 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeaNMM: Ranking Short Answer Texts with Attention-Based Neural Matching Model
Jan 05, 2018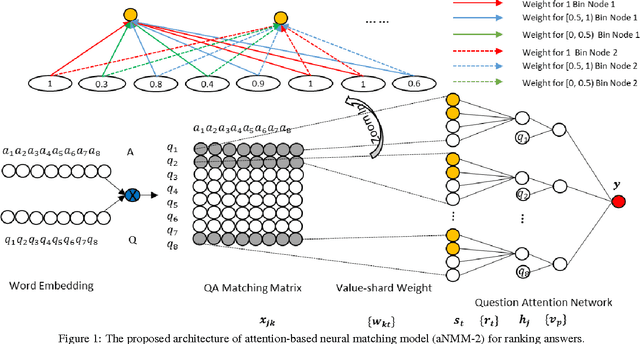
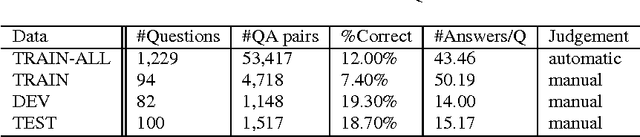
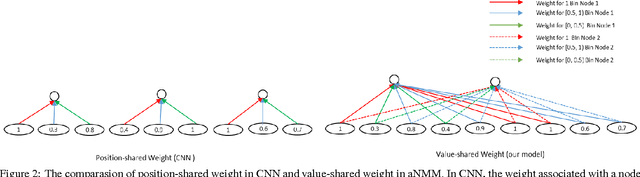
As an alternative to question answering methods based on feature engineering, deep learning approaches such as convolutional neural networks (CNNs) and Long Short-Term Memory Models (LSTMs) have recently been proposed for semantic matching of questions and answers. To achieve good results, however, these models have been combined with additional features such as word overlap or BM25 scores. Without this combination, these models perform significantly worse than methods based on linguistic feature engineering. In this paper, we propose an attention based neural matching model for ranking short answer text. We adopt value-shared weighting scheme instead of position-shared weighting scheme for combining different matching signals and incorporate question term importance learning using question attention network. Using the popular benchmark TREC QA data, we show that the relatively simple aNMM model can significantly outperform other neural network models that have been used for the question answering task, and is competitive with models that are combined with additional features. When aNMM is combined with additional features, it outperforms all baselines.
Relevance-based Word Embedding
Jul 16, 2017

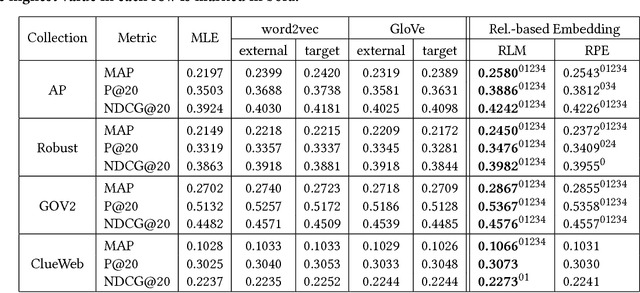
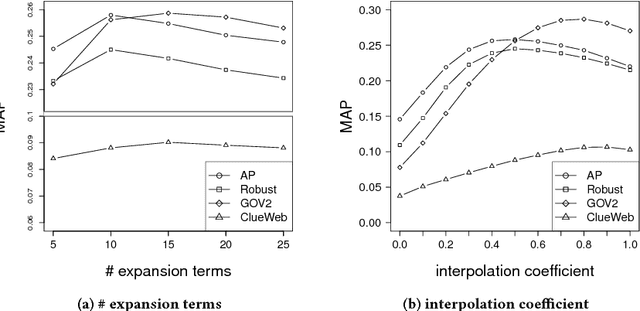
Learning a high-dimensional dense representation for vocabulary terms, also known as a word embedding, has recently attracted much attention in natural language processing and information retrieval tasks. The embedding vectors are typically learned based on term proximity in a large corpus. This means that the objective in well-known word embedding algorithms, e.g., word2vec, is to accurately predict adjacent word(s) for a given word or context. However, this objective is not necessarily equivalent to the goal of many information retrieval (IR) tasks. The primary objective in various IR tasks is to capture relevance instead of term proximity, syntactic, or even semantic similarity. This is the motivation for developing unsupervised relevance-based word embedding models that learn word representations based on query-document relevance information. In this paper, we propose two learning models with different objective functions; one learns a relevance distribution over the vocabulary set for each query, and the other classifies each term as belonging to the relevant or non-relevant class for each query. To train our models, we used over six million unique queries and the top ranked documents retrieved in response to each query, which are assumed to be relevant to the query. We extrinsically evaluate our learned word representation models using two IR tasks: query expansion and query classification. Both query expansion experiments on four TREC collections and query classification experiments on the KDD Cup 2005 dataset suggest that the relevance-based word embedding models significantly outperform state-of-the-art proximity-based embedding models, such as word2vec and GloVe.
