 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence-to-Sequence Spanish Pre-trained Language Models
Sep 20, 2023



In recent years, substantial advancements in pre-trained language models have paved the way for the development of numerous non-English language versions, with a particular focus on encoder-only and decoder-only architectures. While Spanish language models encompassing BERT, RoBERTa, and GPT have exhibited prowess in natural language understanding and generation, there remains a scarcity of encoder-decoder models designed for sequence-to-sequence tasks involving input-output pairs. This paper breaks new ground by introducing the implementation and evaluation of renowned encoder-decoder architectures, exclusively pre-trained on Spanish corpora. Specifically, we present Spanish versions of BART, T5, and BERT2BERT-style models and subject them to a comprehensive assessment across a diverse range of sequence-to-sequence tasks, spanning summarization, rephrasing, and generative question answering. Our findings underscore the competitive performance of all models, with BART and T5 emerging as top performers across all evaluated tasks. As an additional contribution, we have made all models publicly available to the research community, fostering future exploration and development in Spanish language processing.
A Memory Model for Question Answering from Streaming Data Supported by Rehearsal and Anticipation of Coreference Information
May 12, 2023



Existing question answering methods often assume that the input content (e.g., documents or videos) is always accessible to solve the task. Alternatively, memory networks were introduced to mimic the human process of incremental comprehension and compression of the information in a fixed-capacity memory. However, these models only learn how to maintain memory by backpropagating errors in the answers through the entire network. Instead, it has been suggested that humans have effective mechanisms to boost their memorization capacities, such as rehearsal and anticipation. Drawing inspiration from these, we propose a memory model that performs rehearsal and anticipation while processing inputs to memorize important information for solving question answering tasks from streaming data. The proposed mechanisms are applied self-supervised during training through masked modeling tasks focused on coreference information. We validate our model on a short-sequence (bAbI) dataset as well as large-sequence textual (NarrativeQA) and video (ActivityNet-QA) question answering datasets, where it achieves substantial improvements over previous memory network approaches. Furthermore, our ablation study confirms the proposed mechanisms' importance for memory models.
How Relevant is Selective Memory Population in Lifelong Language Learning?
Oct 03, 2022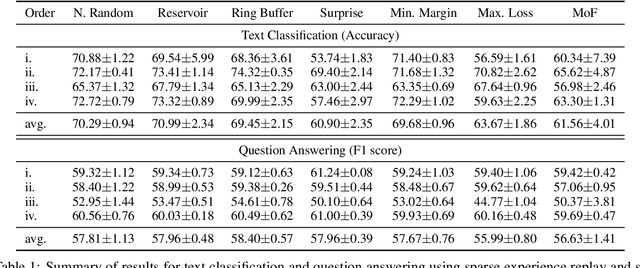
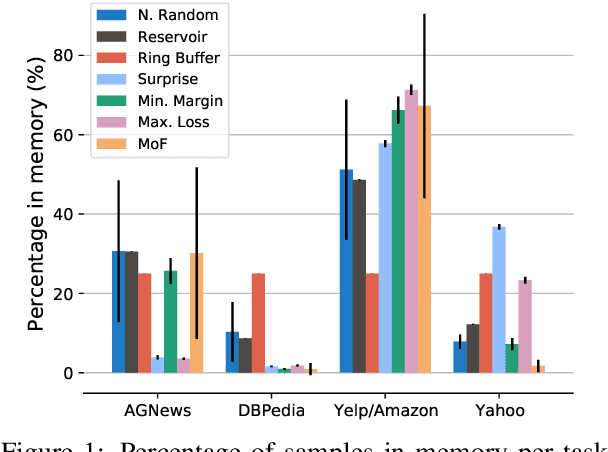

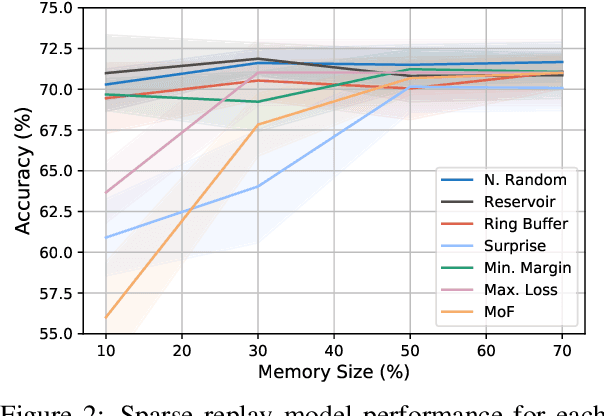
Lifelong language learning seeks to have models continuously learn multiple tasks in a sequential order without suffering from catastrophic forgetting. State-of-the-art approaches rely on sparse experience replay as the primary approach to prevent forgetting. Experience replay usually adopts sampling methods for the memory population; however, the effect of the chosen sampling strategy on model performance has not yet been studied. In this paper, we investigate how relevant the selective memory population is in the lifelong learning process of text classification and question-answering tasks. We found that methods that randomly store a uniform number of samples from the entire data stream lead to high performances, especially for low memory size, which is consistent with computer vision studies.
