 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-attribute Pizza Generator: Cross-domain Attribute Control with Conditional StyleGAN
Oct 22, 2021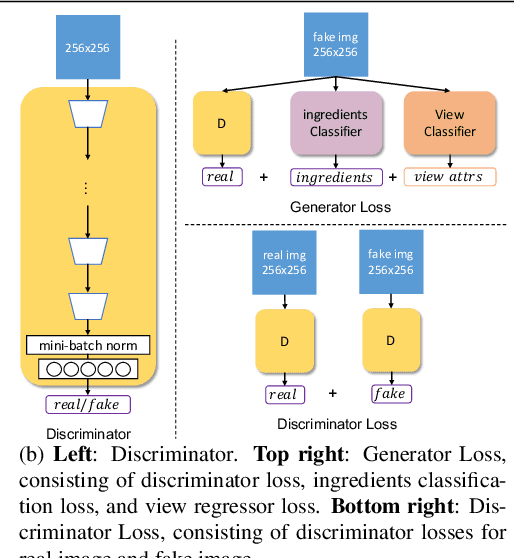
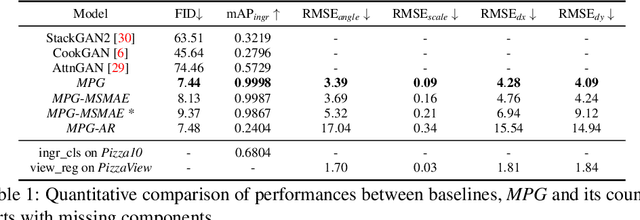
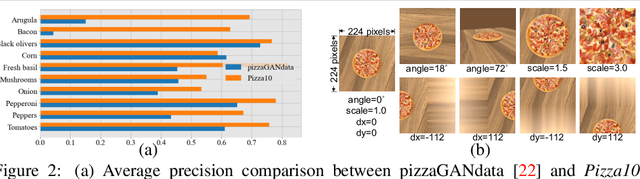
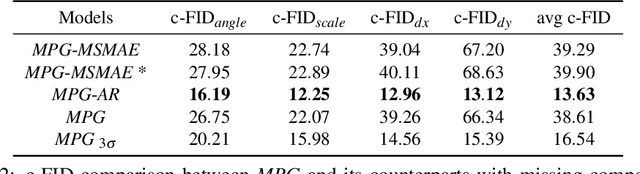
Multi-attribute conditional image generation is a challenging problem in computervision. We propose Multi-attribute Pizza Generator (MPG), a conditional Generative Neural Network (GAN) framework for synthesizing images from a trichotomy of attributes: content, view-geometry, and implicit visual style. We design MPG by extending the state-of-the-art StyleGAN2, using a new conditioning technique that guides the intermediate feature maps to learn multi-scale multi-attribute entangled representationsof controlling attributes. Because of the complex nature of the multi-attribute image generation problem, we regularize the image generation by predicting the explicit conditioning attributes (ingredients and view). To synthesize a pizza image with view attributesoutside the range of natural training images, we design a CGI pizza dataset PizzaView using 3D pizza models and employ it to train a view attribute regressor to regularize the generation process, bridging the real and CGI training datasets. To verify the efficacy of MPG, we test it on Pizza10, a carefully annotated multi-ingredient pizza image dataset. MPG can successfully generate photo-realistic pizza images with desired ingredients and view attributes, beyond the range of those observed in real-world training data.
