 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Tuning for Semantic Role Labeling
May 05, 2020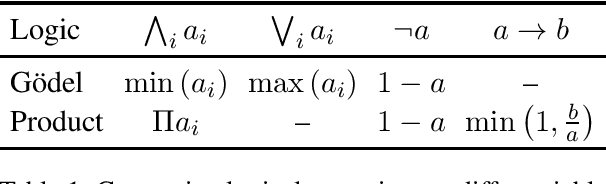
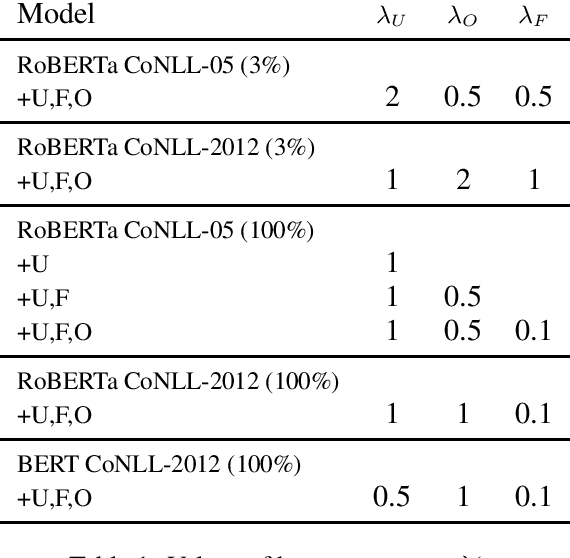
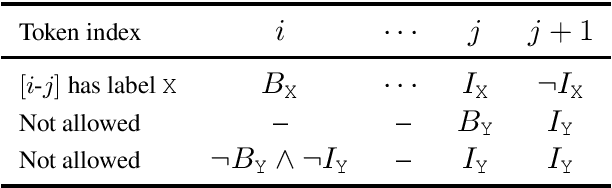
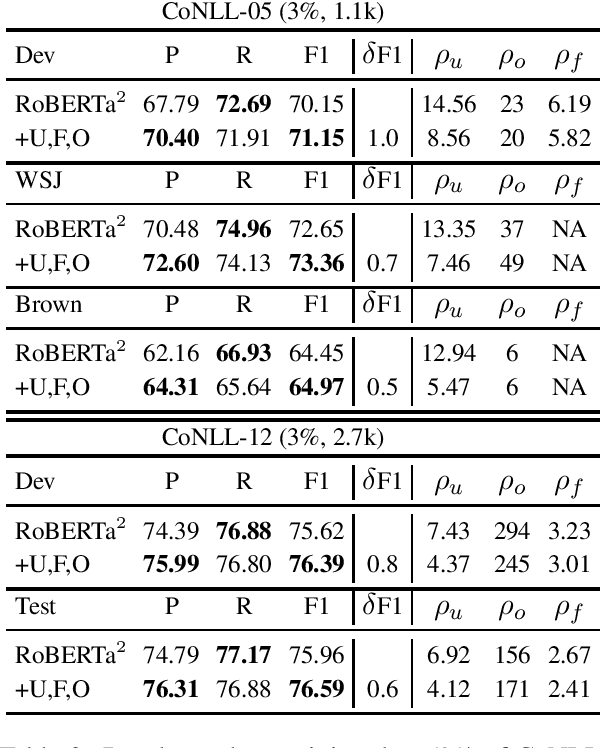
Recent neural network-driven semantic role labeling (SRL) systems have shown impressive improvements in F1 scores. These improvements are due to expressive input representations, which, at least at the surface, are orthogonal to knowledge-rich constrained decoding mechanisms that helped linear SRL models. Introducing the benefits of structure to inform neural models presents a methodological challenge. In this paper, we present a structured tuning framework to improve models using softened constraints only at training time. Our framework leverages the expressiveness of neural networks and provides supervision with structured loss components. We start with a strong baseline (RoBERTa) to validate the impact of our approach, and show that our framework outperforms the baseline by learning to comply with declarative constraints. Additionally, our experiments with smaller training sizes show that we can achieve consistent improvements under low-resource scenarios.