It's all About Consistency: A Study on Memory Composition for Replay-Based Methods in Continual Learning
Jul 04, 2022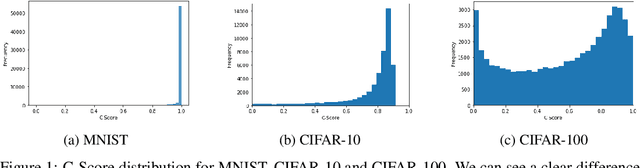
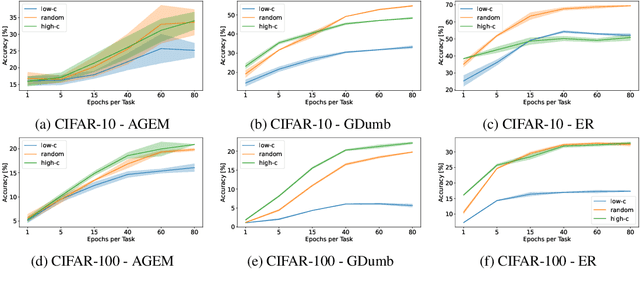
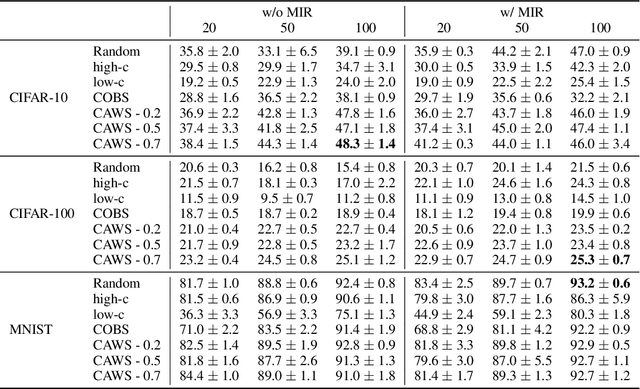
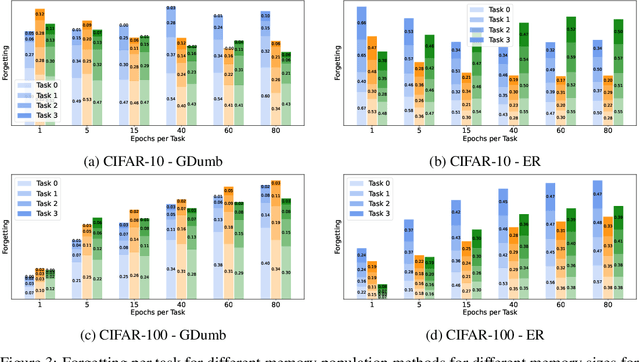
Continual Learning methods strive to mitigate Catastrophic Forgetting (CF), where knowledge from previously learned tasks is lost when learning a new one. Among those algorithms, some maintain a subset of samples from previous tasks when training. These samples are referred to as a memory. These methods have shown outstanding performance while being conceptually simple and easy to implement. Yet, despite their popularity, little has been done to understand which elements to be included into the memory. Currently, this memory is often filled via random sampling with no guiding principles that may aid in retaining previous knowledge. In this work, we propose a criterion based on the learning consistency of a sample called Consistency AWare Sampling (CAWS). This criterion prioritizes samples that are easier to learn by deep networks. We perform studies on three different memory-based methods: AGEM, GDumb, and Experience Replay, on MNIST, CIFAR-10 and CIFAR-100 datasets. We show that using the most consistent elements yields performance gains when constrained by a compute budget; when under no such constrain, random sampling is a strong baseline. However, using CAWS on Experience Replay yields improved performance over the random baseline. Finally, we show that CAWS achieves similar results to a popular memory selection method while requiring significantly less computational resources.
