 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtreme clicking for efficient object annotation
Aug 09, 2017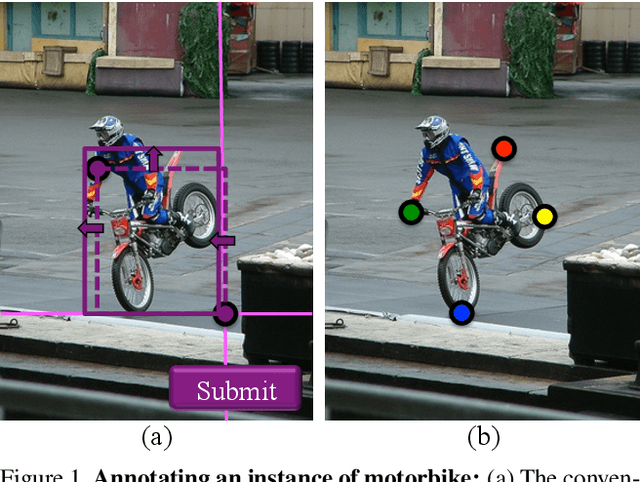
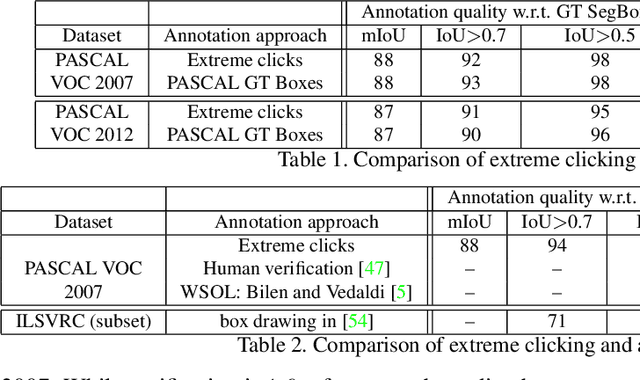
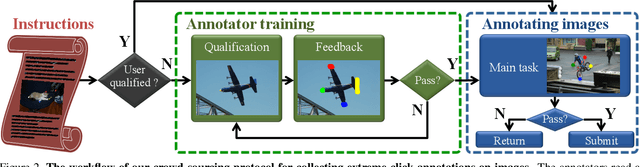
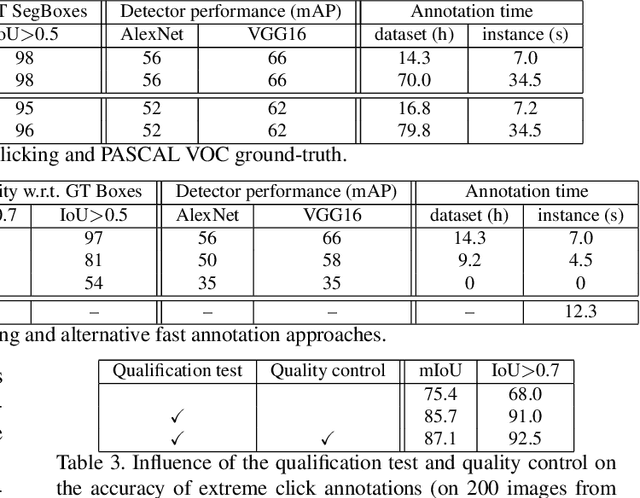
Manually annotating object bounding boxes is central to building computer vision datasets, and it is very time consuming (annotating ILSVRC [53] took 35s for one high-quality box [62]). It involves clicking on imaginary corners of a tight box around the object. This is difficult as these corners are often outside the actual object and several adjustments are required to obtain a tight box. We propose extreme clicking instead: we ask the annotator to click on four physical points on the object: the top, bottom, left- and right-most points. This task is more natural and these points are easy to find. We crowd-source extreme point annotations for PASCAL VOC 2007 and 2012 and show that (1) annotation time is only 7s per box, 5x faster than the traditional way of drawing boxes [62]; (2) the quality of the boxes is as good as the original ground-truth drawn the traditional way; (3) detectors trained on our annotations are as accurate as those trained on the original ground-truth. Moreover, our extreme clicking strategy not only yields box coordinates, but also four accurate boundary points. We show (4) how to incorporate them into GrabCut to obtain more accurate segmentations than those delivered when initializing it from bounding boxes; (5) semantic segmentations models trained on these segmentations outperform those trained on segmentations derived from bounding boxes.