DAReN: A Collaborative Approach Towards Reasoning And Disentangling
Sep 27, 2021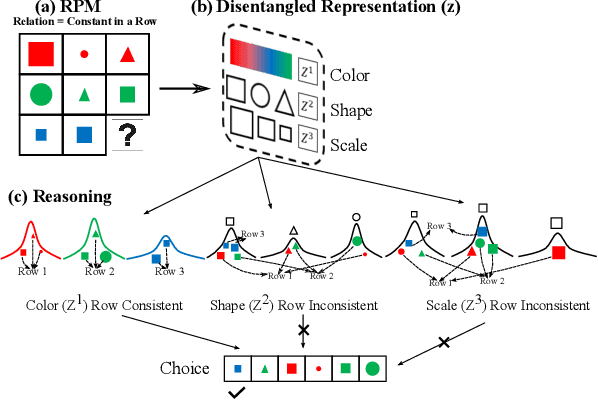

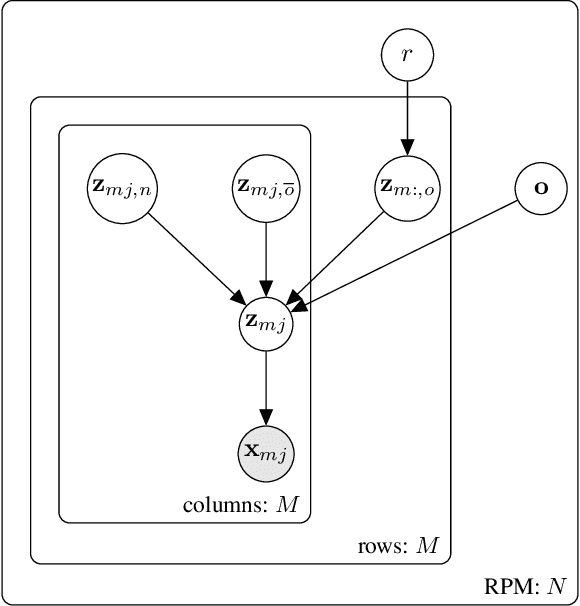
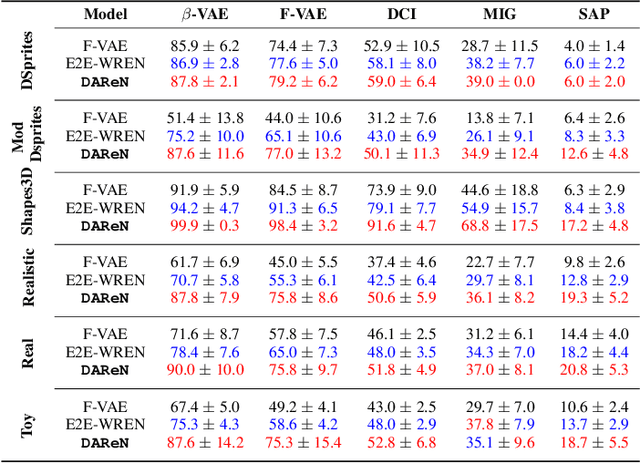
Computational learning approaches to solving visual reasoning tests, such as Raven's Progressive Matrices (RPM),critically depend on the ability of the computational approach to identify the visual concepts used in the test (i.e., the representation) as well as the latent rules based on those concepts (i.e., the reasoning). However, learning of representation and reasoning is a challenging and ill-posed task,often approached in a stage-wise manner (first representation, then reasoning). In this work, we propose an end-to-end joint representation-reasoning learning framework, which leverages a weak form of inductive bias to improve both tasks together. Specifically, we propose a general generative graphical model for RPMs, GM-RPM, and apply it to solve the reasoning test. We accomplish this using a novel learning framework Disentangling based Abstract Reasoning Network (DAReN) based on the principles of GM-RPM. We perform an empirical evaluation of DAReN over several benchmark datasets. DAReN shows consistent improvement over state-of-the-art (SOTA) models on both the reasoning and the disentanglement tasks. This demonstrates the strong correlation between disentangled latent representation and the ability to solve abstract visual reasoning tasks.
Cross-Modal Coherence for Text-to-Image Retrieval
Sep 22, 2021

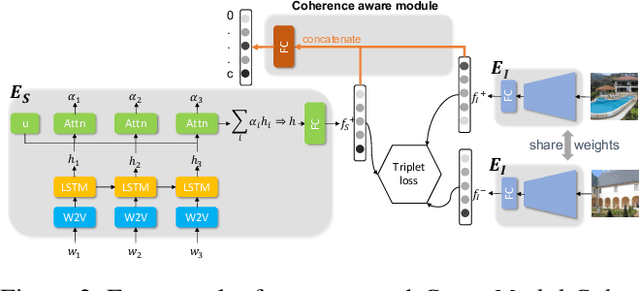

Common image-text joint understanding techniques presume that images and the associated text can universally be characterized by a single implicit model. However, co-occurring images and text can be related in qualitatively different ways, and explicitly modeling it could improve the performance of current joint understanding models. In this paper, we train a Cross-Modal Coherence Modelfor text-to-image retrieval task. Our analysis shows that models trained with image--text coherence relations can retrieve images originally paired with target text more often than coherence-agnostic models. We also show via human evaluation that images retrieved by the proposed coherence-aware model are preferred over a coherence-agnostic baseline by a huge margin. Our findings provide insights into the ways that different modalities communicate and the role of coherence relations in capturing commonsense inferences in text and imagery.
