 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedPAE: Peer-Adaptive Ensemble Learning for Asynchronous and Model-Heterogeneous Federated Learning
Oct 17, 2024Federated learning (FL) enables multiple clients with distributed data sources to collaboratively train a shared model without compromising data privacy. However, existing FL paradigms face challenges due to heterogeneity in client data distributions and system capabilities. Personalized federated learning (pFL) has been proposed to mitigate these problems, but often requires a shared model architecture and a central entity for parameter aggregation, resulting in scalability and communication issues. More recently, model-heterogeneous FL has gained attention due to its ability to support diverse client models, but existing methods are limited by their dependence on a centralized framework, synchronized training, and publicly available datasets. To address these limitations, we introduce Federated Peer-Adaptive Ensemble Learning (FedPAE), a fully decentralized pFL algorithm that supports model heterogeneity and asynchronous learning. Our approach utilizes a peer-to-peer model sharing mechanism and ensemble selection to achieve a more refined balance between local and global information. Experimental results show that FedPAE outperforms existing state-of-the-art pFL algorithms, effectively managing diverse client capabilities and demonstrating robustness against statistical heterogeneity.
An Explainable Deep Reinforcement Learning Model for Warfarin Maintenance Dosing Using Policy Distillation and Action Forging
Apr 26, 2024



Deep Reinforcement Learning is an effective tool for drug dosing for chronic condition management. However, the final protocol is generally a black box without any justification for its prescribed doses. This paper addresses this issue by proposing an explainable dosing protocol for warfarin using a Proximal Policy Optimization method combined with Policy Distillation. We introduce Action Forging as an effective tool to achieve explainability. Our focus is on the maintenance dosing protocol. Results show that the final model is as easy to understand and deploy as the current dosing protocols and outperforms the baseline dosing algorithms.
HintNet: Hierarchical Knowledge Transfer Networks for Traffic Accident Forecasting on Heterogeneous Spatio-Temporal Data
Mar 07, 2022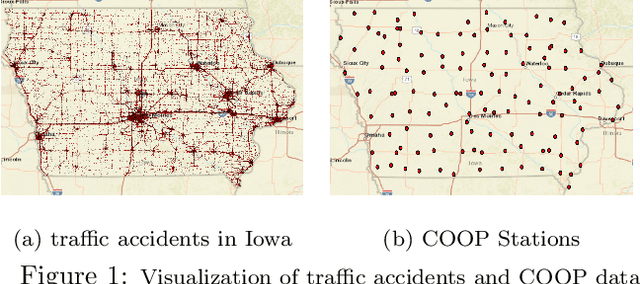

