 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Just Pay Attention, PLANT It: Transfer L2R Models to Fine-tune Attention in Extreme Multi-Label Text Classification
Oct 30, 2024



State-of-the-art Extreme Multi-Label Text Classification (XMTC) models rely heavily on multi-label attention layers to focus on key tokens in input text, but obtaining optimal attention weights is challenging and resource-intensive. To address this, we introduce PLANT -- Pretrained and Leveraged AtteNTion -- a novel transfer learning strategy for fine-tuning XMTC decoders. PLANT surpasses existing state-of-the-art methods across all metrics on mimicfull, mimicfifty, mimicfour, eurlex, and wikiten datasets. It particularly excels in few-shot scenarios, outperforming previous models specifically designed for few-shot scenarios by over 50 percentage points in F1 scores on mimicrare and by over 36 percentage points on mimicfew, demonstrating its superior capability in handling rare codes. PLANT also shows remarkable data efficiency in few-shot scenarios, achieving precision comparable to traditional models with significantly less data. These results are achieved through key technical innovations: leveraging a pretrained Learning-to-Rank model as the planted attention layer, integrating mutual-information gain to enhance attention, introducing an inattention mechanism, and implementing a stateful-decoder to maintain context. Comprehensive ablation studies validate the importance of these contributions in realizing the performance gains.
A Complex KBQA System using Multiple Reasoning Paths
May 22, 2020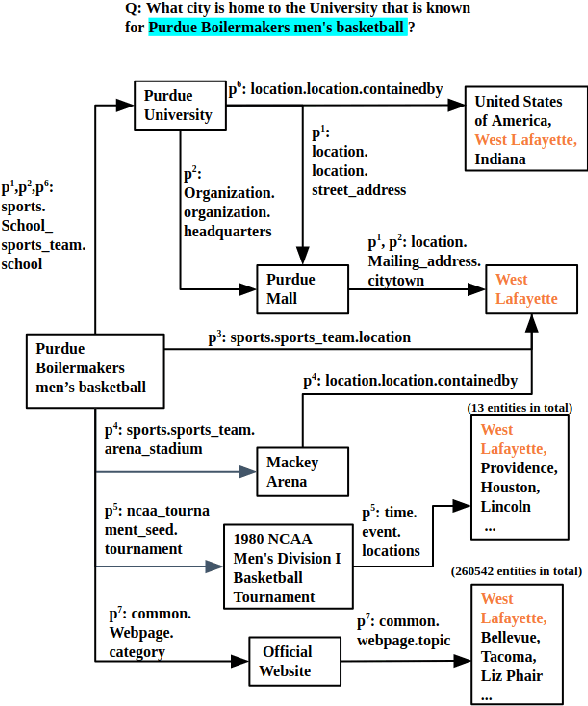
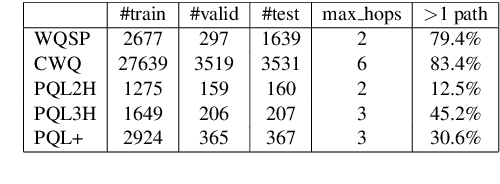
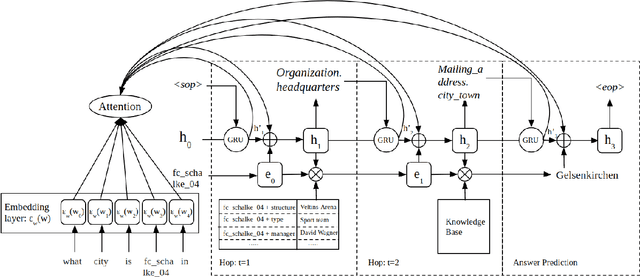
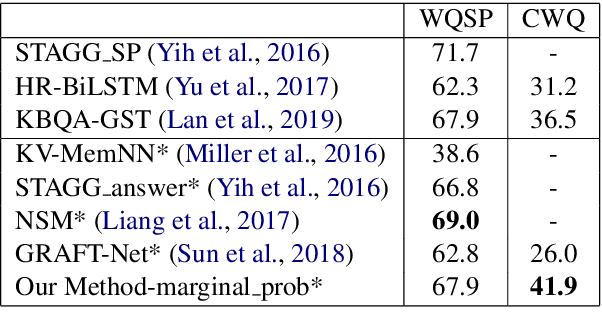
Multi-hop knowledge based question answering (KBQA) is a complex task for natural language understanding. Many KBQA approaches have been proposed in recent years, and most of them are trained based on labeled reasoning path. This hinders the system's performance as many correct reasoning paths are not labeled as ground truth, and thus they cannot be learned. In this paper, we introduce an end-to-end KBQA system which can leverage multiple reasoning paths' information and only requires labeled answer as supervision. We conduct experiments on several benchmark datasets containing both single-hop simple questions as well as muti-hop complex questions, including WebQuestionSP (WQSP), ComplexWebQuestion-1.1 (CWQ), and PathQuestion-Large (PQL), and demonstrate strong performance.
