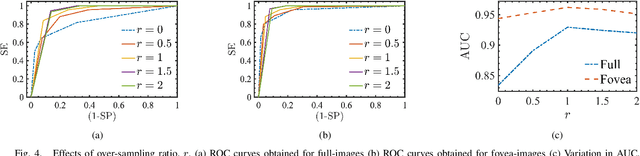
The present study proposes a new approach to automated screening of Clinically Significant Macular Edema (CSME) and addresses two major challenges associated with such screenings, i.e., exudate segmentation and imbalanced datasets. The proposed approach replaces the conventional exudate segmentation based feature extraction by combining a pre-trained deep neural network with meta-heuristic feature selection. A feature space over-sampling technique is being used to overcome the effects of skewed datasets and the screening is accomplished by a k-NN based classifier. The role of each data-processing step (e.g., class balancing, feature selection) and the effects of limiting the region-of-interest to fovea on the classification performance are critically analyzed. Finally, the selection and implication of operating point on Receiver Operating Characteristic curve are discussed. The results of this study convincingly demonstrate that by following these fundamental practices of machine learning, a basic k-NN based classifier could effectively accomplish the CSME screening.
Automatic Segmentation of Retinal Vasculature
Jul 19, 2017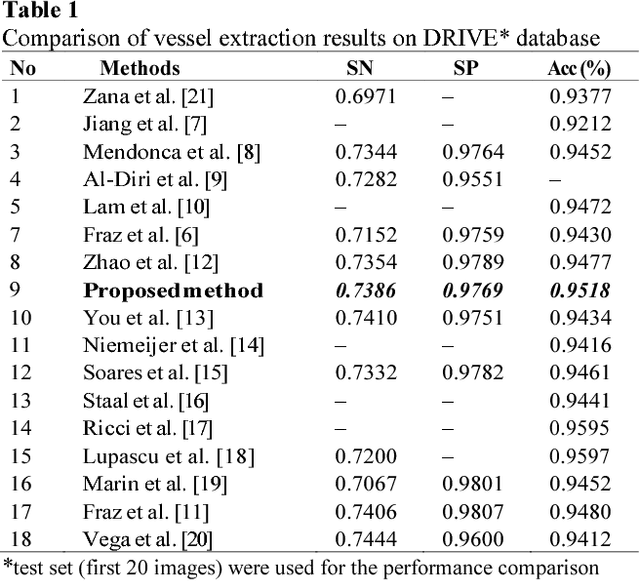
Segmentation of retinal vessels from retinal fundus images is the key step in the automatic retinal image analysis. In this paper, we propose a new unsupervised automatic method to segment the retinal vessels from retinal fundus images. Contrast enhancement and illumination correction are carried out through a series of image processing steps followed by adaptive histogram equalization and anisotropic diffusion filtering. This image is then converted to a gray scale using weighted scaling. The vessel edges are enhanced by boosting the detail curvelet coefficients. Optic disk pixels are removed before applying fuzzy C-mean classification to avoid the misclassification. Morphological operations and connected component analysis are applied to obtain the segmented retinal vessels. The performance of the proposed method is evaluated using DRIVE database to be able to compare with other state-of-art supervised and unsupervised methods. The overall segmentation accuracy of the proposed method is 95.18% which outperforms the other algorithms.
* Published at IEEE International Conference on Acoustics Speech and Signal Processing (ICASSP), 2017