On the Limits of Learning to Actively Learn Semantic Representations
Oct 05, 2019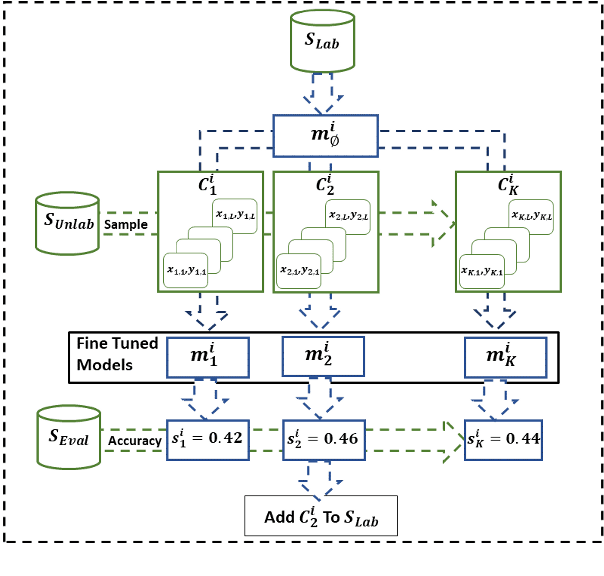

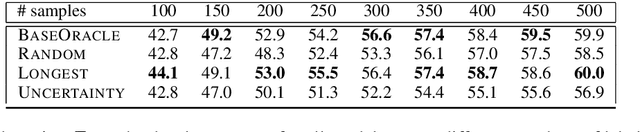
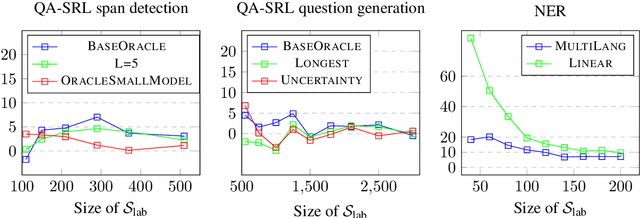
One of the goals of natural language understanding is to develop models that map sentences into meaning representations. However, training such models requires expensive annotation of complex structures, which hinders their adoption. Learning to actively-learn (LTAL) is a recent paradigm for reducing the amount of labeled data by learning a policy that selects which samples should be labeled. In this work, we examine LTAL for learning semantic representations, such as QA-SRL. We show that even an oracle policy that is allowed to pick examples that maximize performance on the test set (and constitutes an upper bound on the potential of LTAL), does not substantially improve performance compared to a random policy. We investigate factors that could explain this finding and show that a distinguishing characteristic of successful applications of LTAL is the interaction between optimization and the oracle policy selection process. In successful applications of LTAL, the examples selected by the oracle policy do not substantially depend on the optimization procedure, while in our setup the stochastic nature of optimization strongly affects the examples selected by the oracle. We conclude that the current applicability of LTAL for improving data efficiency in learning semantic meaning representations is limited.
