 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOntology Verbalization using Semantic-Refinement
Oct 31, 2016

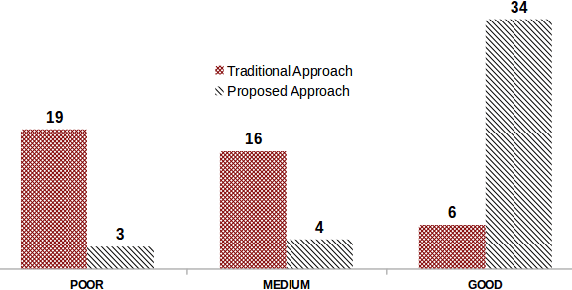
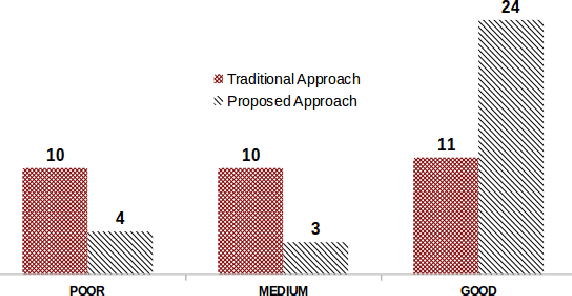
We propose a rule-based technique to generate redundancy-free NL descriptions of OWL entities.The existing approaches which address the problem of verbalizing OWL ontologies generate NL text segments which are close to their counterpart OWL statements.Some of these approaches also perform grouping and aggregating of these NL text segments to generate a more fluent and comprehensive form of the content.Restricting our attention to description of individuals and concepts, we find that the approach currently followed in the available tools is that of determining the set of all logical conditions that are satisfied by the given individual/concept name and translate these conditions verbatim into corresponding NL descriptions.Human-understandability of such descriptions is affected by the presence of repetitions and redundancies, as they have high fidelity to their OWL representation.In the literature, no efforts had been taken to remove redundancies and repetitions at the logical-level before generating the NL descriptions of entities and we find this to be the main reason for lack of readability of the generated text.Herein, we propose a technique called semantic-refinement(SR) to generate meaningful and easily-understandable descriptions of individuals and concepts of a given OWLontology.We identify the combinations of OWL/DL constructs that lead to repetitive/redundant descriptions and propose a series of refinement rules to rewrite the conditions that are satisfied by an individual/concept in a meaning-preserving manner.The reduced set of conditions are then employed for generating NL descriptions.Our experiments show that, SR leads to significantly improved descriptions of ontology entities.We also test the effectiveness and usefulness of the the generated descriptions for the purpose of validating the ontologies and find that the proposed technique is indeed helpful in the context.
Modeling of Item-Difficulty for Ontology-based MCQs
Jul 04, 2016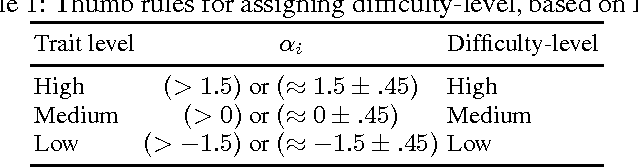
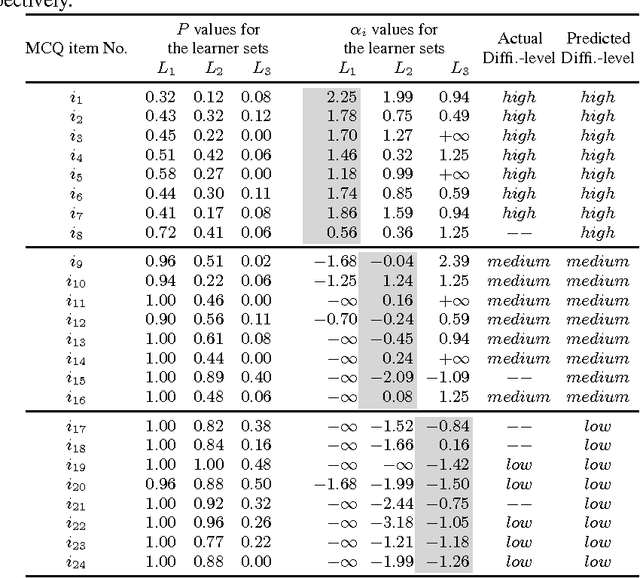
Multiple choice questions (MCQs) that can be generated from a domain ontology can significantly reduce human effort & time required for authoring & administering assessments in an e-Learning environment. Even though here are various methods for generating MCQs from ontologies, methods for determining the difficulty-levels of such MCQs are less explored. In this paper, we study various aspects and factors that are involved in determining the difficulty-score of an MCQ, and propose an ontology-based model for the prediction. This model characterizes the difficulty values associated with the stem and choice set of the MCQs, and describes a measure which combines both the scores. Further more, the notion of assigning difficultly-scores based on the skill level of the test taker is utilized for predicating difficulty-score of a stem. We studied the effectiveness of the predicted difficulty-scores with the help of a psychometric model from the Item Response Theory, by involving real-students and domain experts. Our results show that, the predicated difficulty-levels of the MCQs are having high correlation with their actual difficulty-levels.