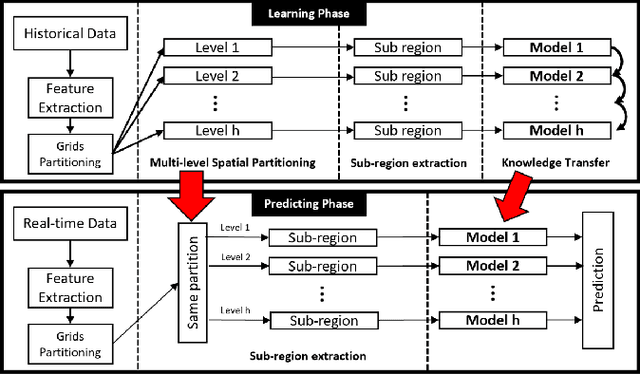
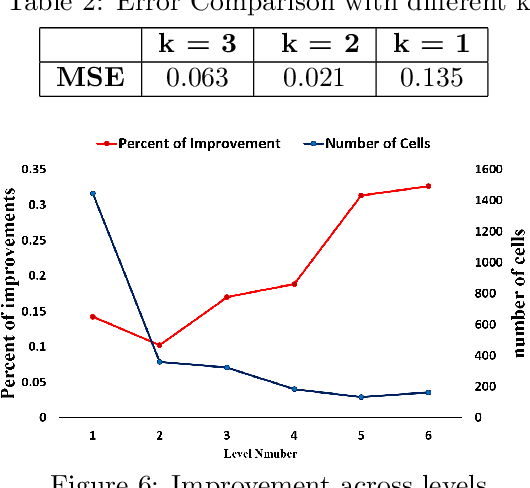
Traffic accident forecasting is a significant problem for transportation management and public safety. However, this problem is challenging due to the spatial heterogeneity of the environment and the sparsity of accidents in space and time. The occurrence of traffic accidents is affected by complex dependencies among spatial and temporal features. Recent traffic accident prediction methods have attempted to use deep learning models to improve accuracy. However, most of these methods either focus on small-scale and homogeneous areas such as populous cities or simply use sliding-window-based ensemble methods, which are inadequate to handle heterogeneity in large regions. To address these limitations, this paper proposes a novel Hierarchical Knowledge Transfer Network (HintNet) model to better capture irregular heterogeneity patterns. HintNet performs a multi-level spatial partitioning to separate sub-regions with different risks and learns a deep network model for each level using spatio-temporal and graph convolutions. Through knowledge transfer across levels, HintNet archives both higher accuracy and higher training efficiency. Extensive experiments on a real-world accident dataset from the state of Iowa demonstrate that HintNet outperforms the state-of-the-art methods on spatially heterogeneous and large-scale areas.
Optimizing Warfarin Dosing using Deep Reinforcement Learning
Feb 07, 2022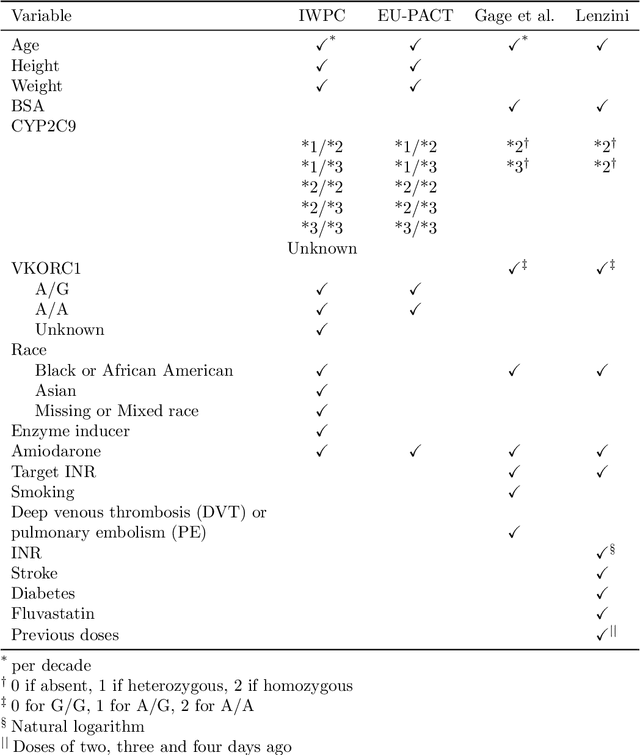
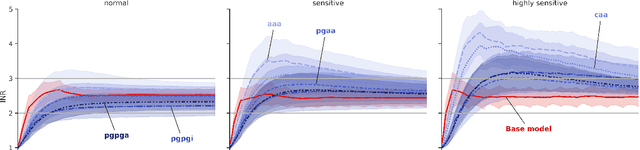

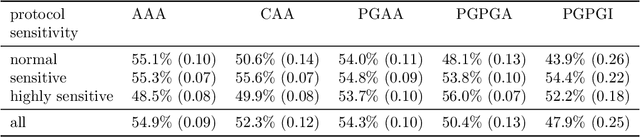
Warfarin is a widely used anticoagulant, and has a narrow therapeutic range. Dosing of warfarin should be individualized, since slight overdosing or underdosing can have catastrophic or even fatal consequences. Despite much research on warfarin dosing, current dosing protocols do not live up to expectations, especially for patients sensitive to warfarin. We propose a deep reinforcement learning-based dosing model for warfarin. To overcome the issue of relatively small sample sizes in dosing trials, we use a Pharmacokinetic/ Pharmacodynamic (PK/PD) model of warfarin to simulate dose-responses of virtual patients. Applying the proposed algorithm on virtual test patients shows that this model outperforms a set of clinically accepted dosing protocols by a wide margin.