Weakly Supervised Object Localization Using Things and Stuff Transfer
Aug 07, 2017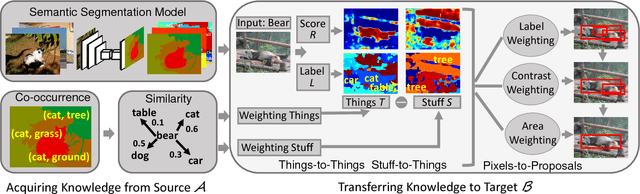
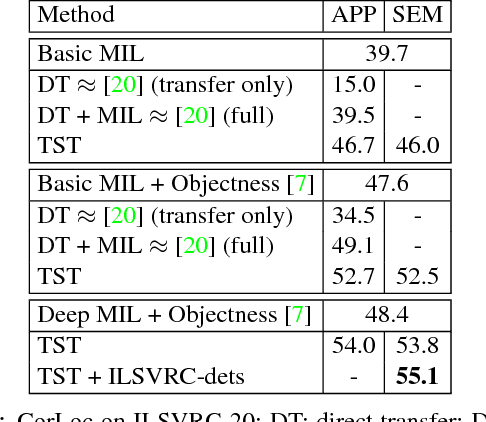
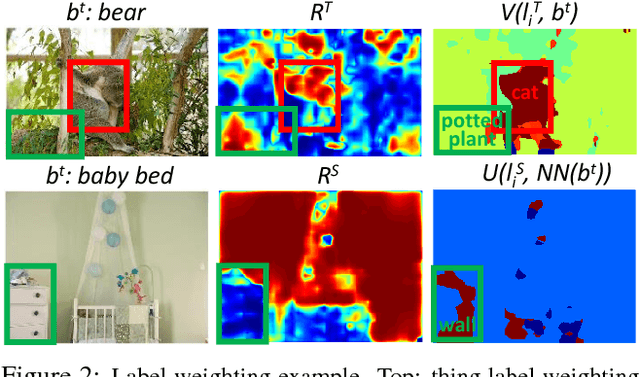

We propose to help weakly supervised object localization for classes where location annotations are not available, by transferring things and stuff knowledge from a source set with available annotations. The source and target classes might share similar appearance (e.g. bear fur is similar to cat fur) or appear against similar background (e.g. horse and sheep appear against grass). To exploit this, we acquire three types of knowledge from the source set: a segmentation model trained on both thing and stuff classes; similarity relations between target and source classes; and co-occurrence relations between thing and stuff classes in the source. The segmentation model is used to generate thing and stuff segmentation maps on a target image, while the class similarity and co-occurrence knowledge help refining them. We then incorporate these maps as new cues into a multiple instance learning framework (MIL), propagating the transferred knowledge from the pixel level to the object proposal level. In extensive experiments, we conduct our transfer from the PASCAL Context dataset (source) to the ILSVRC, COCO and PASCAL VOC 2007 datasets (targets). We evaluate our transfer across widely different thing classes, including some that are not similar in appearance, but appear against similar background. The results demonstrate significant improvement over standard MIL, and we outperform the state-of-the-art in the transfer setting.