Reducing the Amortization Gap in Variational Autoencoders: A Bayesian Random Function Approach
Feb 05, 2021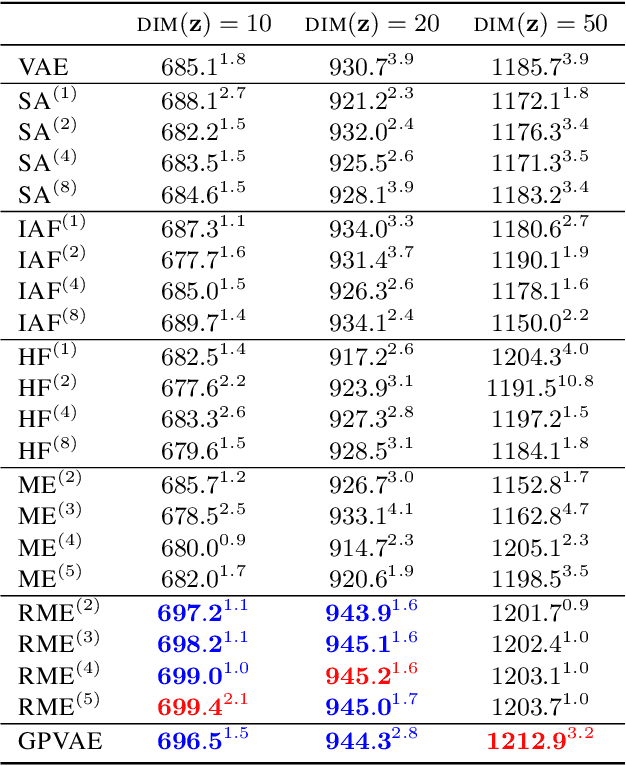
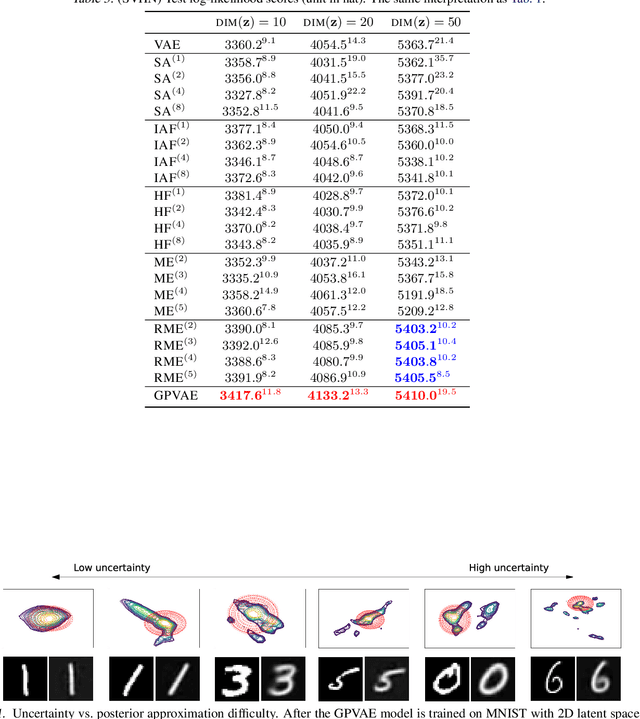
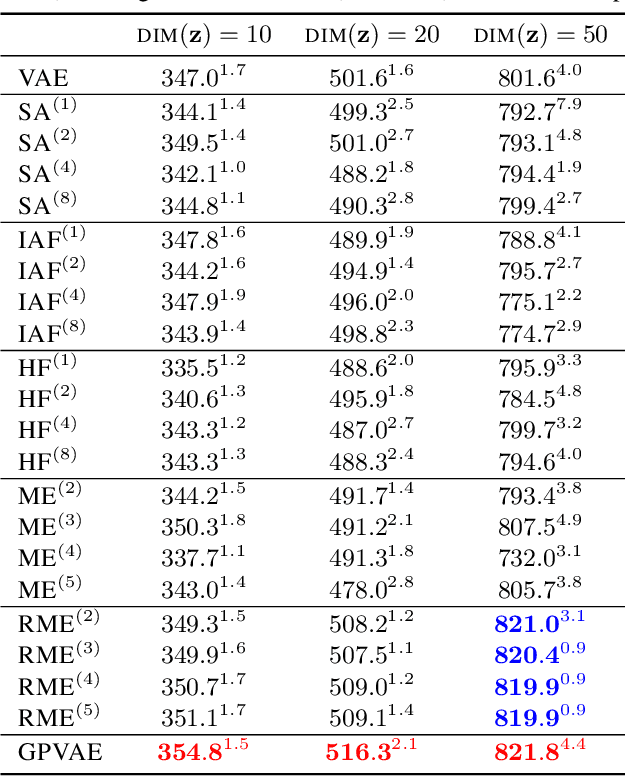
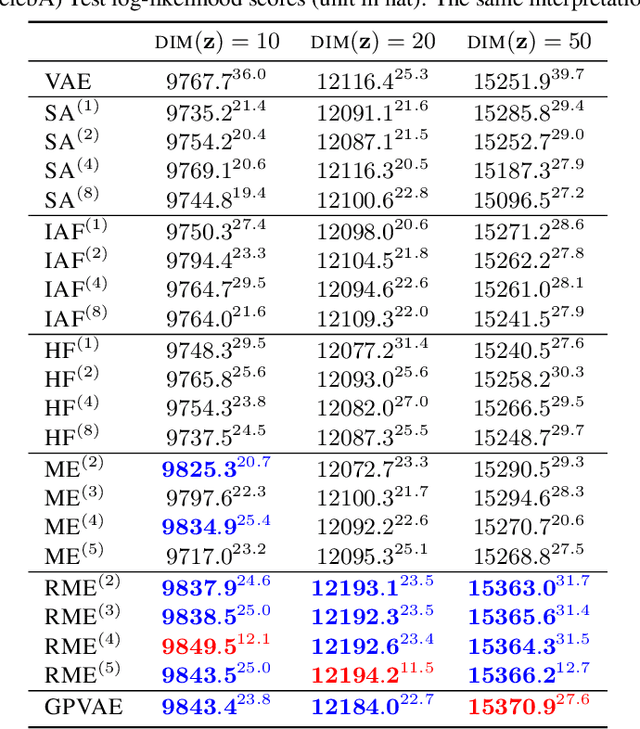
Variational autoencoder (VAE) is a very successful generative model whose key element is the so called amortized inference network, which can perform test time inference using a single feed forward pass. Unfortunately, this comes at the cost of degraded accuracy in posterior approximation, often underperforming the instance-wise variational optimization. Although the latest semi-amortized approaches mitigate the issue by performing a few variational optimization updates starting from the VAE's amortized inference output, they inherently suffer from computational overhead for inference at test time. In this paper, we address the problem in a completely different way by considering a random inference model, where we model the mean and variance functions of the variational posterior as random Gaussian processes (GP). The motivation is that the deviation of the VAE's amortized posterior distribution from the true posterior can be regarded as random noise, which allows us to take into account the uncertainty in posterior approximation in a principled manner. In particular, our model can quantify the difficulty in posterior approximation by a Gaussian variational density. Inference in our GP model is done by a single feed forward pass through the network, significantly faster than semi-amortized methods. We show that our approach attains higher test data likelihood than the state-of-the-arts on several benchmark datasets.