A predictive model for kidney transplant graft survival using machine learning
Dec 07, 2020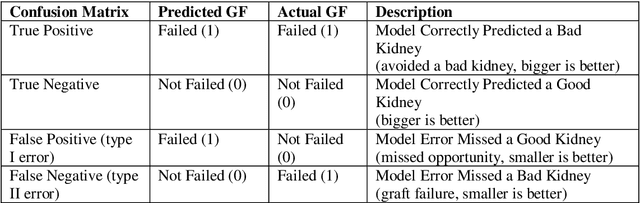
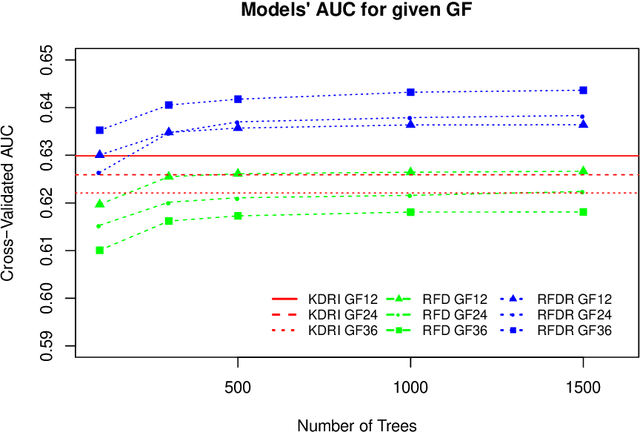
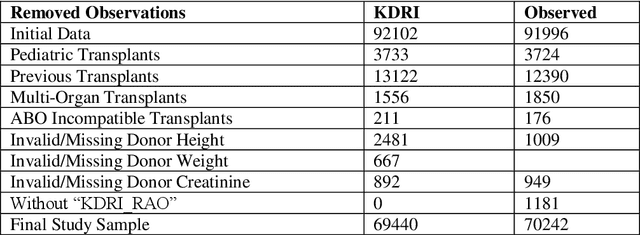
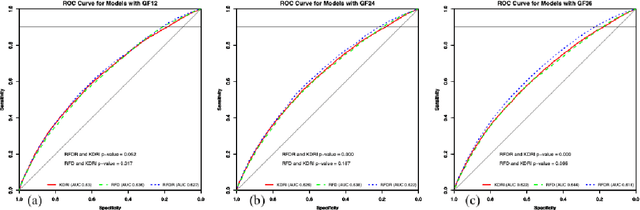
Kidney transplantation is the best treatment for end-stage renal failure patients. The predominant method used for kidney quality assessment is the Cox regression-based, kidney donor risk index. A machine learning method may provide improved prediction of transplant outcomes and help decision-making. A popular tree-based machine learning method, random forest, was trained and evaluated with the same data originally used to develop the risk index (70,242 observations from 1995-2005). The random forest successfully predicted an additional 2,148 transplants than the risk index with equal type II error rates of 10%. Predicted results were analyzed with follow-up survival outcomes up to 240 months after transplant using Kaplan-Meier analysis and confirmed that the random forest performed significantly better than the risk index (p<0.05). The random forest predicted significantly more successful and longer-surviving transplants than the risk index. Random forests and other machine learning models may improve transplant decisions.