Learning Semantic Part-Based Models from Google Images
Jul 06, 2017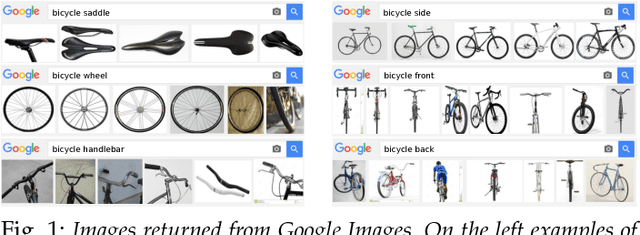
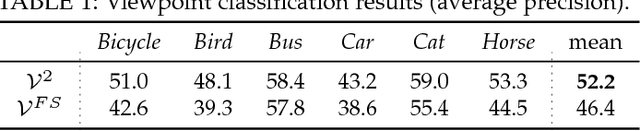
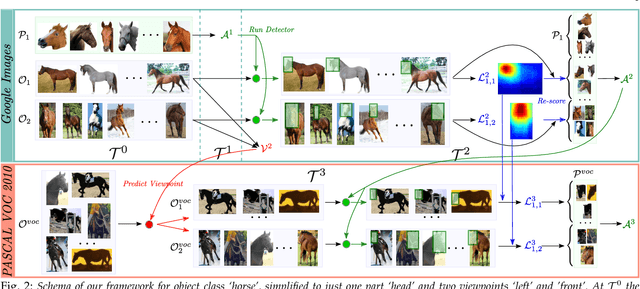
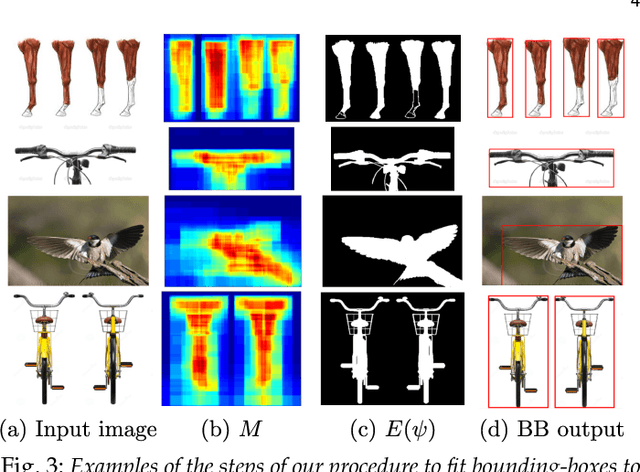
We propose a technique to train semantic part-based models of object classes from Google Images. Our models encompass the appearance of parts and their spatial arrangement on the object, specific to each viewpoint. We learn these rich models by collecting training instances for both parts and objects, and automatically connecting the two levels. Our framework works incrementally, by learning from easy examples first, and then gradually adapting to harder ones. A key benefit of this approach is that it requires no manual part location annotations. We evaluate our models on the challenging PASCAL-Part dataset [1] and show how their performance increases at every step of the learning, with the final models more than doubling the performance of directly training from images retrieved by querying for part names (from 12.9 to 27.2 AP). Moreover, we show that our part models can help object detection performance by enriching the R-CNN detector with parts.
How hard can it be? Estimating the difficulty of visual search in an image
May 23, 2017

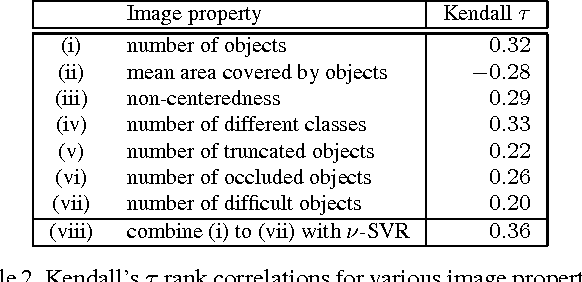
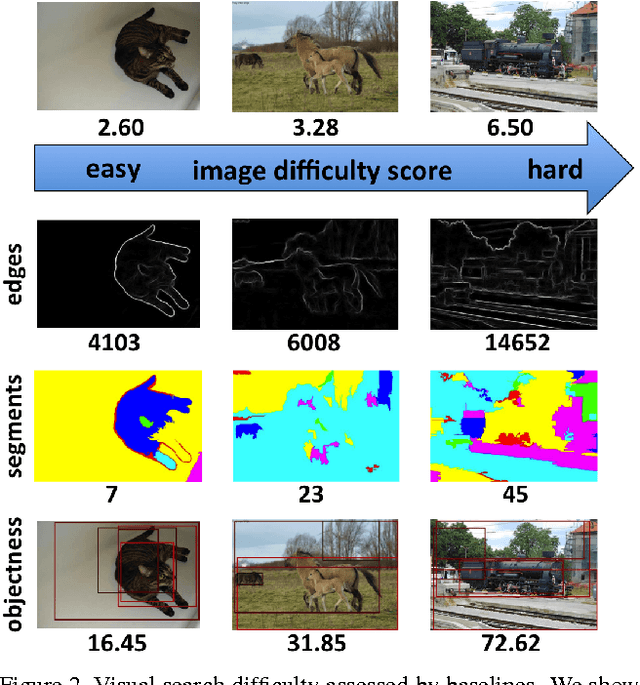
We address the problem of estimating image difficulty defined as the human response time for solving a visual search task. We collect human annotations of image difficulty for the PASCAL VOC 2012 data set through a crowd-sourcing platform. We then analyze what human interpretable image properties can have an impact on visual search difficulty, and how accurate are those properties for predicting difficulty. Next, we build a regression model based on deep features learned with state of the art convolutional neural networks and show better results for predicting the ground-truth visual search difficulty scores produced by human annotators. Our model is able to correctly rank about 75% image pairs according to their difficulty score. We also show that our difficulty predictor generalizes well to new classes not seen during training. Finally, we demonstrate that our predicted difficulty scores are useful for weakly supervised object localization (8% improvement) and semi-supervised object classification (1% improvement).