CHEF: Cross-modal Hierarchical Embeddings for Food Domain Retrieval
Feb 04, 2021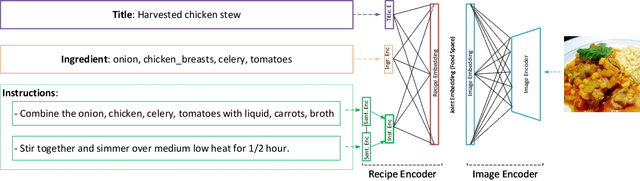
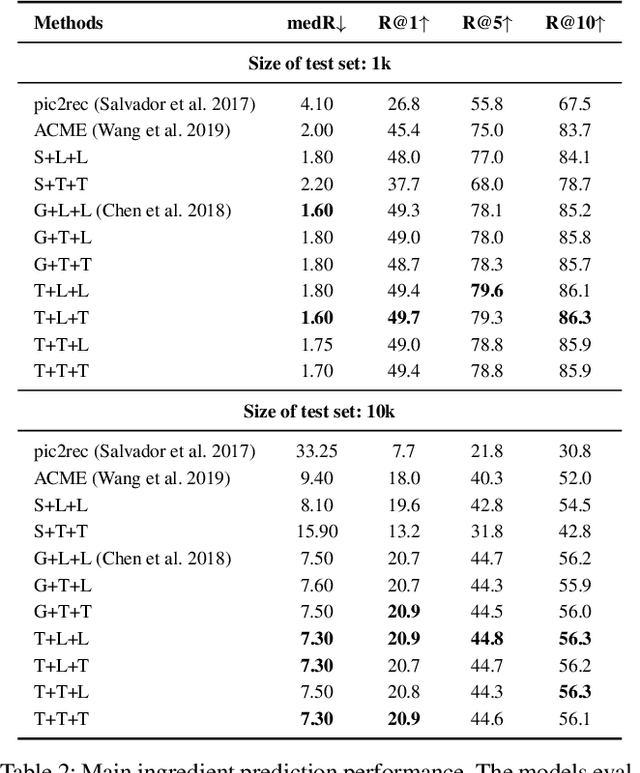
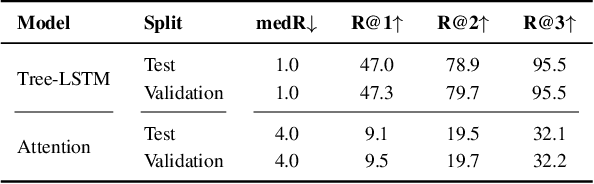

Despite the abundance of multi-modal data, such as image-text pairs, there has been little effort in understanding the individual entities and their different roles in the construction of these data instances. In this work, we endeavour to discover the entities and their corresponding importance in cooking recipes automaticall} as a visual-linguistic association problem. More specifically, we introduce a novel cross-modal learning framework to jointly model the latent representations of images and text in the food image-recipe association and retrieval tasks. This model allows one to discover complex functional and hierarchical relationships between images and text, and among textual parts of a recipe including title, ingredients and cooking instructions. Our experiments show that by making use of efficient tree-structured Long Short-Term Memory as the text encoder in our computational cross-modal retrieval framework, we are not only able to identify the main ingredients and cooking actions in the recipe descriptions without explicit supervision, but we can also learn more meaningful feature representations of food recipes, appropriate for challenging cross-modal retrieval and recipe adaption tasks.
Private-Shared Disentangled Multimodal VAE for Learning of Hybrid Latent Representations
Dec 23, 2020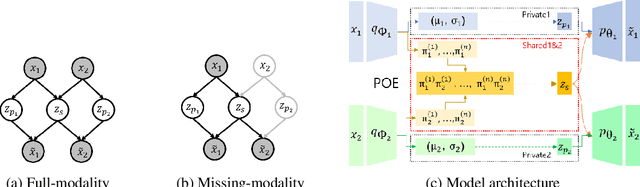
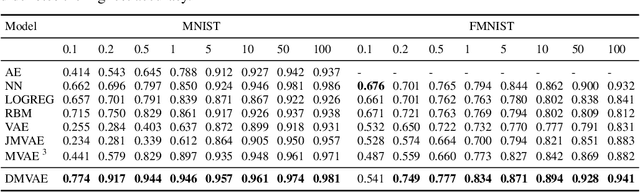

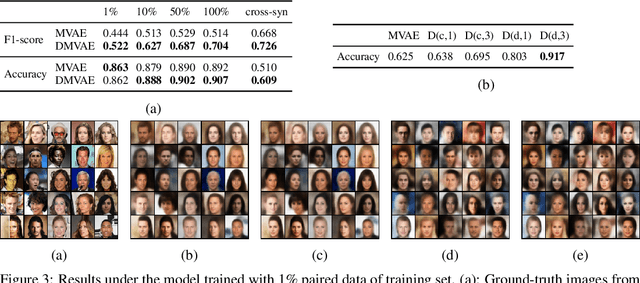
Multi-modal generative models represent an important family of deep models, whose goal is to facilitate representation learning on data with multiple views or modalities. However, current deep multi-modal models focus on the inference of shared representations, while neglecting the important private aspects of data within individual modalities. In this paper, we introduce a disentangled multi-modal variational autoencoder (DMVAE) that utilizes disentangled VAE strategy to separate the private and shared latent spaces of multiple modalities. We specifically consider the instance where the latent factor may be of both continuous and discrete nature, leading to the family of general hybrid DMVAE models. We demonstrate the utility of DMVAE on a semi-supervised learning task, where one of the modalities contains partial data labels, both relevant and irrelevant to the other modality. Our experiments on several benchmarks indicate the importance of the private-shared disentanglement as well as the hybrid latent representation.