ALBETO and DistilBETO: Lightweight Spanish Language Models
Apr 19, 2022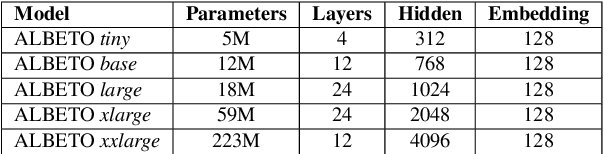

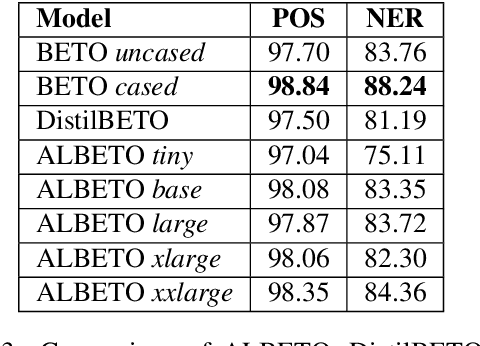
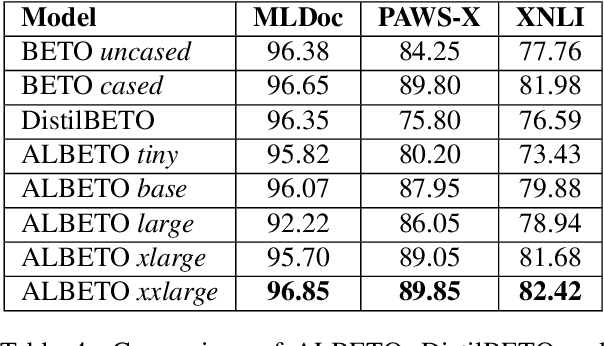
In recent years there have been considerable advances in pre-trained language models, where non-English language versions have also been made available. Due to their increasing use, many lightweight versions of these models (with reduced parameters) have also been released to speed up training and inference times. However, versions of these lighter models (e.g., ALBERT, DistilBERT) for languages other than English are still scarce. In this paper we present ALBETO and DistilBETO, which are versions of ALBERT and DistilBERT pre-trained exclusively on Spanish corpora. We train several versions of ALBETO ranging from 5M to 223M parameters and one of DistilBETO with 67M parameters. We evaluate our models in the GLUES benchmark that includes various natural language understanding tasks in Spanish. The results show that our lightweight models achieve competitive results to those of BETO (Spanish-BERT) despite having fewer parameters. More specifically, our larger ALBETO model outperforms all other models on the MLDoc, PAWS-X, XNLI, MLQA, SQAC and XQuAD datasets. However, BETO remains unbeaten for POS and NER. As a further contribution, all models are publicly available to the community for future research.
Entropy-based Stability-Plasticity for Lifelong Learning
Apr 18, 2022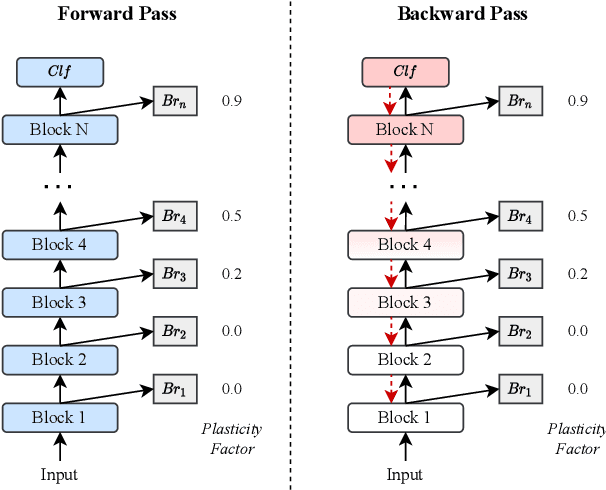
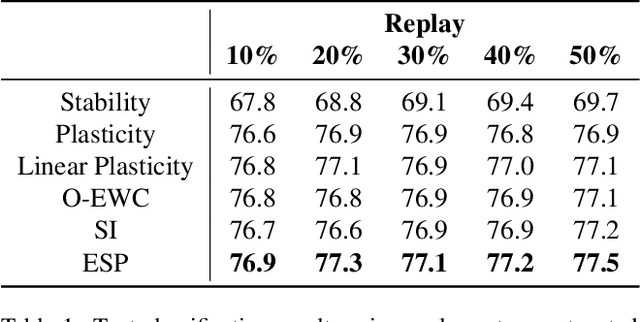
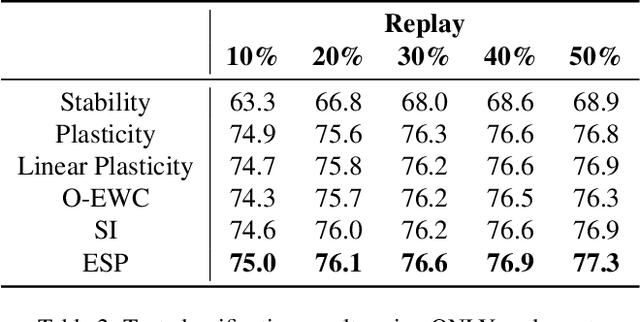
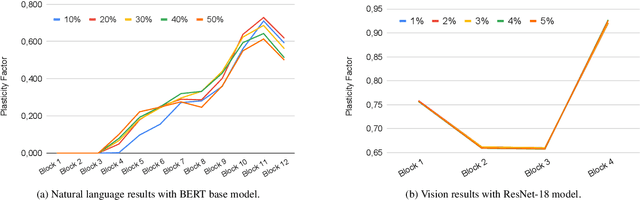
The ability to continuously learn remains elusive for deep learning models. Unlike humans, models cannot accumulate knowledge in their weights when learning new tasks, mainly due to an excess of plasticity and the low incentive to reuse weights when training a new task. To address the stability-plasticity dilemma in