A Logic-Driven Framework for Consistency of Neural Models
Sep 13, 2019
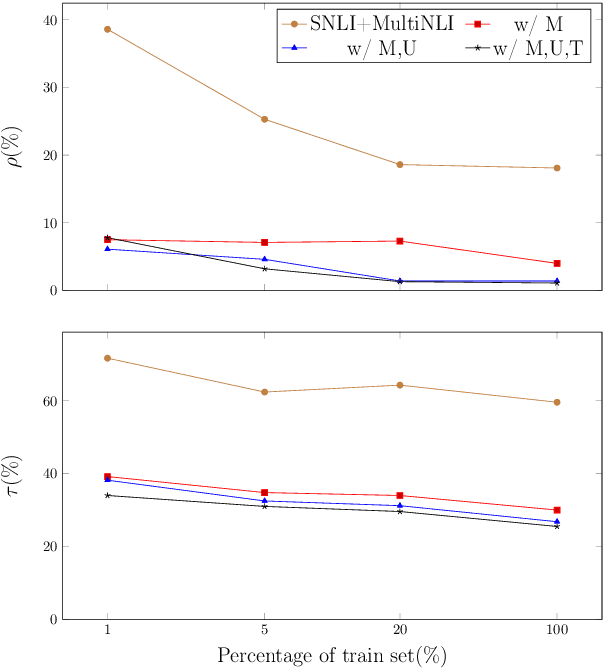
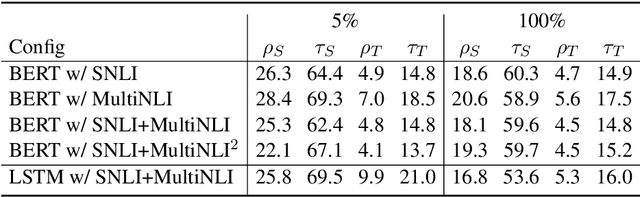
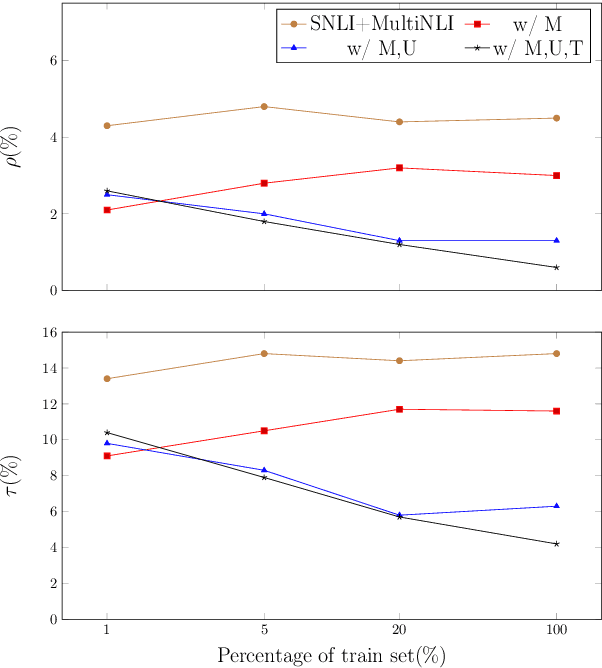
While neural models show remarkable accuracy on individual predictions, their internal beliefs can be inconsistent across examples. In this paper, we formalize such inconsistency as a generalization of prediction error. We propose a learning framework for constraining models using logic rules to regularize them away from inconsistency. Our framework can leverage both labeled and unlabeled examples and is directly compatible with off-the-shelf learning schemes without model redesign. We instantiate our framework on natural language inference, where experiments show that enforcing invariants stated in logic can help make the predictions of neural models both accurate and consistent.
On Measuring and Mitigating Biased Inferences of Word Embeddings
Aug 25, 2019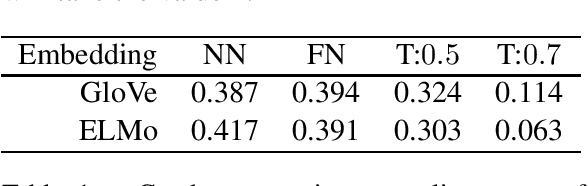
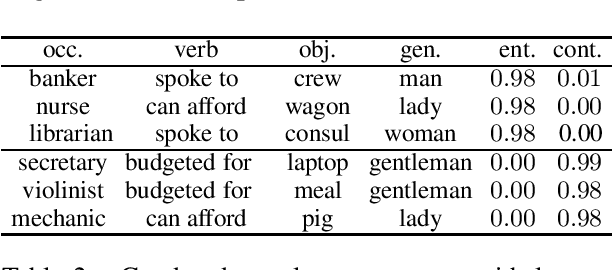
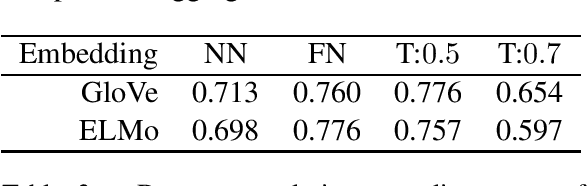

Word embeddings carry stereotypical connotations from the text they are trained on, which can lead to invalid inferences. We use this observation to design a mechanism for measuring stereotypes using the task of natural language inference. We demonstrate a reduction in invalid inferences via bias mitigation strategies on static word embeddings (GloVe), and explore adapting them to contextual embeddings (ELMo).