Cross-modal Retrieval and Synthesis (X-MRS): Closing the modality gap in shared subspace
Dec 21, 2020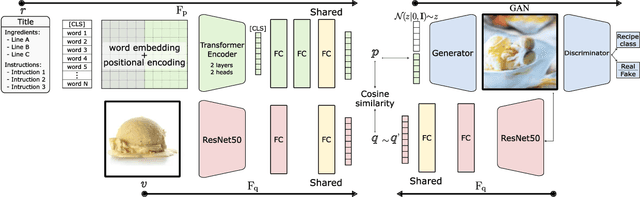
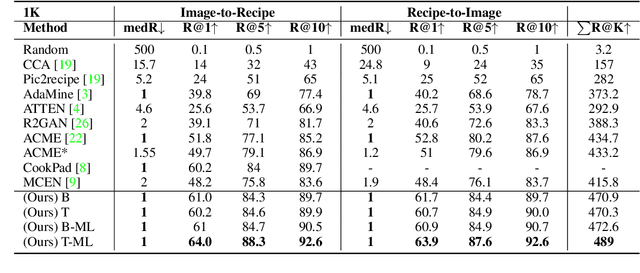
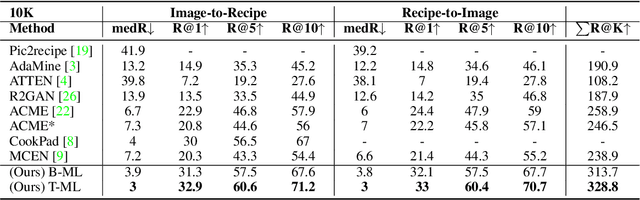

Computational food analysis (CFA), a broad set of methods that attempt to automate food understanding, naturally requires analysis of multi-modal evidence of a particular food or dish, e.g. images, recipe text, preparation video, nutrition labels, etc. A key to making CFA possible is multi-modal shared subspace learning, which in turn can be used for cross-modal retrieval and/or synthesis, particularly, between food images and their corresponding textual recipes. In this work we propose a simple yet novel architecture for shared subspace learning, which is used to tackle the food image-to-recipe retrieval problem. Our proposed method employs an effective transformer based multilingual recipe encoder coupled with a traditional image embedding architecture. Experimental analysis on the public Recipe1M dataset shows that the subspace learned via the proposed method outperforms the current state-of-the-arts (SoTA) in food retrieval by a large margin, obtaining recall@1 of 0.64. Furthermore, in order to demonstrate the representational power of the learned subspace, we propose a generative food image synthesis model conditioned on the embeddings of recipes. Synthesized images can effectively reproduce the visual appearance of paired samples, achieving R@1 of 0.68 in the image-to-recipe retrieval experiment, thus effectively capturing the semantics of the textual recipe.