* Published at CVPR 2016
Training object class detectors with click supervision
May 19, 2017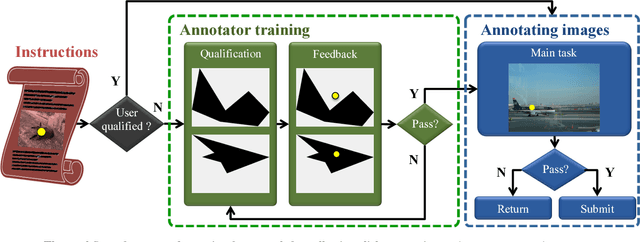


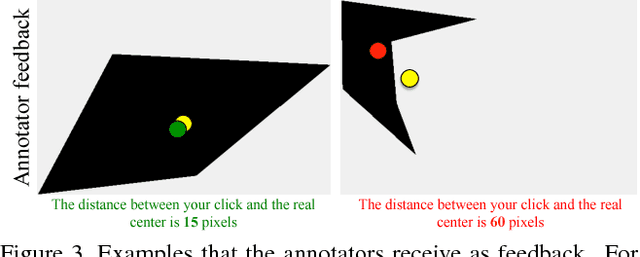
Training object class detectors typically requires a large set of images with objects annotated by bounding boxes. However, manually drawing bounding boxes is very time consuming. In this paper we greatly reduce annotation time by proposing center-click annotations: we ask annotators to click on the center of an imaginary bounding box which tightly encloses the object instance. We then incorporate these clicks into existing Multiple Instance Learning techniques for weakly supervised object localization, to jointly localize object bounding boxes over all training images. Extensive experiments on PASCAL VOC 2007 and MS COCO show that: (1) our scheme delivers high-quality detectors, performing substantially better than those produced by weakly supervised techniques, with a modest extra annotation effort; (2) these detectors in fact perform in a range close to those trained from manually drawn bounding boxes; (3) as the center-click task is very fast, our scheme reduces total annotation time by 9x to 18x.
We don't need no bounding-boxes: Training object class detectors using only human verification
Apr 24, 2017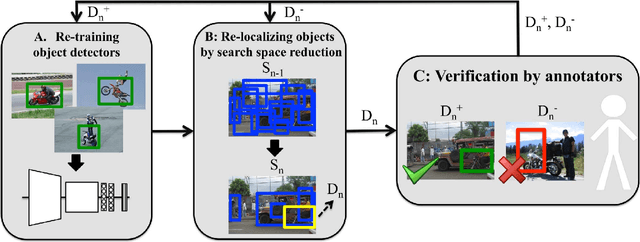
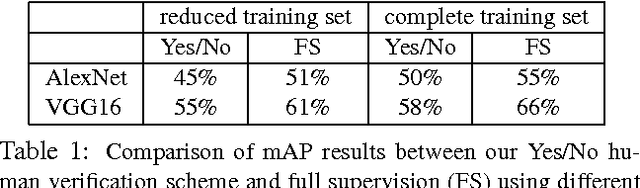


Training object class detectors typically requires a large set of images in which objects are annotated by bounding-boxes. However, manually drawing bounding-boxes is very time consuming. We propose a new scheme for training object detectors which only requires annotators to verify bounding-boxes produced automatically by the learning algorithm. Our scheme iterates between re-training the detector, re-localizing objects in the training images, and human verification. We use the verification signal both to improve re-training and to reduce the search space for re-localisation, which makes these steps different to what is normally done in a weakly supervised setting. Extensive experiments on PASCAL VOC 2007 show that (1) using human verification to update detectors and reduce the search space leads to the rapid production of high-quality bounding-box annotations; (2) our scheme delivers detectors performing almost as good as those trained in a fully supervised setting, without ever drawing any bounding-box; (3) as the verification task is very quick, our scheme substantially reduces total annotation time by a factor 6x-9x.