neural networks, we propose a novel method called Entropy-based Stability-Plasticity (ESP). Our approach can decide dynamically how much each model layer should be modified via a plasticity factor. We incorporate branch layers and an entropy-based criterion into the model to find such factor. Our experiments in the domains of natural language and vision show the effectiveness of our approach in leveraging prior knowledge by reducing interference. Also, in some cases, it is possible to freeze layers during training leading to speed up in training.
Evaluation Benchmarks for Spanish Sentence Representations
Apr 15, 2022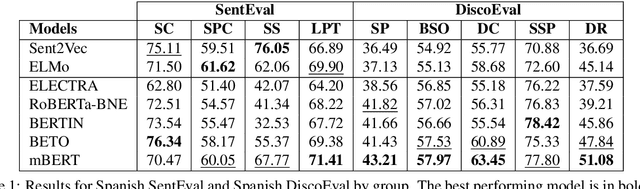
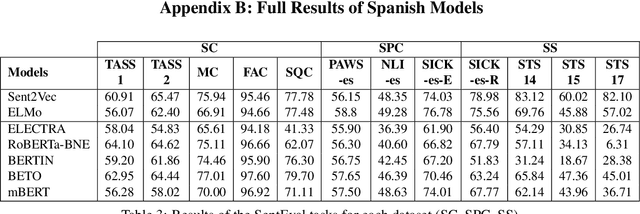
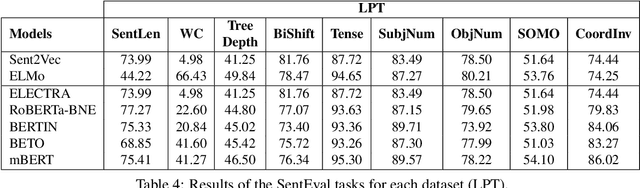
Due to the success of pre-trained language models, versions of languages other than English have been released in recent years. This fact implies the need for resources to evaluate these models. In the case of Spanish, there are few ways to systematically assess the models' quality. In this paper, we narrow the gap by building two evaluation benchmarks. Inspired by previous work (Conneau and Kiela, 2018; Chen et al., 2019), we introduce Spanish SentEval and Spanish DiscoEval, aiming to assess the capabilities of stand-alone and discourse-aware sentence representations, respectively. Our benchmarks include considerable pre-existing and newly constructed datasets that address different tasks from various domains. In addition, we evaluate and analyze the most recent pre-trained Spanish language models to exhibit their capabilities and limitations. As an example, we discover that for the case of discourse evaluation tasks, mBERT, a language model trained on multiple languages, usually provides a richer latent representation than models trained only with documents in Spanish. We hope our contribution will motivate a fairer, more comparable, and less cumbersome way to evaluate future Spanish language models.