MPG: A Multi-ingredient Pizza Image Generator with Conditional StyleGANs
Dec 04, 2020
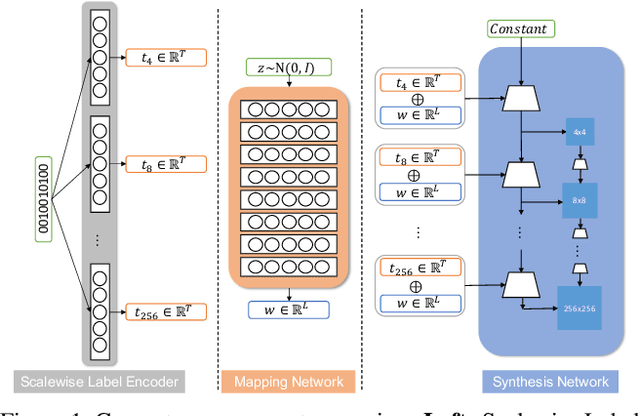
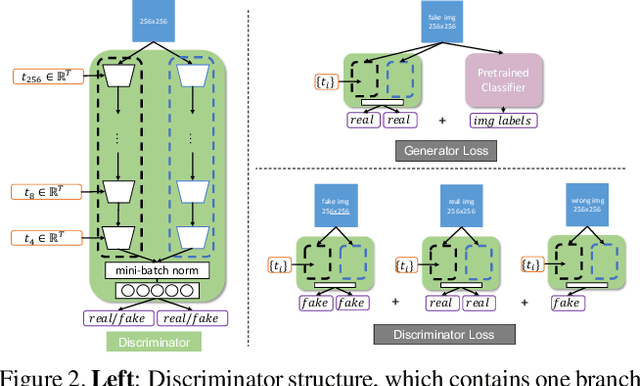
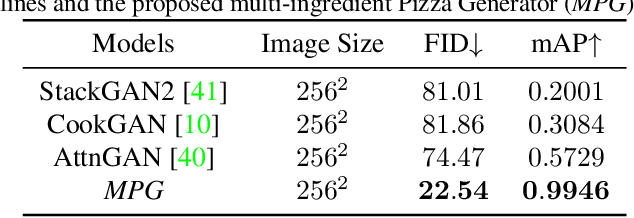
Multilabel conditional image generation is a challenging problem in computer vision. In this work we propose Multi-ingredient Pizza Generator (MPG), a conditional Generative Neural Network (GAN) framework for synthesizing multilabel images. We design MPG based on a state-of-the-art GAN structure called StyleGAN2, in which we develop a new conditioning technique by enforcing intermediate feature maps to learn scalewise label information. Because of the complex nature of the multilabel image generation problem, we also regularize synthetic image by predicting the corresponding ingredients as well as encourage the discriminator to distinguish between matched image and mismatched image. To verify the efficacy of MPG, we test it on Pizza10, which is a carefully annotated multi-ingredient pizza image dataset. MPG can successfully generate photo-realist pizza images with desired ingredients. The framework can be easily extend to other multilabel image generation scenarios.
Learning Disentangled Latent Factors from Paired Data in Cross-Modal Retrieval: An Implicit Identifiable VAE Approach
Dec 01, 2020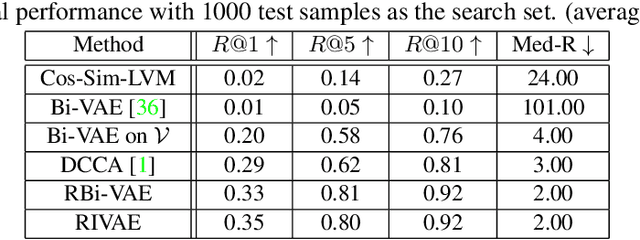
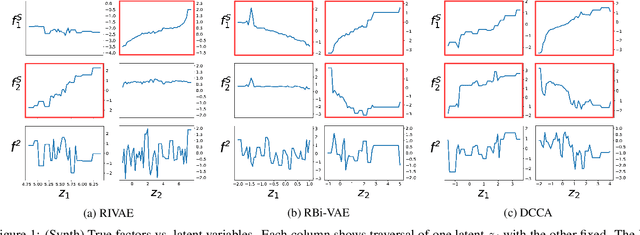
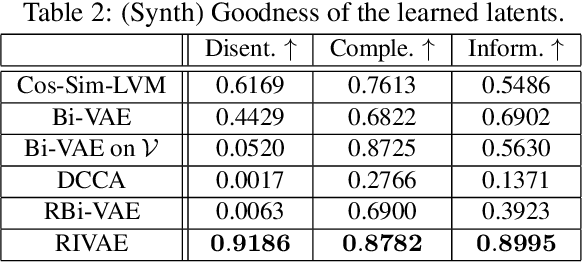

We deal with the problem of learning the underlying disentangled latent factors that are shared between the paired bi-modal data in cross-modal retrieval. Our assumption is that the data in both modalities are complex, structured, and high dimensional (e.g., image and text), for which the conventional deep auto-encoding latent variable models such as the Variational Autoencoder (VAE) often suffer from difficulty of accurate decoder training or realistic synthesis. A suboptimally trained decoder can potentially harm the model's capability of identifying the true factors. In this paper we propose a novel idea of the implicit decoder, which completely removes the ambient data decoding module from a latent variable model, via implicit encoder inversion that is achieved by Jacobian regularization of the low-dimensional embedding function. Motivated from the recent Identifiable VAE (IVAE) model, we