End-to-end training of object class detectors for mean average precision
Mar 16, 2017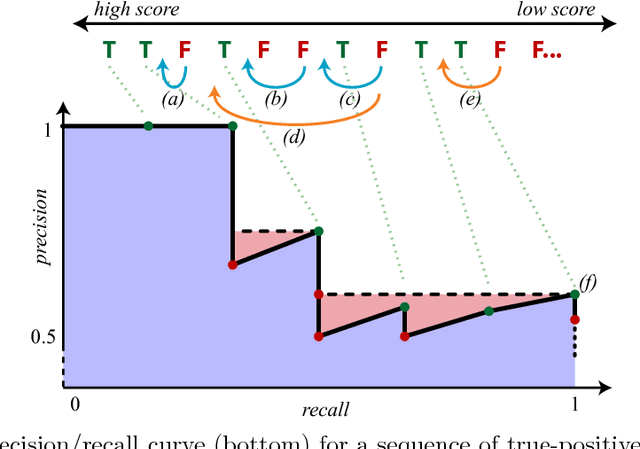
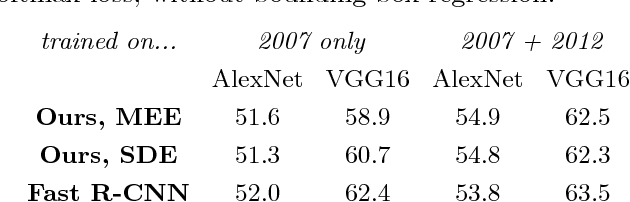
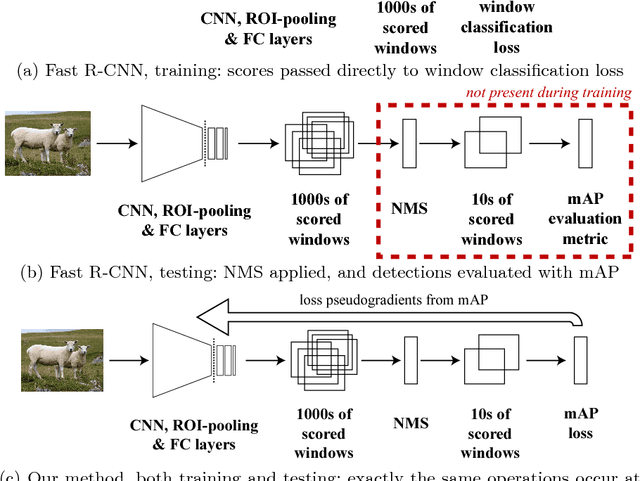
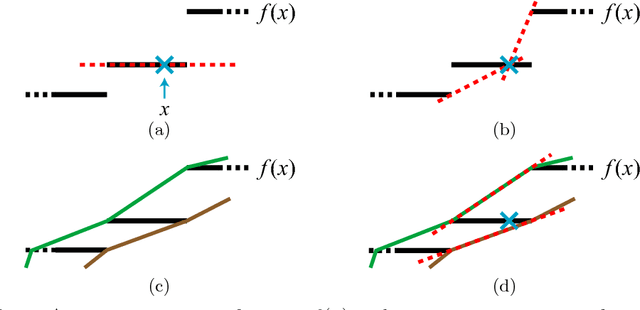
We present a method for training CNN-based object class detectors directly using mean average precision (mAP) as the training loss, in a truly end-to-end fashion that includes non-maximum suppression (NMS) at training time. This contrasts with the traditional approach of training a CNN for a window classification loss, then applying NMS only at test time, when mAP is used as the evaluation metric in place of classification accuracy. However, mAP following NMS forms a piecewise-constant structured loss over thousands of windows, with gradients that do not convey useful information for gradient descent. Hence, we define new, general gradient-like quantities for piecewise constant functions, which have wide applicability. We describe how to calculate these efficiently for mAP following NMS, enabling to train a detector based on Fast R-CNN directly for mAP. This model achieves equivalent performance to the standard Fast R-CNN on the PASCAL VOC 2007 and 2012 datasets, while being conceptually more appealing as the very same model and loss are used at both training and test time.