DACT-BERT: Differentiable Adaptive Computation Time for an Efficient BERT Inference
Sep 24, 2021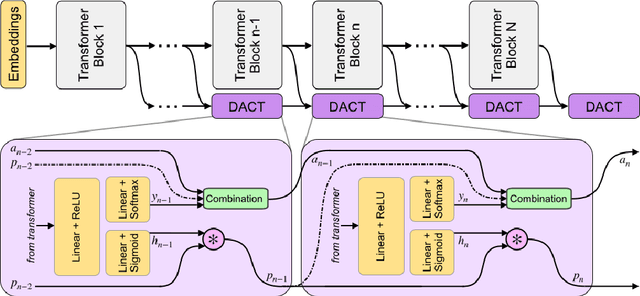
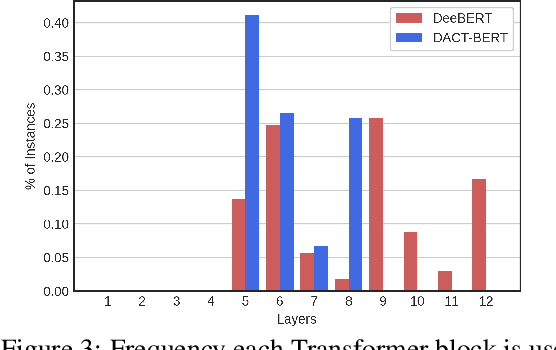
Large-scale pre-trained language models have shown remarkable results in diverse NLP applications. Unfortunately, these performance gains have been accompanied by a significant increase in computation time and model size, stressing the need to develop new or complementary strategies to increase the efficiency of these models. In this paper we propose DACT-BERT, a differentiable adaptive computation time strategy for BERT-like models. DACT-BERT adds an adaptive computational mechanism to BERT's regular processing pipeline, which controls the number of Transformer blocks that need to be executed at inference time. By doing this, the model learns to combine the most appropriate intermediate representations for the task at hand. Our experiments demonstrate that our approach, when compared to the baselines, excels on a reduced computational regime and is competitive in other less restrictive ones.
Augmenting BERT-style Models with Predictive Coding to Improve Discourse-level Representations
Sep 10, 2021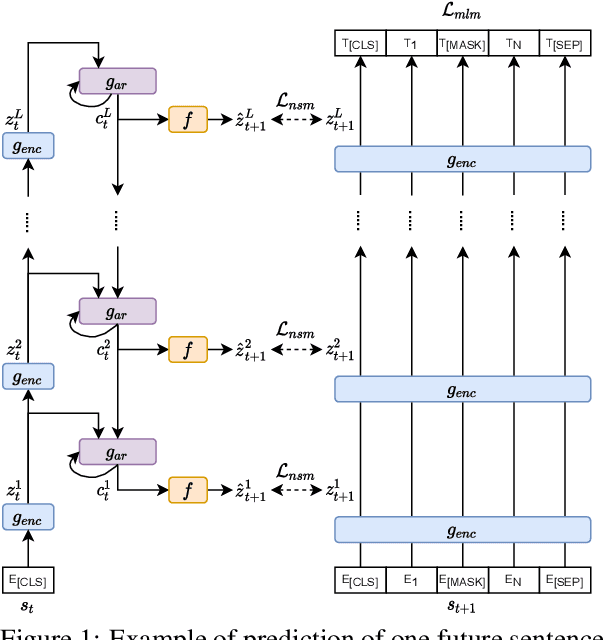
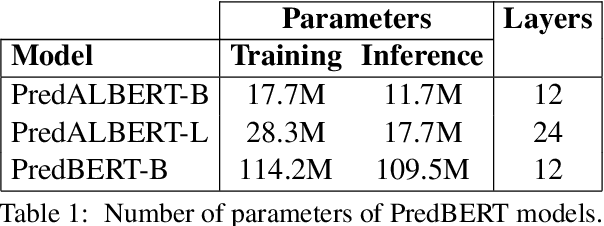
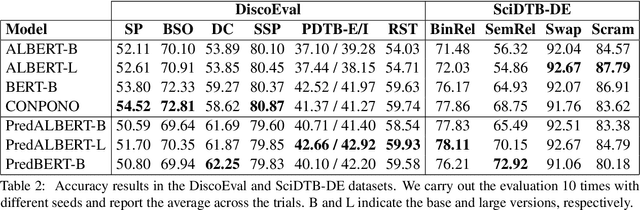
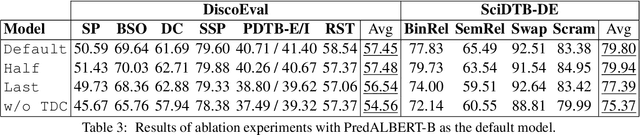
Current language models are usually trained using a self-supervised scheme, where the main focus is learning representations at the word or sentence level. However, there has been limited progress in generating useful discourse-level representations. In this work, we propose to use ideas from predictive coding theory to augment BERT-style language models with a mechanism that allows them to learn suitable discourse-level representations. As a result, our proposed approach is able to predict future sentences using explicit top-down connections that operate at the intermediate layers of the network. By experimenting with benchmarks designed to evaluate discourse-related knowledge using pre-trained sentence representations, we demonstrate that our approach improves performance in 6 out of 11 tasks by excelling in discourse relationship detection.