Adapting RNN Sequence Prediction Model to Multi-label Set Prediction
Apr 11, 2019
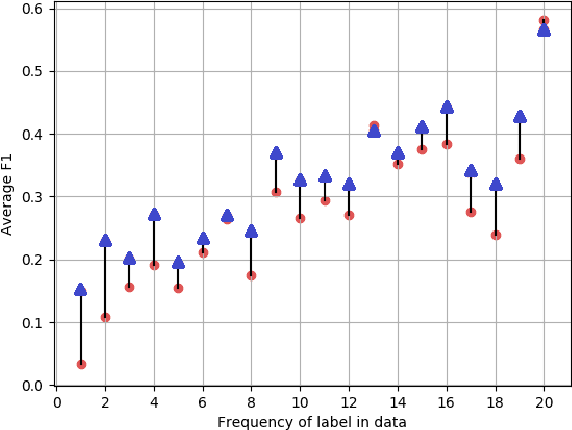
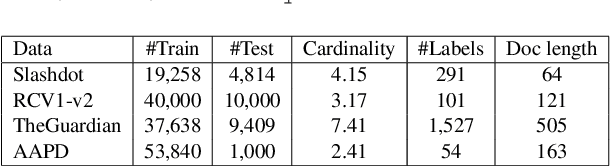
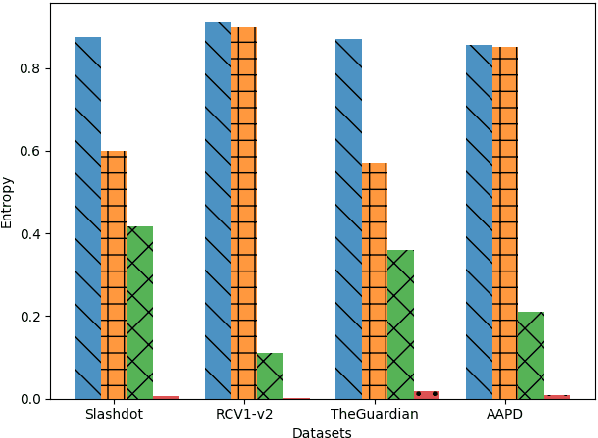
We present an adaptation of RNN sequence models to the problem of multi-label classification for text, where the target is a set of labels, not a sequence. Previous such RNN models define probabilities for sequences but not for sets; attempts to obtain a set probability are after-thoughts of the network design, including pre-specifying the label order, or relating the sequence probability to the set probability in ad hoc ways. Our formulation is derived from a principled notion of set probability, as the sum of probabilities of corresponding permutation sequences for the set. We provide a new training objective that maximizes this set probability, and a new prediction objective that finds the most probable set on a test document. These new objectives are theoretically appealing because they give the RNN model freedom to discover the best label order, which often is the natural one (but different among documents). We develop efficient procedures to tackle the computation difficulties involved in training and prediction. Experiments on benchmark datasets demonstrate that we outperform state-of-the-art methods for this task.