* This work has been published: Pahl ES, Street WN, Johnson HJ, Reed AI. "A Predictive Model for Kidney Transplant Graft Survival Using Machine Learning." 4th International Conference on Computer Science and Information Technology (COMIT 2020), November 28-29, 2020, Dubai, UAE. ISBN: 978-1-925953-30-5. Volume 10, Number 16.10.5121/csit.2020.101609
Personalized Cardiovascular Disease Risk Mitigation via Longitudinal Inverse Classification
Nov 16, 2020
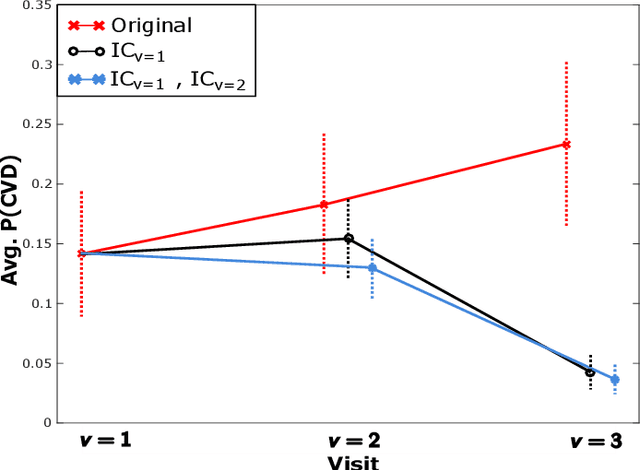
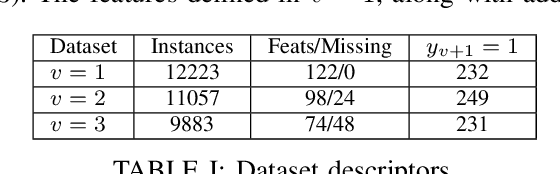
Cardiovascular disease (CVD) is a serious illness affecting millions world-wide and is the leading cause of death in the US. Recent years, however, have seen tremendous growth in the area of personalized medicine, a field of medicine that places the patient at the center of the medical decision-making and treatment process. Many CVD-focused personalized medicine innovations focus on genetic biomarkers, which provide person-specific CVD insights at the genetic level, but do not focus on the practical steps a patient could take to mitigate their risk of CVD development. In this work we propose longitudinal inverse classification, a recommendation framework that provides personalized lifestyle recommendations that minimize the predicted probability of CVD risk. Our framework takes into account historical CVD risk, as well as other patient characteristics, to provide recommendations. Our experiments show that earlier adoption of the recommendations elicited from our framework produce significant CVD risk reduction.
Predicting Urban Dispersal Events: A Two-Stage Framework through Deep Survival Analysis on Mobility Data
May 03, 2019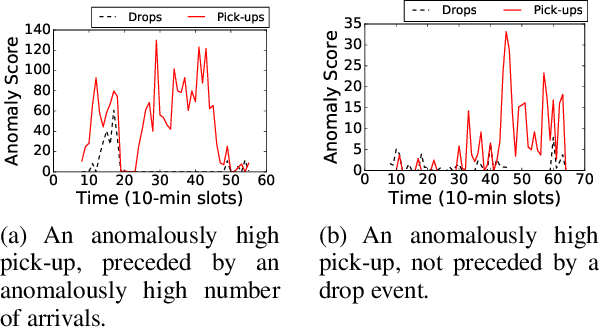
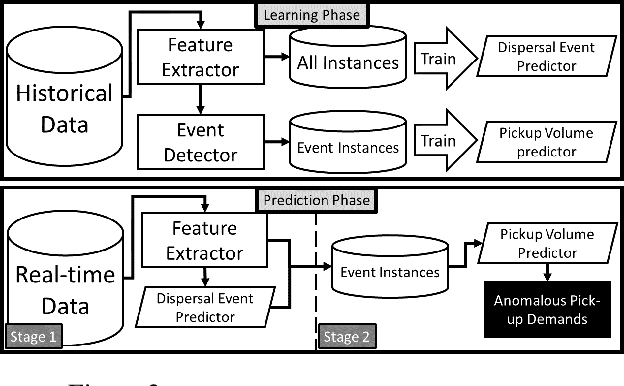
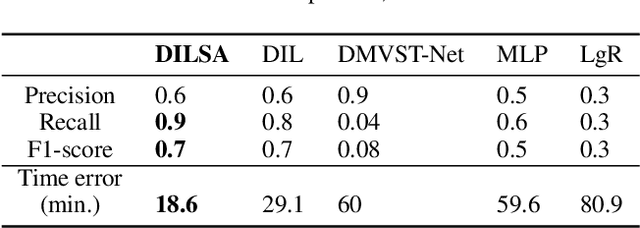
Urban dispersal events are processes where an unusually large number of people leave the same area in a short period. Early prediction of dispersal events is important in mitigating congestion and safety risks and making better dispatching decisions for taxi and ride-sharing fleets. Existing work mostly focuses on predicting taxi demand in the near future by learning patterns from historical data. However, they fail in case of abnormality because dispersal events with abnormally high demand are non-repetitive and violate common assumptions such as smoothness in demand change over time. Instead, in this paper we argue that dispersal events follow a complex pattern of trips and other