Augmenting Neural Networks with First-order Logic
Aug 12, 2019

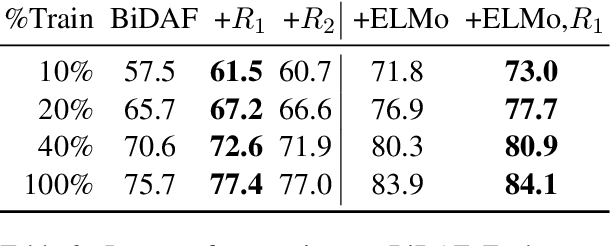
Today, the dominant paradigm for training neural networks involves minimizing task loss on a large dataset. Using world knowledge to inform a model, and yet retain the ability to perform end-to-end training remains an open question. In this paper, we present a novel framework for introducing declarative knowledge to neural network architectures in order to guide training and prediction. Our framework systematically compiles logical statements into computation graphs that augment a neural network without extra learnable parameters or manual redesign. We evaluate our modeling strategy on three tasks: machine comprehension, natural language inference, and text chunking. Our experiments show that knowledge-augmented networks can strongly improve over baselines, especially in low-data regimes.
Observing Dialogue in Therapy: Categorizing and Forecasting Behavioral Codes
Jun 30, 2019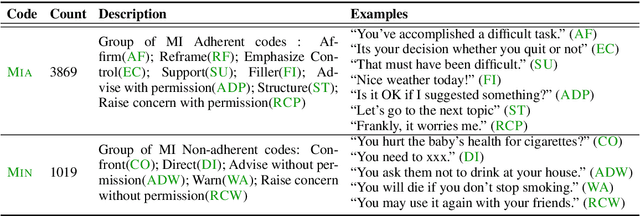
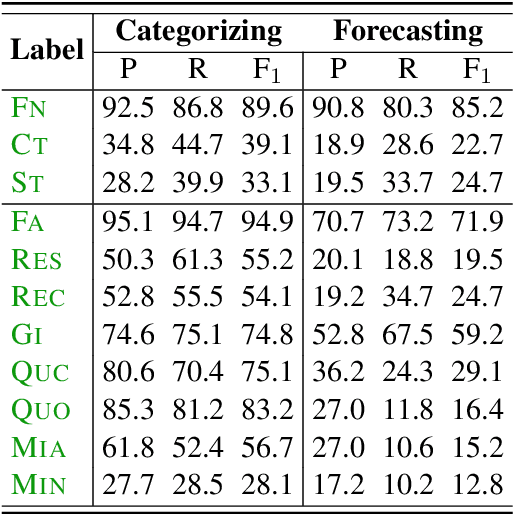
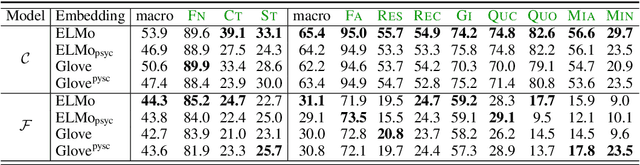
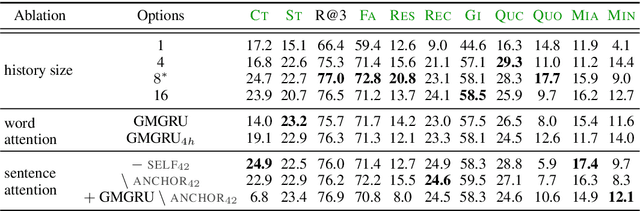
Automatically analyzing dialogue can help understand and guide behavior in domains such as counseling, where interactions are largely mediated by conversation. In this paper, we study modeling behavioral codes used to asses a psychotherapy treatment style called Motivational Interviewing (MI), which is effective for addressing substance abuse and related problems. Specifically, we address the problem of providing real-time guidance to therapists with a dialogue observer that (1) categorizes therapist and client MI behavioral codes and, (2) forecasts codes for upcoming utterances to help guide the conversation and potentially alert the therapist. For both tasks, we define neural network models that build upon recent successes in dialogue modeling. Our experiments demonstrate that our models can outperform several baselines for both tasks. We also report the results of a careful analysis that reveals the impact of the various network design tradeoffs for modeling therapy dialogue.