Measuring Human-perceived Similarity in Heterogeneous Collections
Feb 16, 2018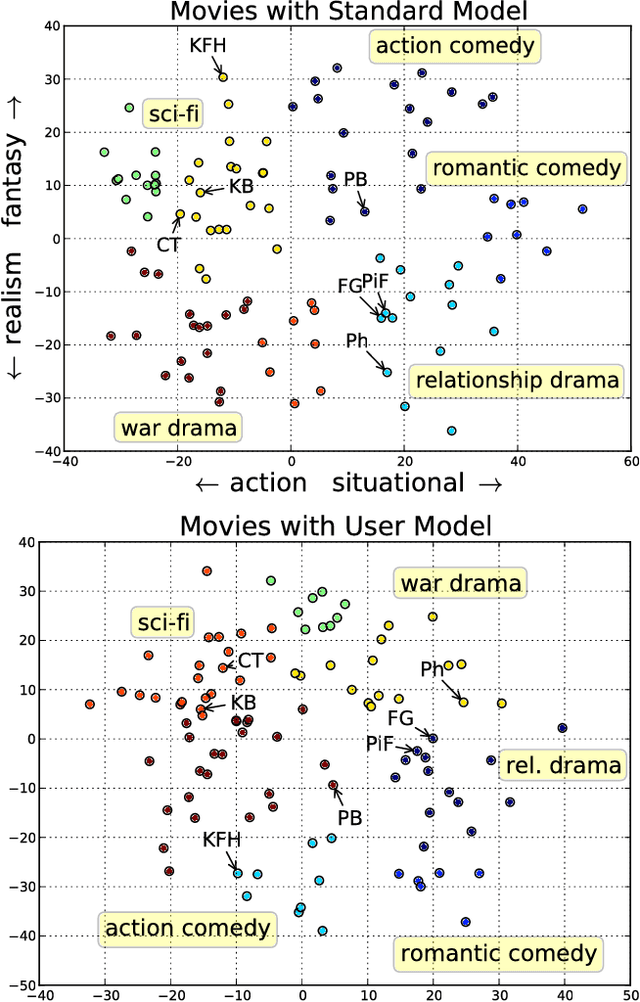


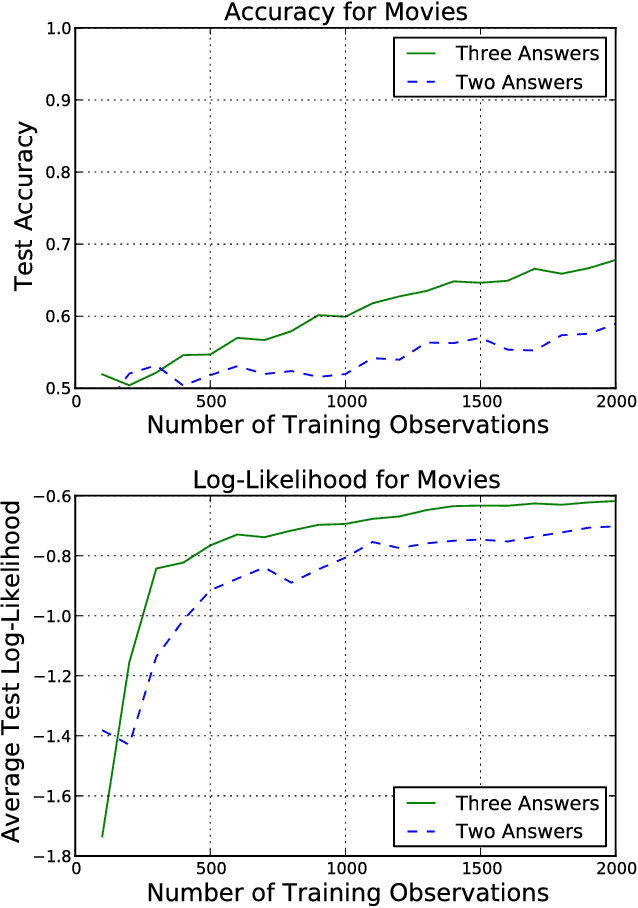
We present a technique for estimating the similarity between objects such as movies or foods whose proper representation depends on human perception. Our technique combines a modest number of human similarity assessments to infer a pairwise similarity function between the objects. This similarity function captures some human notion of similarity which may be difficult or impossible to automatically extract, such as which movie from a collection would be a better substitute when the desired one is unavailable. In contrast to prior techniques, our method does not assume that all similarity questions on the collection can be answered or that all users perceive similarity in the same way. When combined with a user model, we find how each assessor's tastes vary, affecting their perception of similarity.