Stress Test Evaluation of Biomedical Word Embeddings
Jul 24, 2021
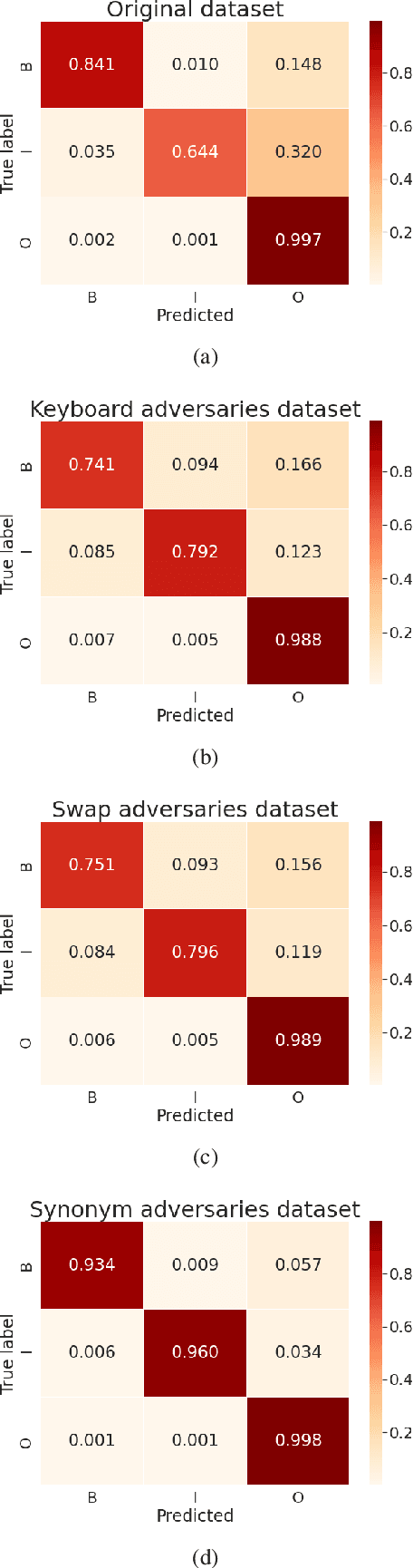

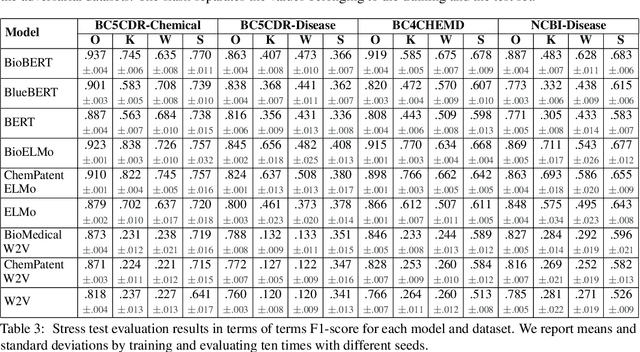
The success of pretrained word embeddings has motivated their use in the biomedical domain, with contextualized embeddings yielding remarkable results in several biomedical NLP tasks. However, there is a lack of research on quantifying their behavior under severe "stress" scenarios. In this work, we systematically evaluate three language models with adversarial examples -- automatically constructed tests that allow us to examine how robust the models are. We propose two types of stress scenarios focused on the biomedical named entity recognition (NER) task, one inspired by spelling errors and another based on the use of synonyms for medical terms. Our experiments with three benchmarks show that the performance of the original models decreases considerably, in addition to revealing their weaknesses and strengths. Finally, we show that adversarial training causes the models to improve their robustness and even to exceed the original performance in some cases.