related features in the past, which can be used to predict such events. Therefore, we formulate the dispersal event prediction problem as a survival analysis problem. We propose a two-stage framework (DILSA), where a deep learning model combined with survival analysis is developed to predict the probability of a dispersal event and its demand volume. We conduct extensive case studies and experiments on the NYC Yellow taxi dataset from 2014-2016. Results show that DILSA can predict events in the next 5 hours with F1-score of 0.7 and with average time error of 18 minutes. It is orders of magnitude better than the state-ofthe-art deep learning approaches for taxi demand prediction.
Deriving Enhanced Geographical Representations via Similarity-based Spectral Analysis: Predicting Colorectal Cancer Survival Curves in Iowa
Sep 06, 2018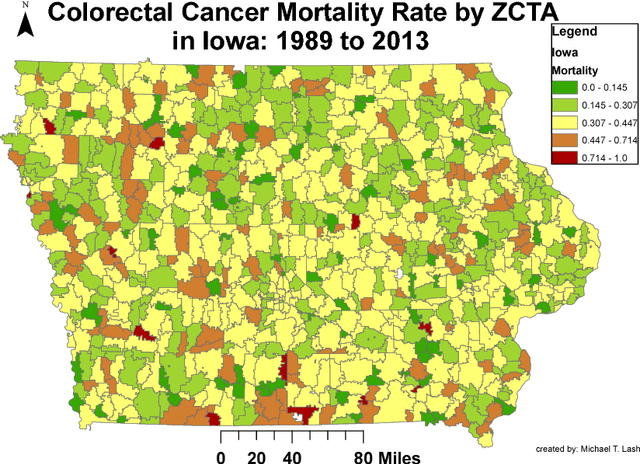

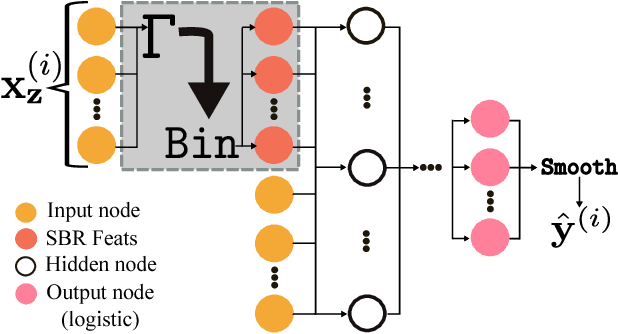
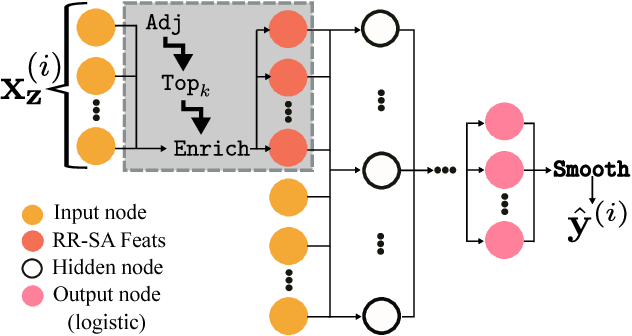
Neural networks are capable of learning rich, nonlinear feature representations shown to be beneficial in many predictive tasks. In this work, we use such models to explore different geographical feature representations in the context of predicting colorectal cancer survival curves for patients in the state of Iowa, spanning the years 1989 to 2013. Specifically, we compare model performance using "area between the curves" (ABC) to assess (a) whether survival curves can be reasonably predicted for colorectal cancer patients in the state of Iowa, (b) whether geographical features improve predictive performance, (c) whether a simple binary representation, or a richer, spectral analysis-elicited representation perform better, and (d) whether spectral analysis-based representations can be improved upon by leveraging geographically-descriptive features. In exploring (d), we devise a similarity-based spectral analysis procedure, which allows for the combination of geographically relational and geographically descriptive features. Our findings suggest that survival curves can be reasonably estimated on average, with predictive performance deviating at the five-year survival mark among all models. We also find that geographical features improve predictive performance, and that better performance is obtained using richer, spectral analysis-elicited features. Furthermore, we find that similarity-based spectral analysis-elicited representations improve upon the original spectral analysis results by approximately 40%.