modify it to incorporate the query modality data as conditioning auxiliary input, which allows us to prove that the true parameters of the model can be identified under some regularity conditions. Tested on various datasets where the true factors are fully/partially available, our model is shown to identify the factors accurately, significantly outperforming conventional encoder-decoder latent variable models. We also test our model on the Recipe1M, the large-scale food image/recipe dataset, where the learned factors by our approach highly coincide with the most pronounced food factors that are widely agreed on, including savoriness, wateriness, and greenness.
Recursive Inference for Variational Autoencoders
Nov 17, 2020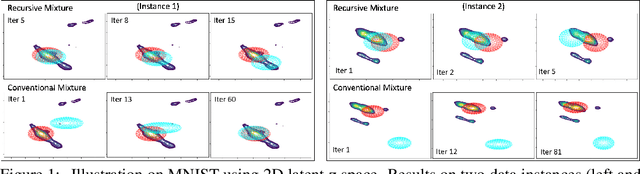
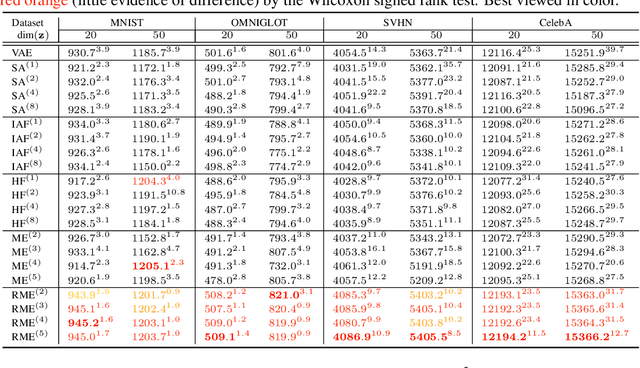
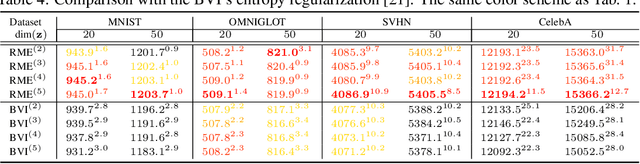

Inference networks of traditional Variational Autoencoders (VAEs) are typically amortized, resulting in relatively inaccurate posterior approximation compared to instance-wise variational optimization. Recent semi-amortized approaches were proposed to address this drawback; however, their iterative gradient update procedures can be computationally demanding. To address these issues, in this paper we introduce an accurate amortized inference algorithm. We propose a novel recursive mixture estimation algorithm for VAEs that iteratively augments the current mixture with new components so as to maximally reduce the divergence between the variational and the true posteriors. Using the functional gradient approach, we devise an intuitive learning criteria for selecting a new mixture component: the new component has to improve the data likelihood (lower bound) and, at the same time, be as divergent from the current mixture distribution as possible, thus increasing representational diversity. Compared to recently proposed boosted variational inference (BVI), our method relies on amortized inference in contrast to BVI's non-amortized single optimization instance. A crucial benefit of our approach is that the inference at test time requires a single feed-forward pass through the mixture inference network, making it significantly faster than the semi-amortized approaches. We show that our approach yields higher test data likelihood than the state-of-the-art on several benchmark datasets.