 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating LLM Agent Collusion in Double Auctions
Jul 02, 2025



Large language models (LLMs) have demonstrated impressive capabilities as autonomous agents with rapidly expanding applications in various domains. As these agents increasingly engage in socioeconomic interactions, identifying their potential for undesirable behavior becomes essential. In this work, we examine scenarios where they can choose to collude, defined as secretive cooperation that harms another party. To systematically study this, we investigate the behavior of LLM agents acting as sellers in simulated continuous double auction markets. Through a series of controlled experiments, we analyze how parameters such as the ability to communicate, choice of model, and presence of environmental pressures affect the stability and emergence of seller collusion. We find that direct seller communication increases collusive tendencies, the propensity to collude varies across models, and environmental pressures, such as oversight and urgency from authority figures, influence collusive behavior. Our findings highlight important economic and ethical considerations for the deployment of LLM-based market agents.
Socioeconomic disparities and COVID-19: the causal connections
Jan 18, 2022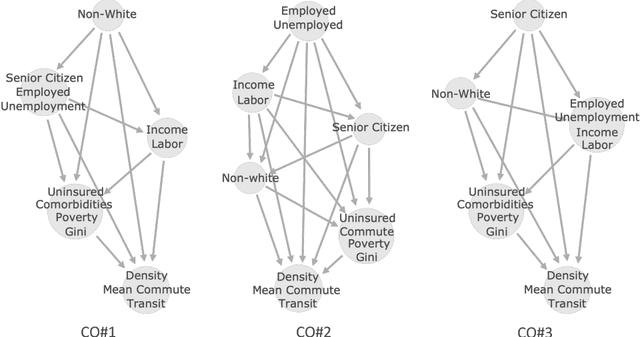
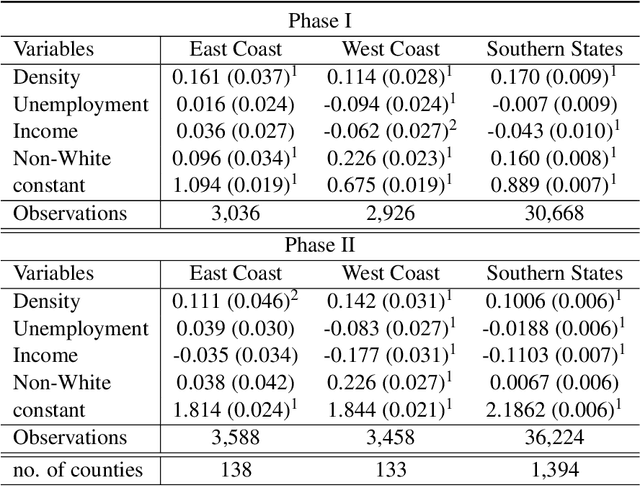
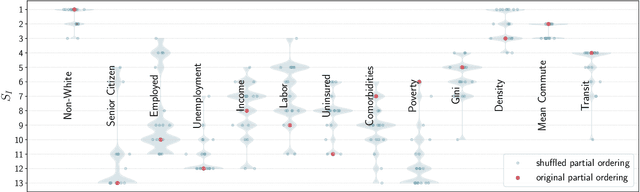
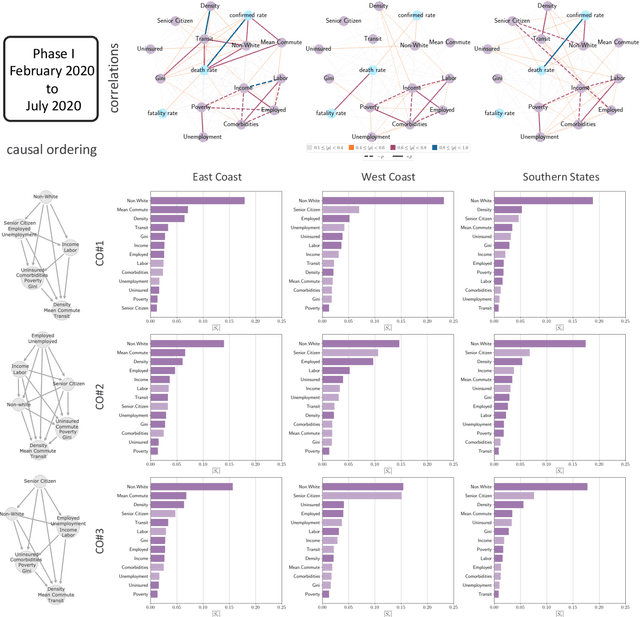
The analysis of causation is a challenging task that can be approached in various ways. With the increasing use of machine learning based models in computational socioeconomics, explaining these models while taking causal connections into account is a necessity. In this work, we advocate the use of an explanatory framework from cooperative game theory augmented with $do$ calculus, namely causal Shapley values. Using causal Shapley values, we analyze socioeconomic disparities that have a causal link to the spread of COVID-19 in the USA. We study several phases of the disease spread to show how the causal connections change over time. We perform a causal analysis using random effects models and discuss the correspondence between the two methods to verify our results. We show the distinct advantages a non-linear machine learning models have over linear models when performing a multivariate analysis, especially since the machine learning models can map out non-linear correlations in the data. In addition, the causal Shapley values allow for including the causal structure in the variable importance computed for the machine learning model.