Prophit: Causal inverse classification for multiple continuously valued treatment policies
Feb 14, 2018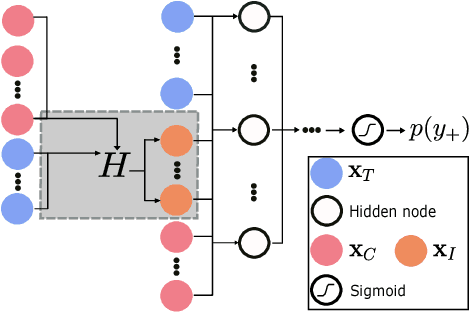
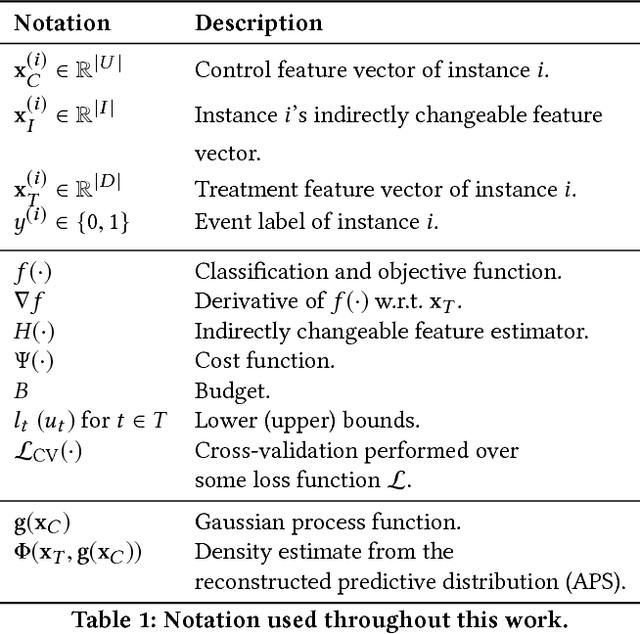
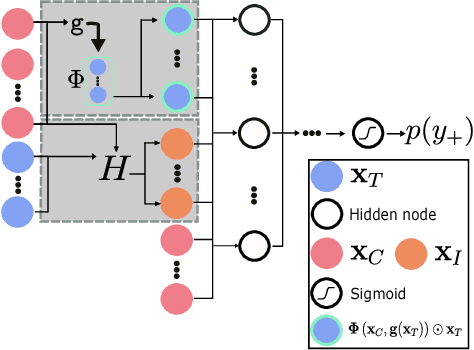

Inverse classification uses an induced classifier as a queryable oracle to guide test instances towards a preferred posterior class label. The result produced from the process is a set of instance-specific feature perturbations, or recommendations, that optimally improve the probability of the class label. In this work, we adopt a causal approach to inverse classification, eliciting treatment policies (i.e., feature perturbations) for models induced with causal properties. In so doing, we solve a long-standing problem of eliciting multiple, continuously valued treatment policies, using an updated framework and corresponding set of assumptions, which we term the inverse classification potential outcomes framework (ICPOF), along with a new measure, referred to as the individual future estimated effects ($i$FEE). We also develop the approximate propensity score (APS), based on Gaussian processes, to weight treatments, much like the inverse propensity score weighting used in past works. We demonstrate the viability of our methods on student performance.