Recovering Spatiotemporal Correspondence between Deformable Objects by Exploiting Consistent Foreground Motion in Video
Aug 16, 2016

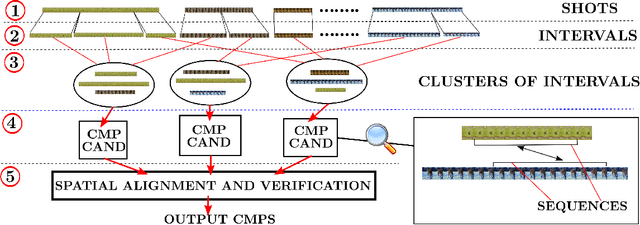
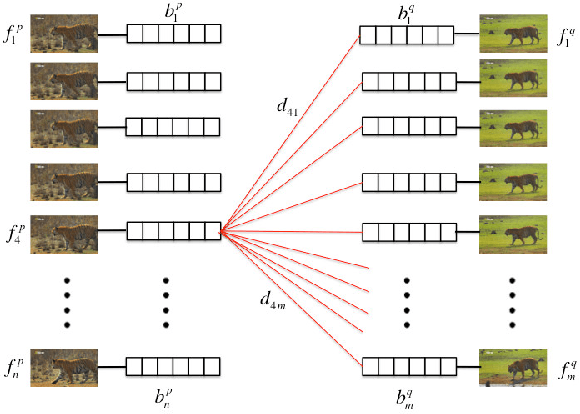
Given unstructured videos of deformable objects, we automatically recover spatiotemporal correspondences to map one object to another (such as animals in the wild). While traditional methods based on appearance fail in such challenging conditions, we exploit consistency in object motion between instances. Our approach discovers pairs of short video intervals where the object moves in a consistent manner and uses these candidates as seeds for spatial alignment. We model the spatial correspondence between the point trajectories on the object in one interval to those in the other using a time-varying Thin Plate Spline deformation model. On a large dataset of tiger and horse videos, our method automatically aligns thousands of pairs of frames to a high accuracy, and outperforms the popular SIFT Flow algorithm.
Weakly Supervised Object Localization Using Size Estimates
Aug 16, 2016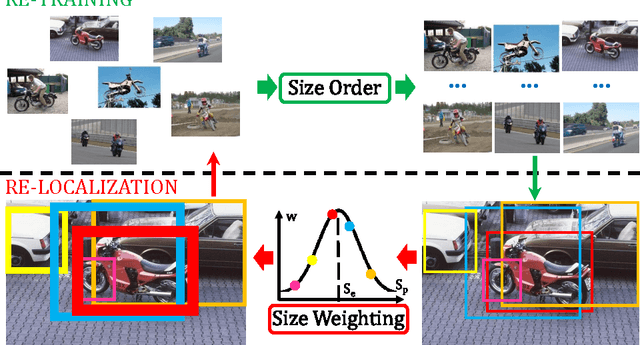
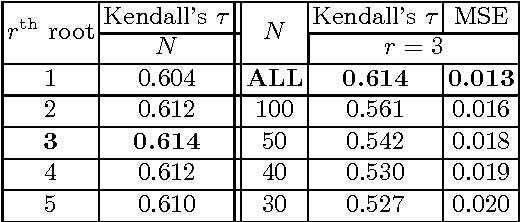

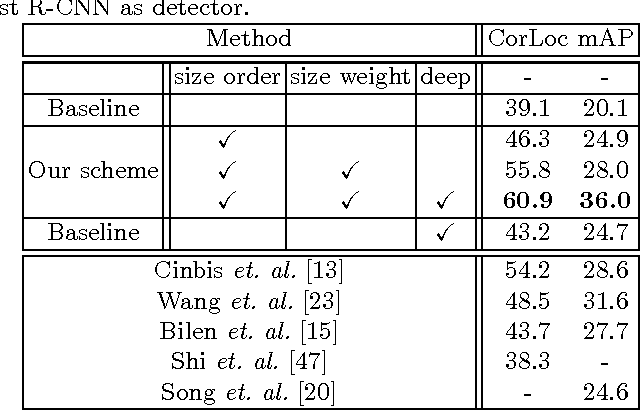
We present a technique for weakly supervised object localization (WSOL), building on the observation that WSOL algorithms usually work better on images with bigger objects. Instead of training the object detector on the entire training set at the same time, we propose a curriculum learning strategy to feed training images into the WSOL learning loop in an order from images containing bigger objects down to smaller ones. To automatically determine the order, we train a regressor to estimate the size of the object given the whole image as input. Furthermore, we use these size estimates to further improve the re-localization step of WSOL by assigning weights to object proposals according to how close their size matches the estimated object size. We demonstrate the effectiveness of using size order and size weighting on the challenging PASCAL VOC 2007 dataset, where we achieve a significant improvement over existing state-of-the-art WSOL techniques.