Learning In Practice: Reasoning About Quantization
May 27, 2019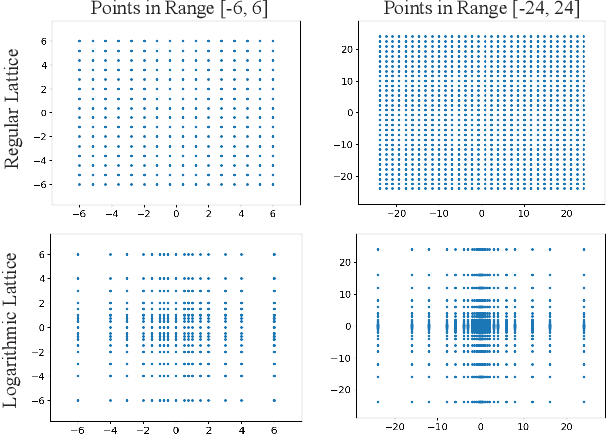
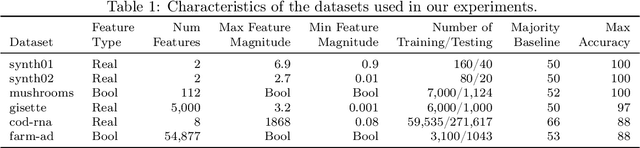
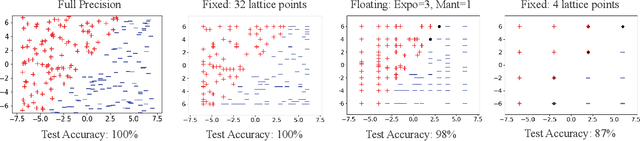
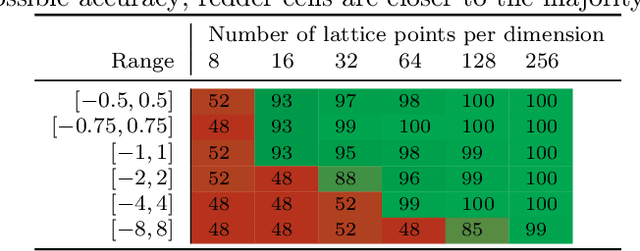
There is a mismatch between the standard theoretical analyses of statistical machine learning and how learning is used in practice. The foundational assumption supporting the theory is that we can represent features and models using real-valued parameters. In practice, however, we do not use real numbers at any point during training or deployment. Instead, we rely on discrete and finite quantizations of the reals, typically floating points. In this paper, we propose a framework for reasoning about learning under arbitrary quantizations. Using this formalization, we prove the convergence of quantization-aware versions of the Perceptron and Frank-Wolfe algorithms. Finally, we report the results of an extensive empirical study of the impact of quantization using a broad spectrum of datasets.
Adposition and Case Supersenses v2: Guidelines for English
Jul 02, 2018This document offers a detailed linguistic description of SNACS (Semantic Network of Adposition and Case Supersenses; Schneider et al., 2018), an inventory of 50 semantic labels ("supersenses") that characterize the use of adpositions and case markers at a somewhat coarse level of granularity, as demonstrated in the STREUSLE 4.1 corpus (https://github.com/nert-gu/streusle/). Though the SNACS inventory aspires to be universal, this document is specific to English; documentation for other languages will be published separately. Version 2 is a revision of the supersense inventory proposed for English by Schneider et al. (2015, 2016) (henceforth "v1"), which in turn was based on previous schemes. The present inventory was developed after extensive review of the v1 corpus annotations for English, plus previously unanalyzed genitive case possessives (Blodgett and Schneider, 2018), as well as consideration of adposition and case phenomena in Hebrew, Hindi, Korean, and German. Hwang et al. (2017) present the theoretical underpinnings of the v2 scheme. Schneider et al. (2018) summarize the scheme, its application to English corpus data, and an automatic disambiguation task.