Learning Rich Geographical Representations: Predicting Colorectal Cancer Survival in the State of Iowa
Aug 15, 2017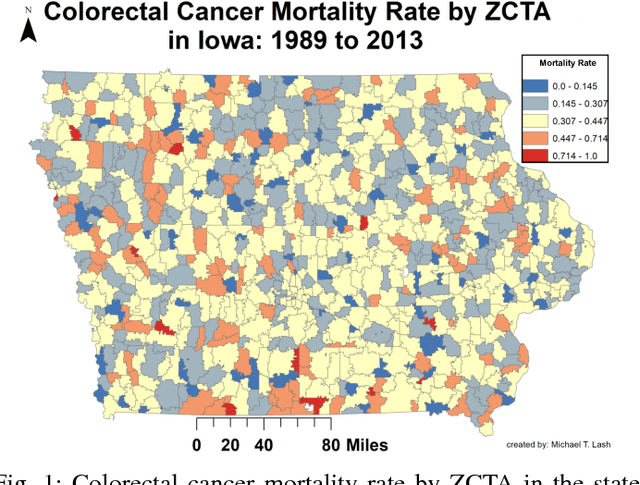
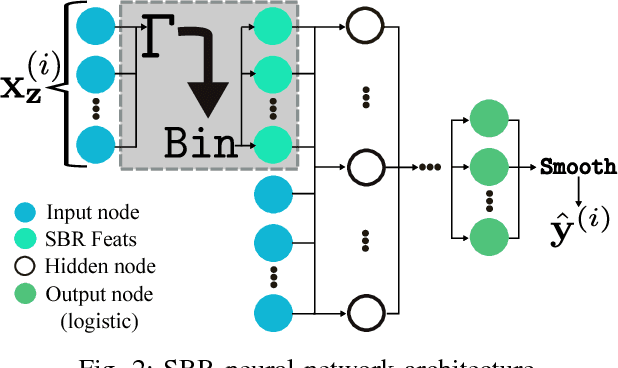
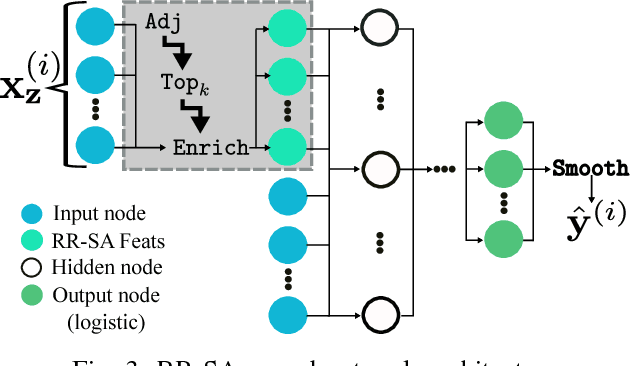
Neural networks are capable of learning rich, nonlinear feature representations shown to be beneficial in many predictive tasks. In this work, we use these models to explore the use of geographical features in predicting colorectal cancer survival curves for patients in the state of Iowa, spanning the years 1989 to 2012. Specifically, we compare model performance using a newly defined metric -- area between the curves (ABC) -- to assess (a) whether survival curves can be reasonably predicted for colorectal cancer patients in the state of Iowa, (b) whether geographical features improve predictive performance, and (c) whether a simple binary representation or richer, spectral clustering-based representation perform better. Our findings suggest that survival curves can be reasonably estimated on average, with predictive performance deviating at the five-year survival mark. We also find that geographical features improve predictive performance, and that the best performance is obtained using richer, spectral analysis-elicited features.