Neural Ranking Models with Weak Supervision
May 29, 2017
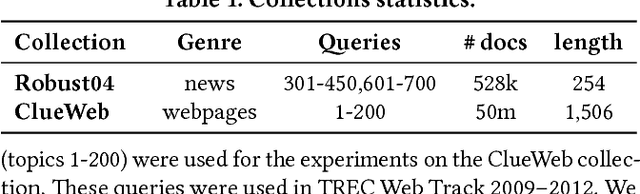
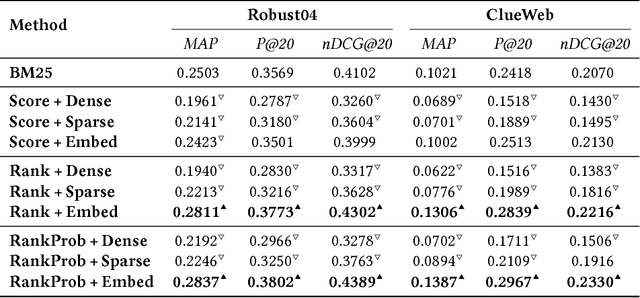
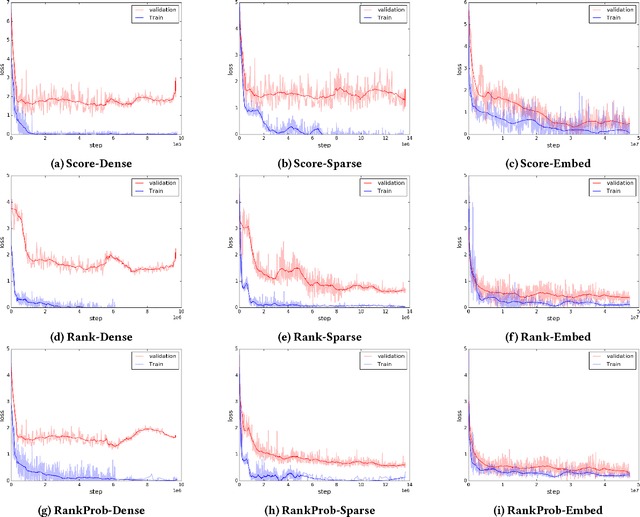
Despite the impressive improvements achieved by unsupervised deep neural networks in computer vision and NLP tasks, such improvements have not yet been observed in ranking for information retrieval. The reason may be the complexity of the ranking problem, as it is not obvious how to learn from queries and documents when no supervised signal is available. Hence, in this paper, we propose to train a neural ranking model using weak supervision, where labels are obtained automatically without human annotators or any external resources (e.g., click data). To this aim, we use the output of an unsupervised ranking model, such as BM25, as a weak supervision signal. We further train a set of simple yet effective ranking models based on feed-forward neural networks. We study their effectiveness under various learning scenarios (point-wise and pair-wise models) and using different input representations (i.e., from encoding query-document pairs into dense/sparse vectors to using word embedding representation). We train our networks using tens of millions of training instances and evaluate it on two standard collections: a homogeneous news collection(Robust) and a heterogeneous large-scale web collection (ClueWeb). Our experiments indicate that employing proper objective functions and letting the networks to learn the input representation based on weakly supervised data leads to impressive performance, with over 13% and 35% MAP improvements over the BM25 model on the Robust and the ClueWeb collections. Our findings also suggest that supervised neural ranking models can greatly benefit from pre-training on large amounts of weakly labeled data that can be easily obtained from unsupervised IR models.
Adaptability of Neural Networks on Varying Granularity IR Tasks
Jun 24, 2016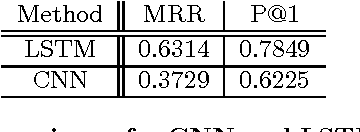
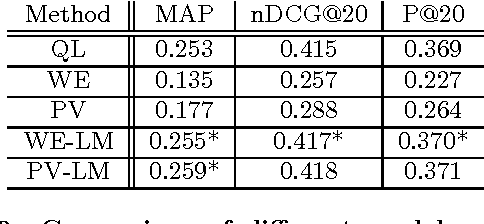
Recent work in Information Retrieval (IR) using Deep Learning models has yielded state of the art results on a variety of IR tasks. Deep neural networks (DNN) are capable of learning ideal representations of data during the training process, removing the need for independently extracting features. However, the structures of these DNNs are often tailored to perform on specific datasets. In addition, IR tasks deal with text at varying levels of granularity from single factoids to documents containing thousands of words. In this paper, we examine the role of the granularity on the performance of common state of the art DNN structures in IR.