Regularizing Model Complexity and Label Structure for Multi-Label Text Classification
May 01, 2017
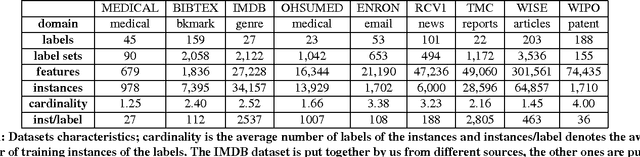
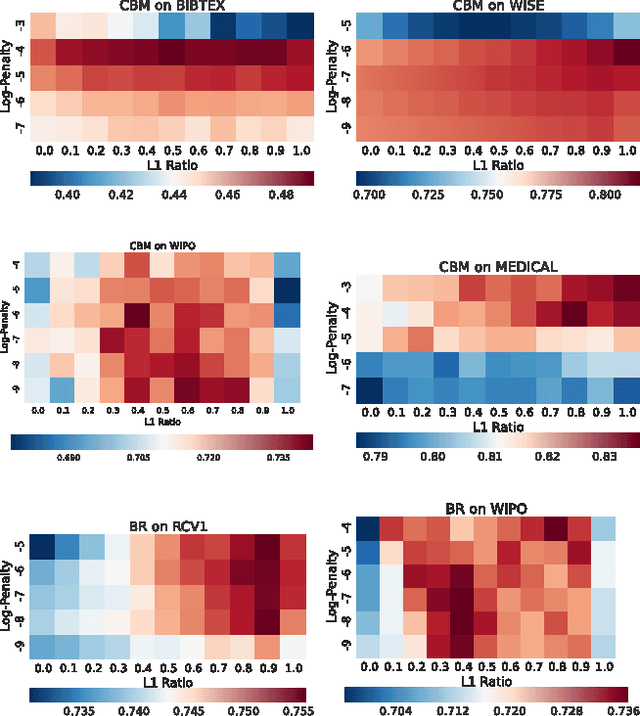
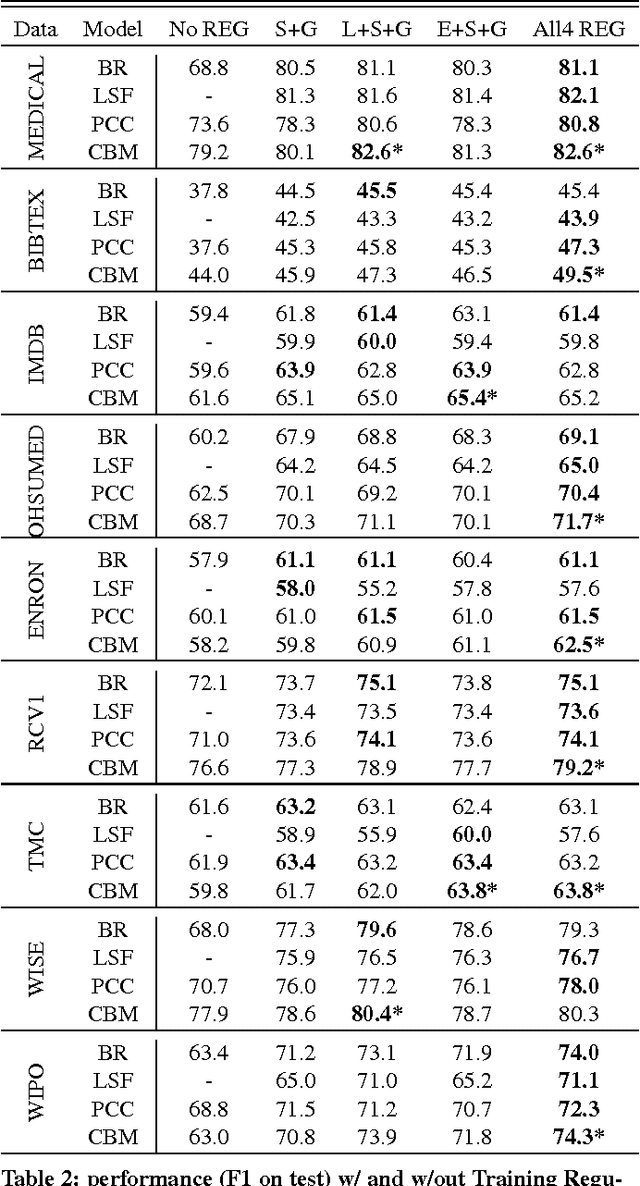
Multi-label text classification is a popular machine learning task where each document is assigned with multiple relevant labels. This task is challenging due to high dimensional features and correlated labels. Multi-label text classifiers need to be carefully regularized to prevent the severe over-fitting in the high dimensional space, and also need to take into account label dependencies in order to make accurate predictions under uncertainty. We demonstrate significant and practical improvement by carefully regularizing the model complexity during training phase, and also regularizing the label search space during prediction phase. Specifically, we regularize the classifier training using Elastic-net (L1+L2) penalty for reducing model complexity/size, and employ early stopping to prevent overfitting. At prediction time, we apply support inference to restrict the search space to label sets encountered in the training set, and F-optimizer GFM to make optimal predictions for the F1 metric. We show that although support inference only provides density estimations on existing label combinations, when combined with GFM predictor, the algorithm can output unseen label combinations. Taken collectively, our experiments show state of the art results on many benchmark datasets. Beyond performance and practical contributions, we make some interesting observations. Contrary to the prior belief, which deems support inference as purely an approximate inference procedure, we show that support inference acts as a strong regularizer on the label prediction structure. It allows the classifier to take into account label dependencies during prediction even if the classifiers had not modeled any label dependencies during training.