Learning to Speed Up Structured Output Prediction
Jun 11, 2018
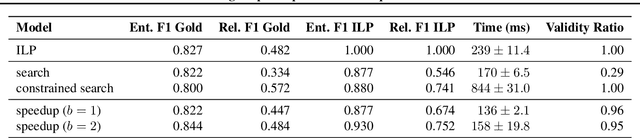
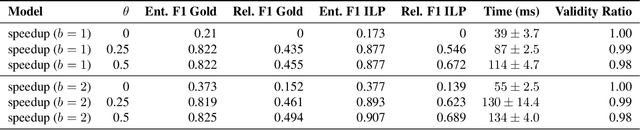
Predicting structured outputs can be computationally onerous due to the combinatorially large output spaces. In this paper, we focus on reducing the prediction time of a trained black-box structured classifier without losing accuracy. To do so, we train a speedup classifier that learns to mimic a black-box classifier under the learning-to-search approach. As the structured classifier predicts more examples, the speedup classifier will operate as a learned heuristic to guide search to favorable regions of the output space. We present a mistake bound for the speedup classifier and identify inference situations where it can independently make correct judgments without input features. We evaluate our method on the task of entity and relation extraction and show that the speedup classifier outperforms even greedy search in terms of speed without loss of accuracy.
Comprehensive Supersense Disambiguation of English Prepositions and Possessives
May 13, 2018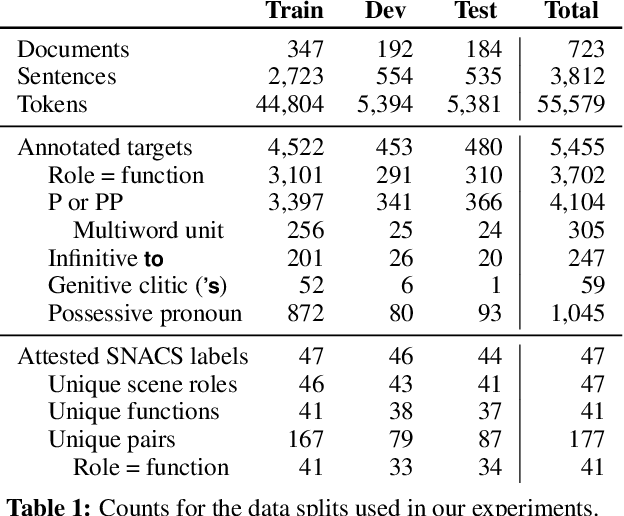
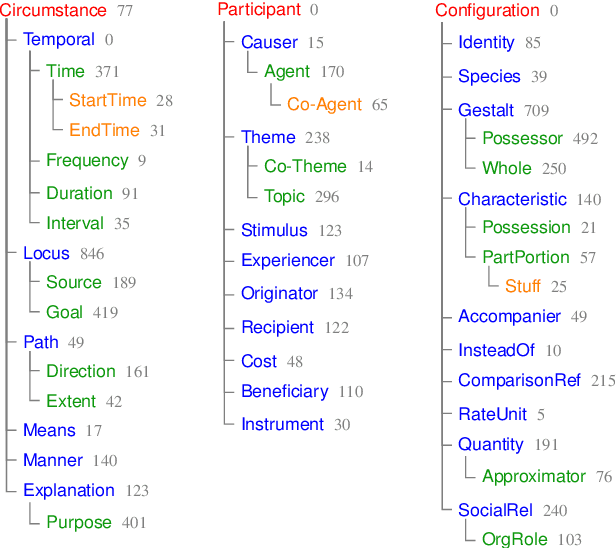

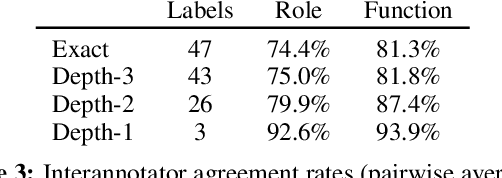
Semantic relations are often signaled with prepositional or possessive marking--but extreme polysemy bedevils their analysis and automatic interpretation. We introduce a new annotation scheme, corpus, and task for the disambiguation of prepositions and possessives in English. Unlike previous approaches, our annotations are comprehensive with respect to types and tokens of these markers; use broadly applicable supersense classes rather than fine-grained dictionary definitions; unite prepositions and possessives under the same class inventory; and distinguish between a marker's lexical contribution and the role it marks in the context of a predicate or scene. Strong interannotator agreement rates, as well as encouraging disambiguation results with established supervised methods, speak to the viability of the scheme and task.