Behavior Discovery and Alignment of Articulated Object Classes from Unstructured Video
Aug 11, 2016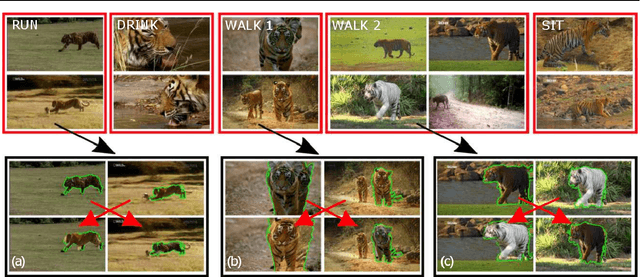
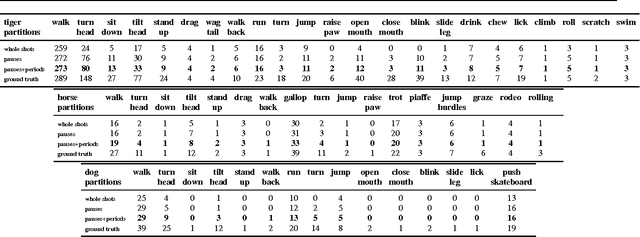
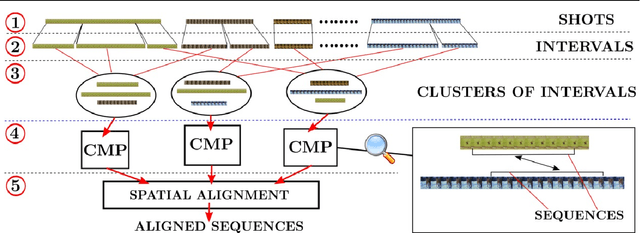
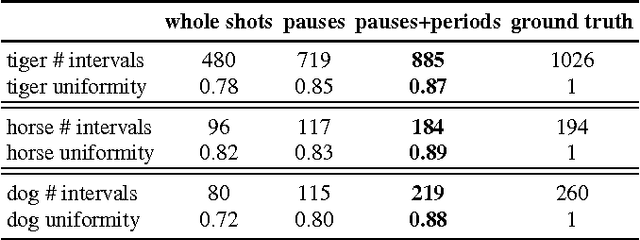
We propose an automatic system for organizing the content of a collection of unstructured videos of an articulated object class (e.g. tiger, horse). By exploiting the recurring motion patterns of the class across videos, our system: 1) identifies its characteristic behaviors; and 2) recovers pixel-to-pixel alignments across different instances. Our system can be useful for organizing video collections for indexing and retrieval. Moreover, it can be a platform for learning the appearance or behaviors of object classes from Internet video. Traditional supervised techniques cannot exploit this wealth of data directly, as they require a large amount of time-consuming manual annotations. The behavior discovery stage generates temporal video intervals, each automatically trimmed to one instance of the discovered behavior, clustered by type. It relies on our novel motion representation for articulated motion based on the displacement of ordered pairs of trajectories (PoTs). The alignment stage aligns hundreds of instances of the class to a great accuracy despite considerable appearance variations (e.g. an adult tiger and a cub). It uses a flexible Thin Plate Spline deformation model that can vary through time. We carefully evaluate each step of our system on a new, fully annotated dataset. On behavior discovery, we outperform the state-of-the-art Improved DTF descriptor. On spatial alignment, we outperform the popular SIFT Flow algorithm.
* 19 pages, 19 figure, 3 tables. arXiv admin note: substantial text overlap with arXiv:1411.7883